NeuralRecon拜读:单目视频实时连贯三维重建
Posted 人工智睿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NeuralRecon拜读:单目视频实时连贯三维重建相关的知识,希望对你有一定的参考价值。
CVPR2021:NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video
Code:https://github.com/zju3dv/NeuralRecon
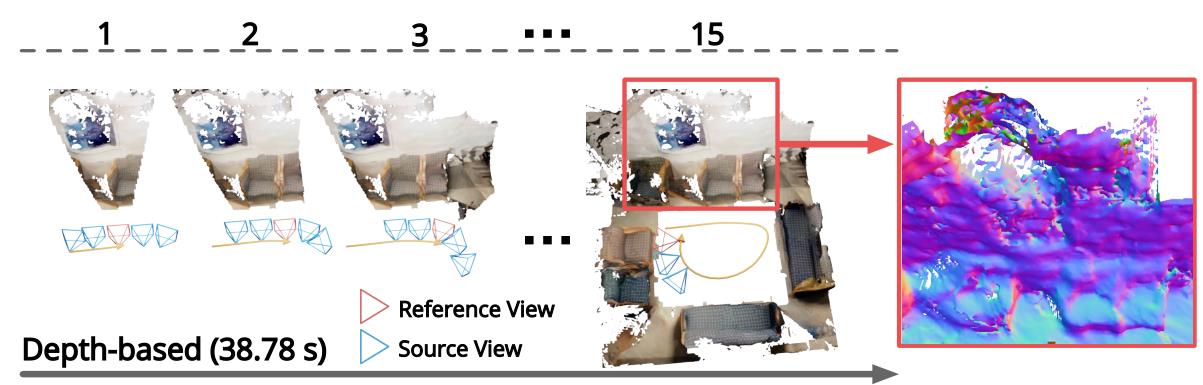
传统基于深度图重建方法:
- depth map转换为point clouds
- 估计三维曲面位置并生成重建的网格
- 在离线MVS pipline中,常使用Poisson reconstruction 和Delaunay triagulation 通常用于实现这一目的。
基于TSDF的深度图融合方法:
- 估计的深度图使用多视图一致性和时间平滑度等标准进行过滤
- 融合为TSDF volumes
- 利用MarchingCubes算法将融合后的TSDF volumes重建mesh
存在的问题:
- 单视图深度估计scale-factor容易变,不同视图的深度不一致,使得重建分层或者分散
- 多帧视图重叠区域的冗余重建计算
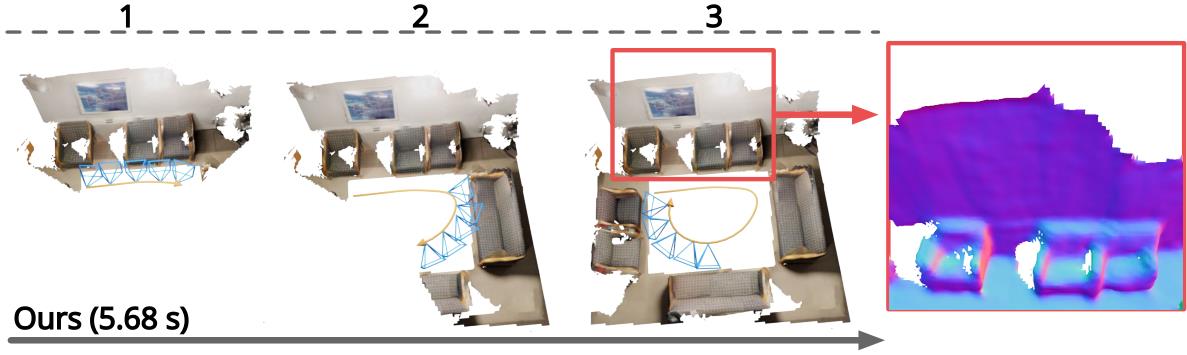
NeuralRecon的方案:
- 通过神经网络为每个视频片段直接生成TSDF volumes
- 然后使用基于gated recurrent units的TSDF融合模块引导网络融合前后片段
这种设计允许网络在顺序重建曲面时捕获3D曲面的局部平滑度先验和全局形状先验,从而实现精确、一致和实时的曲面重建
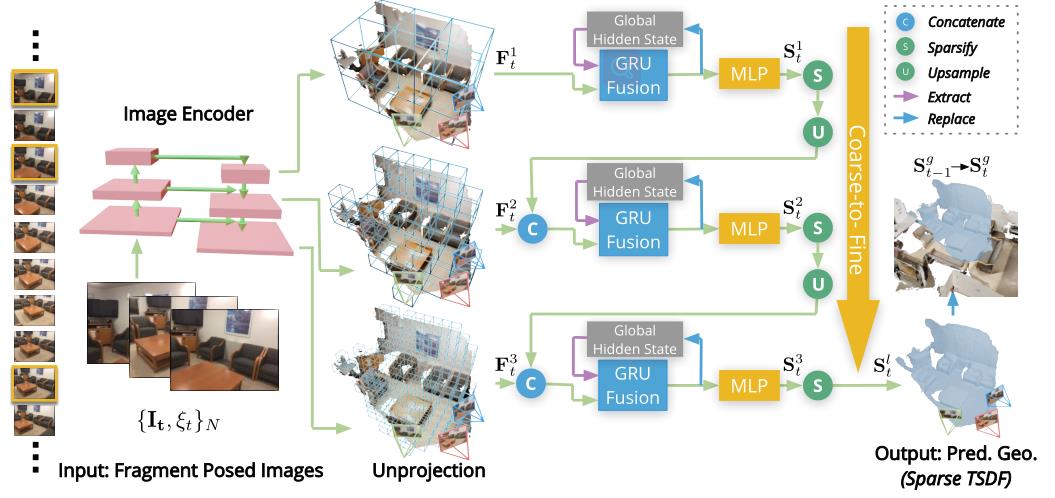
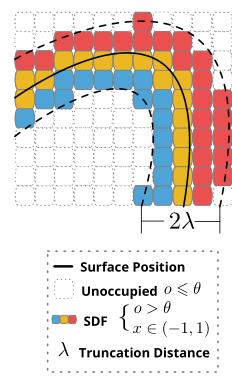
理论基础:Truncated Signed Distance Function (TSDF) volume
使用稀疏3D卷积预测离散TSDF volume
重建方法的前提:
- 输入:已知图像和对应的内外参
- 监督:
- binary cross-entropy (BCE) loss: ground-truth occupancy values
- SDF loss: ground-truth SDF values.
关键帧选择:
- 当新传入帧的相对平移大于 t m a x t_max tmax且相对旋转角大于 R m a x R_max Rmax,则选择该帧作为关键帧
- 每N个关键帧视为local fragment
- 基于视图中固定的最大深度范围 d m a x d_max dmax(文中为3m)计算包围所有关键帧视锥体的立方形fragment bounding volume (FBV)
- 在重建每个fragment时,只考虑FBV内的区域
边重建边融合:
- 重建local fragment局部的TSDF volumes
- 使用学习的方法将局部TSDF融入全局TSDF volumes
Feature volume构建:
- ImageNet预训练的MnasNet_encoder提取feature
- 各级feature反投影到3D feature volume
- feature volume按体素可见性权重融合不同视图的feature:
- 体素可见性权重为local fragment中可以观察到体素的视图数
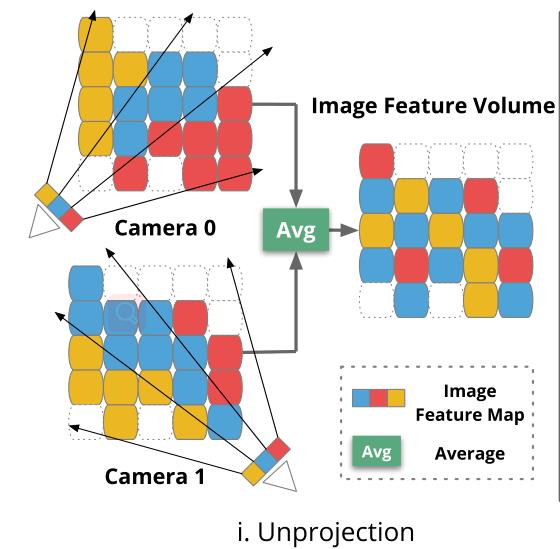
- 体素可见性权重为local fragment中可以观察到体素的视图数
Coarse-to-fine的TSDF重建,逐步细化各层TSDF
-
3D sparse convolution(TorchSpase)处理3D feature volume
-
MLP sigmoid预测TSDF截断距离λ的置信度 o o o 和 SDF-value x x x
- o o o 小于阈值视为空,稀疏化
-
稀疏化后将TSDF volume上采样并级联下一层的feature
-
通过GRU Fusion 模块
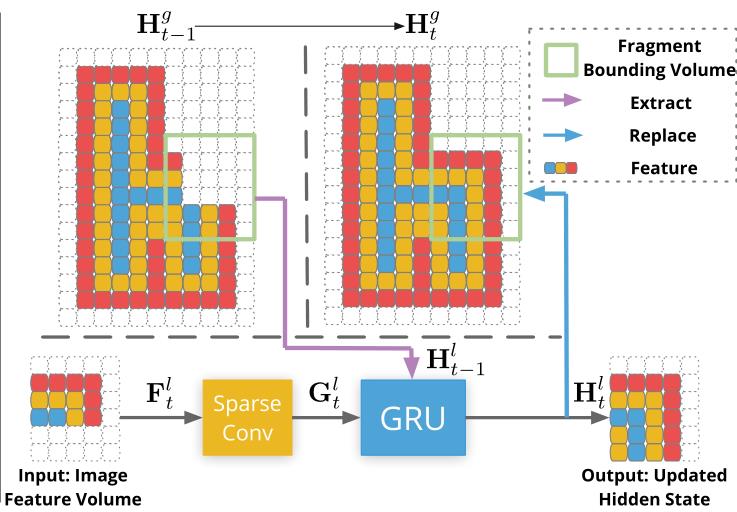
GRU Fusion模块:
为了保证相邻fragment重建的一致性,以过去fragment为基础
- 在每一层feature volume通过sparse 3D conv获得3D geometric features
- 将该3D geometric features与全局volume对应区域融合成当前的参数volume
- 再将当前参数volume更新回全局volume
- 当前参数体通过MLP得到当前TSDF volume
- 更新Global TSDF Volume在最后一层的GRU模块完成
实验用的是有ground truth的室内数据集,效果如下: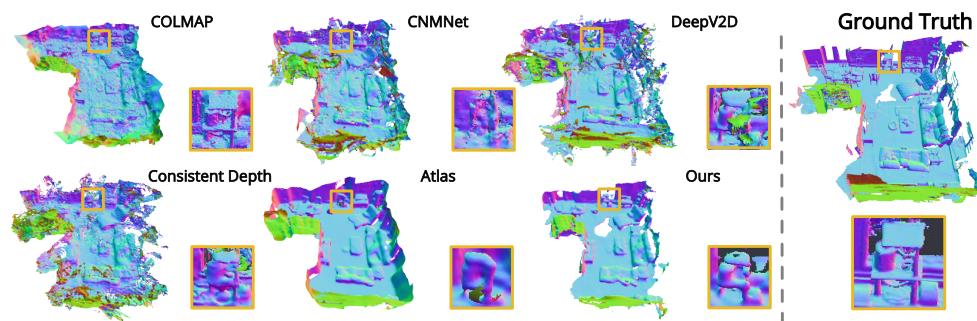
以上是关于NeuralRecon拜读:单目视频实时连贯三维重建的主要内容,如果未能解决你的问题,请参考以下文章