音频重采样
Posted 生椰_李点点
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了音频重采样相关的知识,希望对你有一定的参考价值。
重点问题
- 如何进行重采样
- 采样率不⼀样的时候pts怎么处理
官方参考文档:http://ffmpeg.org/doxygen/trunk/group__lswr.html
重采样
什么是重采样
所谓的重采样,就是改变音频的采样率、sample format、声道数等参数,使之按照我们期望的参数输出
为什么要重采样
为什么要重采样?当然是原有的音频参数不满足我们的需求
- 比如在FFmpeg解码音频的时候,不同的音源有不同的格式,采样率等,在解码后的数据中的这些参数也会不一致(最新FFmpeg 解码音频后,音频格式为AV_SAMPLE_FMT_FLTP,这个参数应该是⼀致的),如果我们接下来需要使用解码后的音频数据做 其他操作,而这些参数的不一致导致会有很多额外工作,此时直接对其进行重采样,获取我们制定的音频参数,这样就会方便很多。
- 再比如如在将音频进行SDL播放时候,因为当前的SDL2.0不支持planar格式,也不支持浮点型的,而最新的 FFMPEG 16年会将音频解码为AV_SAMPLE_FMT_FLTP格式,因此此时就需要我们对其重采样,使之可以在SDL2.0上进行播放。
可调节的参数
通过重采样,我们可以对:
- sample rate(采样率)
- sample format(采样格式)
- channel layout(通道布局,可以通过此参数获取声道数
对应参数解析
采样率
采样设备每秒抽取样本的次数
采样格式及量化精度(位宽)
每种音频格式有不同的量化精度(位宽),位数越多,表示值就越精确,声音表现自然就越精准。 FFMpeg中音频格式有以下几种,每种格式有其占用的字节数信息(libavutil/samplefmt.h):
enum AVSampleFormat
AV_SAMPLE_FMT_NONE = -1,
AV_SAMPLE_FMT_U8, ///< unsigned 8 bits
AV_SAMPLE_FMT_S16, ///< signed 16 bits
AV_SAMPLE_FMT_S32, ///< signed 32 bits
AV_SAMPLE_FMT_FLT, ///< float
AV_SAMPLE_FMT_DBL, ///< double
AV_SAMPLE_FMT_U8P, ///< unsigned 8 bits, planar
AV_SAMPLE_FMT_S16P, ///< signed 16 bits, planar
AV_SAMPLE_FMT_S32P, ///< signed 32 bits, planar
AV_SAMPLE_FMT_FLTP, ///< float, planar
AV_SAMPLE_FMT_DBLP, ///< double, planar
AV_SAMPLE_FMT_S64, ///< signed 64 bits
AV_SAMPLE_FMT_S64P, ///< signed 64 bits, planar
AV_SAMPLE_FMT_NB ///< Number of sample formats. DO NOT USE if linking dynamically
;
分片(plane)和打包(packed)
以双声道为例,
带P(plane)的数据格式在存储时,其左声道和右声道的数据是分开存储的,左声道的 数据存储在data[0],右声道的数据存储在data[1],每个声道的所占⽤的字节数为linesize[0]和 linesize[1];
不带P(packed)的⾳频数据在存储时,是按照LRLRLR…的格式交替存储在data[0]中,linesize[0] 表示总的数据量。
声道分布(channel_layout)
声道分布在FFmpeg\\libavutil\\channel_layout.h中有定义,⼀般来说用的比较多的是AV_CH_LAYOUT_STEREO(双声道)和AV_CH_LAYOUT_SURROUND(三声道),这两者的定义如下:
#define AV_CH_LAYOUT_STEREO (AV_CH_FRONT_LEFT|AV_CH_FRONT_RIGHT)
#define AV_CH_LAYOUT_SURROUND (AV_CH_LAYOUT_STEREO|AV_CH_FRONT_CENTER)
音频帧的数据量计算
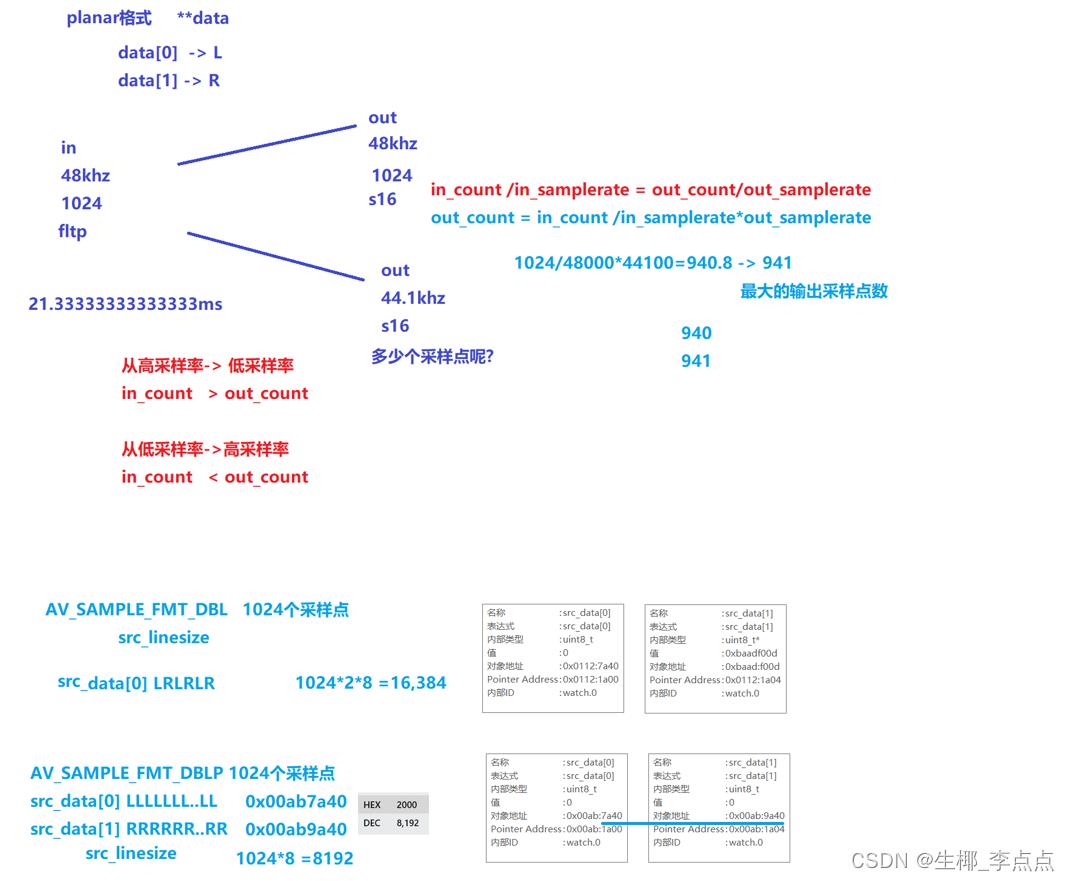
⼀帧⾳频的数据量(字节)=channel数 * nb_samples样本数 * 每个样本占用的字节数
如果该音频帧是FLTP格式的PCM数据,包含1024个样本,双声道,那么该音频帧包含的音频数据量是
210244=8192字节。
AV_SAMPLE_FMT_DBL : 210248 = 16384
音频播放时间计算
以采样率44100Hz来计算,每秒44100个sample,⽽正常⼀帧为1024个sample,可知每帧播放时 间/1024=1000ms/44100,得到每帧播放时间=1024*1000/44100=23.2ms (更精确的是 23.21995464852608
⼀帧播放时间(毫秒) = nb_samples样本数 *1000/采样率 =
- 1024*1000/44100=23.21995464852608ms ->约等于 23.2ms,精度损失了 0.011995464852608ms,如果累计10万帧,误差>1199毫秒,如果有视频⼀起的就会有⾳视频同步的问 题。 如果按着23.2去计算pts(0 23.2 46.4 )就会有累积误差。
- 1024*1000/48000=21.33333333333333ms
FFmpeg重采样API
分配音频重采样的上下文
struct SwrContext *swr_alloc(void);
当设置好相关的参数后,使⽤此函数来初始化SwrContext结构体
int swr_init(struct SwrContext *s);
分配SwrContext并设置/重置常⽤的参数
struct SwrContext *swr_alloc_set_opts(struct SwrContext *s,// ⾳频重采样上下⽂
int64_t out_ch_layout, // 输出的layout, 如:5.1声道
enum AVSampleFormat out_sample_fmt,// 输出的采样格式。Float, S16,⼀般 选⽤是s16 绝⼤部分声卡⽀持
int out_sample_rate,//输出采样率
int64_t in_ch_layout, // 输⼊的layout
enum AVSampleFormat in_sample_fmt, // 输⼊的采样格式
int in_sample_rate,// 输⼊的采样率
int log_offset, // ⽇志相关,不⽤管先,直接为0
void *log_ctx // ⽇志相关,不⽤管先,直接为NULL
);
将输⼊的音频按照定义的参数进进转换并输出
int attribute_align_arg swr_convert(struct SwrContext *s, // ⾳频重采样的上下⽂
uint8_t *out_arg[SWR_CH_MAX], // 输出的指针。传递的输出的数组
int out_count,//输出的样本数量,不是字节数。单通道的样本数量。
const uint8_t *in_arg [SWR_CH_MAX], //输⼊的数组,AVFrame解码出来的DATA
int in_count// 输⼊的单通道的样本数量。
);
返回值 <= out_count in和in_count可以设置为0,以最后刷新最后⼏个样本。
释放掉SwrContext结构体并将此结构体置为NULL;
void swr_free(struct SwrContext **s);
音频频重采样,采样格式转换和混合库。
与lswr的交互是通过SwrContext完成的,SwrContext被分配给swr_alloc()或 swr_alloc_set_opts()。 它是不透明的,所以所有参数必须使⽤AVOptions API设置。 为了使⽤lswr,你需要做的第⼀件事就是分配SwrContext。 这可以使⽤swr_alloc()或 swr_alloc_set_opts()来完成。 如果您使⽤前者,则必须通过AVOptions API设置选项。 后⼀个函数 提供了相同的功能,但它允许您在同⼀语句中设置⼀些常⽤选项。
例如,以下代码将设置从平面浮动样本格式到交织的带符号16位整数的转换,从48kHz到44.1kHz的下采 样,以及从5.1声道到⽴体声的下混合(使⽤默认混合矩阵)。 这是使⽤swr_alloc()函数。
SwrContext *swr = swr_alloc();
av_opt_set_channel_layout(swr, "in_channel_layout", AV_CH_LAYOUT_ 5POINT1, 0);
av_opt_set_channel_layout(swr, "out_channel_layout", AV_CH_LAYOUT_ STEREO, 0);
av_opt_set_int(swr, "in_sample_rate", 48000, 0) ;
av_opt_set_int(swr, "out_sample_rate", 44100, 0) ;
av_opt_set_sample_fmt(swr, "in_sample_fmt", AV_SAMPLE_FMT_FLTP, 0 );
av_opt_set_sample_fmt(swr, "out_sample_fmt", AV_SAMPLE_FMT_S16, 0 );
同样的工作也可以使⽤swr_alloc_set_opts():
SwrContext *swr_alloc_set_opts(NULL,// we're allocating a new context
AV_CH_LAYOUT_STEREO, // out_ch_layout
AV_SAMPLE_FMT_S16, // out_sample_fmt
44100, // out_sample_rate
AV_CH_LAYOUT_5POINT1, // in_ch_layout
AV_SAMPLE_FMT_FLTP, // in_sample_fmt
48000, // in_sample_rate
0, // log_offset
NULL// log_ctx
);
⼀旦设置了所有值,它必须⽤swr_init()初始化。 如果需要更改转换参数,可以使⽤ AVOptions来更改参数,如上面第⼀个例子所述; 或者使⽤swr_alloc_set_opts(),但是第 ⼀个参数是分配的上下文。 您必须再次调用swr_init()。
转换本身通过重复调用swr_convert()来完成。 请注意,如果提供的输出空间不足或采样率转换完成 后,样本可能会在swr中缓冲,这需要“未来”样本。 可以随时通过使⽤swr_convert()(in_count可以 设置为0)来检索不需要将来输⼊的样本。 在转换结束时,可以通过调⽤具有NULL in和in incount的 swr_convert()来刷新重采样缓冲区。
音频重采样工程范例
简单范例(resample)
FFMpeg⾃带的resample例⼦:FFmpeg\\doc\\examples\\resampling_audio.c,这里把最核心的 resample代码贴⼀下,在工程中使用时,注意设置的各种参数,给定的输⼊数据都不能错。
/**
* @example resampling_audio.c
* libswresample API use example.
*/
#include <libavutil/opt.h>
#include <libavutil/channel_layout.h>
#include <libavutil/samplefmt.h>
#include <libswresample/swresample.h>
static int get_format_from_sample_fmt(const char **fmt,
enum AVSampleFormat sample_fmt)
int i;
struct sample_fmt_entry
enum AVSampleFormat sample_fmt; const char *fmt_be, *fmt_le;
sample_fmt_entries[] =
AV_SAMPLE_FMT_U8, "u8", "u8" ,
AV_SAMPLE_FMT_S16, "s16be", "s16le" ,
AV_SAMPLE_FMT_S32, "s32be", "s32le" ,
AV_SAMPLE_FMT_FLT, "f32be", "f32le" ,
AV_SAMPLE_FMT_DBL, "f64be", "f64le" ,
;
*fmt = NULL;
for (i = 0; i < FF_ARRAY_ELEMS(sample_fmt_entries); i++)
struct sample_fmt_entry *entry = &sample_fmt_entries[i];
if (sample_fmt == entry->sample_fmt)
*fmt = AV_NE(entry->fmt_be, entry->fmt_le);
return 0;
fprintf(stderr,
"Sample format %s not supported as output format\\n",
av_get_sample_fmt_name(sample_fmt));
return AVERROR(EINVAL);
/**
* Fill dst buffer with nb_samples, generated starting from t. 交错模式的
*/
static void fill_samples(double *dst, int nb_samples, int nb_channels, int sample_rate, double *t)
int i, j;
double tincr = 1.0 / sample_rate, *dstp = dst;
const double c = 2 * M_PI * 440.0;
/* generate sin tone with 440Hz frequency and duplicated channels */
for (i = 0; i < nb_samples; i++)
*dstp = sin(c * *t);
for (j = 1; j < nb_channels; j++)
dstp[j] = dstp[0];
dstp += nb_channels;
*t += tincr;
int main(int argc, char **argv)
// 输入参数
int64_t src_ch_layout = AV_CH_LAYOUT_STEREO;
int src_rate = 48000;
enum AVSampleFormat src_sample_fmt = AV_SAMPLE_FMT_DBL;
int src_nb_channels = 0;
uint8_t **src_data = NULL; // 二级指针
int src_linesize;
int src_nb_samples = 1024;
// 输出参数
int64_t dst_ch_layout = AV_CH_LAYOUT_STEREO;
int dst_rate = 44100;
enum AVSampleFormat dst_sample_fmt = AV_SAMPLE_FMT_S16;
int dst_nb_channels = 0;
uint8_t **dst_data = NULL; //二级指针
int dst_linesize;
int dst_nb_samples;
int max_dst_nb_samples;
// 输出文件
const char *dst_filename = NULL; // 保存输出的pcm到本地,然后播放验证
FILE *dst_file;
int dst_bufsize;
const char *fmt;
// 重采样实例
struct SwrContext *swr_ctx;
double t;
int ret;
if (argc != 2)
fprintf(stderr, "Usage: %s output_file\\n"
"API example program to show how to resample an audio stream with libswresample.\\n"
"This program generates a series of audio frames, resamples them to a specified "
"output format and rate and saves them to an output file named output_file.\\n",
argv[0]);
exit(1);
dst_filename = argv[1];
dst_file = fopen(dst_filename, "wb");
if (!dst_file)
fprintf(stderr, "Could not open destination file %s\\n", dst_filename);
exit(1);
// 创建重采样器
/* create resampler context */
swr_ctx = swr_alloc();
if (!swr_ctx)
fprintf(stderr, "Could not allocate resampler context\\n");
ret = AVERROR(ENOMEM);
goto end;
// 设置重采样参数
/* set options */
// 输入参数
av_opt_set_int(swr_ctx, "in_channel_layout", src_ch_layout, 0);
av_opt_set_int(swr_ctx, "in_sample_rate", src_rate, 0);
av_opt_set_sample_fmt(swr_ctx, "in_sample_fmt", src_sample_fmt, 0);
// 输出参数
av_opt_set_int(swr_ctx, "out_channel_layout", dst_ch_layout, 0);
av_opt_set_int(swr_ctx, "out_sample_rate", dst_rate, 0);
av_opt_set_sample_fmt(swr_ctx, "out_sample_fmt", dst_sample_fmt, 0);
// 初始化重采样
/* initialize the resampling context */
if ((ret = swr_init(swr_ctx)) < 0)
fprintf(stderr, "Failed to initialize the resampling context\\n");
goto end;
/* allocate source and destination samples buffers */
// 计算出输入源的通道数量
src_nb_channels = av_get_channel_layout_nb_channels(src_ch_layout);
// 给输入源分配内存空间
ret = av_samples_alloc_array_and_samples(&src_data, &src_linesize, src_nb_channels,
src_nb_samples, src_sample_fmt, 0);
if (ret < 0)
fprintf(stderr, "Could not allocate source samples\\n");
goto end;
/* compute the number of converted samples: buffering is avoided
* ensuring that the output buffer will contain at least all the
* converted input samples */
// 计算输出采样数量
max_dst_nb_samples = dst_nb_samples =
av_rescale_rnd(src_nb_samples, dst_rate, src_rate, AV_ROUND_UP);
/* buffer is going to be directly written to a rawaudio file, no alignment */
dst_nb_channels = av_get_channel_layout_nb_channels(dst_ch_layout);
// 分配输出缓存内存
ret = av_samples_alloc_array_and_samples(&dst_data, &dst_linesize, dst_nb_channels,
dst_nb_samples, dst_sample_fmt, 0);
if (ret < 0)
fprintf(stderr, "Could not allocate destination samples\\n");
goto end;
t = 0;
do
/* generate synthetic audio */
// 生成输入源
fill_samples((double *)src_data[0], src_nb_samples, src_nb_channels, src_rate, &t);
/* compute destination number of samples */
int64_t delay = swr_get_delay(swr_ctx, src_rate);
dst_nb_samples = av_rescale_rnd(delay + src_nb_samples, dst_rate, src_rate, AV_ROUND_UP);
if (dst_nb_samples > max_dst_nb_samples)
av_freep(&dst_data[0]);
ret = av_samples_alloc(dst_data, &dst_linesize, dst_nb_channels,
dst_nb_samples, dst_sample_fmt, 1);
if (ret < 0)
break;
max_dst_nb_samples = dst_nb_samples;
// int fifo_size = swr_get_out_samples(swr_ctx,src_nb_samples);
// printf("fifo_size:%d\\n", fifo_size);
// if(fifo_size < 1024)
// continue;
/* convert to destination format */
// ret = swr_convert(swr_ctx, dst_data, dst_nb_samples, (const uint8_t **)src_data, src_nb_samples);
ret = swr_convert(swr_ctx, dst_data, dst_nb_samples, (const uint8_t **)src_data, src_nb_samples);
if (ret < 0)
fprintf(stderr, "Error while converting\\n");
goto end;
dst_bufsize = av_samples_get_buffer_size(&dst_linesize, dst_nb_channels,
ret, dst_sample_fmt, 1);
if (dst_bufsize < 0)
fprintf(stderr, "Could not get sample buffer size\\n");
goto end;
printf("t:%f in:%d out:%d\\n", t, src_nb_samples, ret);
fwrite(dst_data[0], 1, dst_bufsize, dst_file);
while (t < 10);
ret = swr_convert(swr_ctx, dst_data, dst_nb_samples, NULL, 0);
if (ret < 0)
fprintf(stderr, "Error while converting\\n");
goto end;
dst_bufsize = av_samples_get_buffer_size(&dst_linesize, dst_nb_channels,
ret, dst_sample_fmt, 1);
if (dst_bufsize < 0)
fprintf(stderr, "Could not get sample buffer size\\n");
goto end;
printf("flush in:%d out:%d\\n", 0, ret);
fwrite(dst_data[0], 1, dst_bufsize, dst_file);
if ((ret = get_format_from_sample_fmt(&fmt, dst_sample_fmt)) < 0)
goto end;
fprintf(stderr, "Resampling succeeded. Play the output file with the command:\\n"
"ffplay -f %s -channel_layout %"PRId64" -channels %d -ar %d %s\\n",
fmt, dst_ch_layout, dst_nb_channels, dst_rate, dst_filename);
end:
fclose(dst_file);
if (src_data)
av_freep(&src_data[0]);
av_freep(&src_data);
if (dst_data)
av_freep(&dst_data[0]);
av_freep(&dst_data);
swr_free(&swr_ctx);
return ret < 0;
复杂范例
重采样器的设计原理:
- 支持重采样参数的设置
- 支持不同形式的源输入,比如使用frame,**in_data
- 支持不同形式的输出, 比如使用frame,**out_data
- 支持pts
- 支持获取指定采样点数
- 支持flush
数据结构

audioresampler.h
#ifndef AUDIORESAMPLER_H
#define AUDIORESAMPLER_H
#include "libavutil/audio_fifo.h"
#include "libavutil/opt.h"
#include "libavutil/avutil.h"
#include "libswresample/swresample.h"
#include "libavutil/error.h"
#include "libavutil/frame.h"
#include "libavcodec/avcodec.h"
// 重采样的参数
typedef struct audio_resampler_params
// 输入参数
enum AVSampleFormat src_sample_fmt;
int src_sample_rate;
uint64_t src_channel_layout;
// 输出参数
enum AVSampleFormat dst_sample_fmt;
int dst_sample_rate;
uint64_t dst_channel_layout;
audio_resampler_params_t;
// 封装的重采样器
typedef struct audio_resampler
struct SwrContext *swr_ctx; // 重采样的核心
audio_resampler_params_t resampler_params; // 重采样的设置参数
int is_fifo_only; // 不需要进行重采样,只需要缓以上是关于音频重采样的主要内容,如果未能解决你的问题,请参考以下文章