互联网架构演变过程 -- 数据架构
Posted 静曼慕青
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了互联网架构演变过程 -- 数据架构相关的知识,希望对你有一定的参考价值。
文章目录
数据架构
一、单数据库
早在 2003-2004 淘宝 V1.0 就使用 mysql , V1.1 换成 oracle ,直到 2007 数据库重新往 mysql 回迁。 这个阶段往往引发追逐商业大型 db 如 oracle (淘宝 v1.1 , mysql → oracle )
1)方案 java web 项目直接通过 jdbc ,连接单一的数据库,读写扎堆在一块,单库上的机器 io 及 cpu 性能很快达到上限 数据库: mysql 、 oracle 、 sqlserver 、 db2 等(课题: mysql 性能调优) 持久层框架: jdbc , hibernate , jpa , mybatis (课题: mybatis 源码剖析)
二、主从读写
淘宝从 oracle 换回 mysql 的历程中实现了主从库部署与读写分离。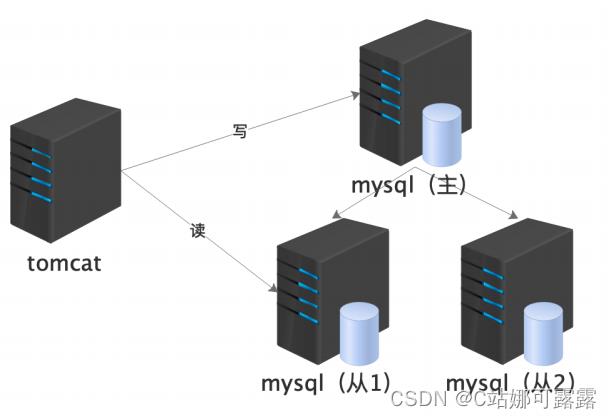
1)方案
- java web应用层连接多个数据库,数据库之间形成主从关系,主库上写,从库上读。读写压力被分散
- 数据库集群:一主多从、双主单写(课题:mysql千亿级数量线上扩容实战)
- 应用层开发:多数据源支持,spring multi datasource
- 中间件:Sharding-JDBC(课题:分库分表下每天亿级订单生成的痛点与架构),Mycat,Atlas
- 数据延迟:从主库到从库之间数据需要经过网络传输,不可避免的有延迟
- 开发层面:需要开发框架具备多数据源的支持,以及自动化的数据源切换
- 单库瓶颈:业务越来越多,表数量越来越多。出现单个库几百张表的现象
- 数据局限:依然无法解决单表大数据的问题,比如订单积累达到亿级,即使在从库,关联查询依然奇慢无比
三、分库分表
2004-2007 ,淘宝 V2.1 ,分库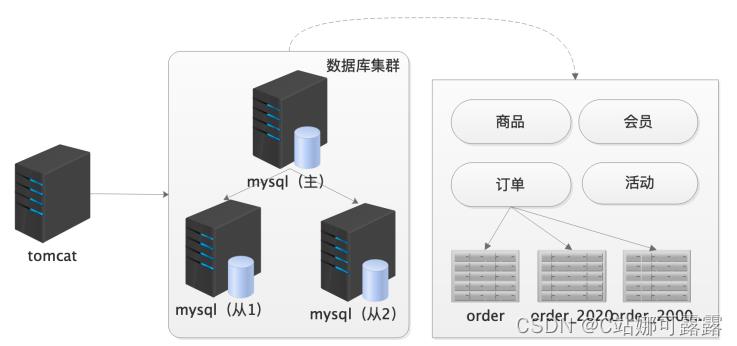 1)方案
主从库的写入依然是有一个统一的主库入口。随着业务量的提升,继续细粒度化拆分
业务分库:订单库,产品库,活动库,会员库
横向分表:(拆记录)
3
个月内订单,半年内订单,更多订单
纵向分表:(拆字段)
name
、
phone
一张表,
info
、
address
一张表,俩表
id
一致
(课题:每天千万级订单的生成背后痛点及技术突破)
2)特点
分库:不同的数据库,所以无法使用数据库事务,而分布式事务的效果并不理想,多采用幂等和最终一致性方案。
(课题:多服务之间分布式事务的一站解决,业务幂等性技术架构体系)
分表:拆了再聚合是一对矛盾,例如按下单时间维度的分表,需要按用户排序统计变得异常困难。
中间件:
Sharding-JDBC
,
Mycat
,
Atlas
1)方案
主从库的写入依然是有一个统一的主库入口。随着业务量的提升,继续细粒度化拆分
业务分库:订单库,产品库,活动库,会员库
横向分表:(拆记录)
3
个月内订单,半年内订单,更多订单
纵向分表:(拆字段)
name
、
phone
一张表,
info
、
address
一张表,俩表
id
一致
(课题:每天千万级订单的生成背后痛点及技术突破)
2)特点
分库:不同的数据库,所以无法使用数据库事务,而分布式事务的效果并不理想,多采用幂等和最终一致性方案。
(课题:多服务之间分布式事务的一站解决,业务幂等性技术架构体系)
分表:拆了再聚合是一对矛盾,例如按下单时间维度的分表,需要按用户排序统计变得异常困难。
中间件:
Sharding-JDBC
,
Mycat
,
Atlas
四、高速缓存
2006-2007 ,淘宝 V2.2 架构,分布式缓存 Tair 引入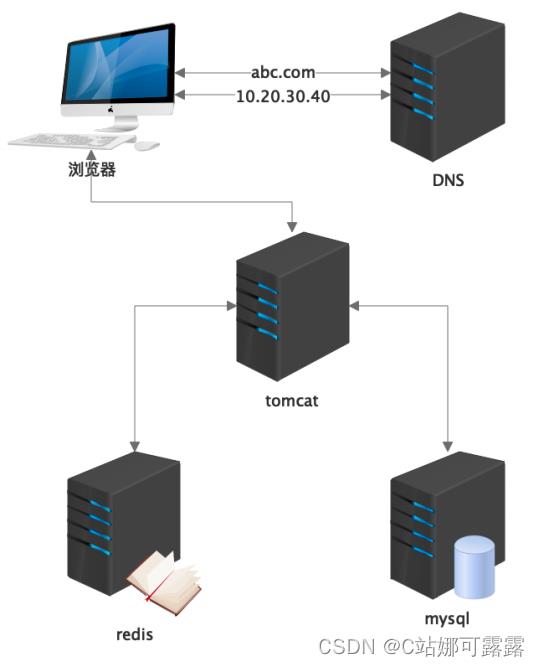
1)方案 数据库往往是系统的瓶颈,根据数据的冷热划分,热点数据如类目、商品基础信息放在缓存中,其他数据延迟加载 ehcache :非分布式,简单,易维护,可用性一般 memcache :性能可靠,纯内存,客户端需要自己实现,无持久化 redis :性能可靠,纯内存,自带分片,集群,哨兵,支持持久化,几乎成为当前的标准方案 (课题: MTD 巨头高性能缓存代理方案实战, Twemproxy 高阶使用) 2)特点 缓存策略:冷热数据的存放,缓存与 db 的边界需要架构师去把控,重度依赖可能引发问题 (memcache 造成 db 高压案例; redis 短信平台故障案例 ) 缓存陷阱:击穿(单一 key 过期),穿透(不存在的 key ),雪崩(多个 key 同时过期) 数据一致性:缓存和 db 之间因为同一份数据保存了两份,自然带来了一致性问题 (课题: redis 高阶技术剖析)
五、数据多样化
一个网站中,数据库和缓存只是一种基本的存储手段,除了这些,随着网站架构的发展其他各种形式的存储结构相继涌现: 2006-2007 ,淘宝 V2.2 ,分布式存储 TFS ,分布式缓存 Tair , V3.0 加入 nosql Cassandra ,搜索引擎升级 数据库全文检索 → 搜索引擎、本地上传 +nfs → 分布式文件系统的演进,方案后期均有深入讲解
1、分布式文件
商品图片,上传的文件等 hdfs :大数据下的分布式存储(课题: Apache Druid 打造大数据实时监控系统,基于 Flink 的打车平台实时流数据分析) fastdfs cephFs (课题:无限容量云盘分布式存储技术方案 ceph )2、nosql
redis 经典缓存,上节已介绍 mongodb (课题: mongodb 海量数据生产扩容实战) hbase tidb (课题: TiDB 亿级订单数据亚秒响应查询方案)3、搜索引擎
搜索引擎: lucene , solr , elasticsearch (课题:电商终极搜索 ElasticStack )4、架构特点
- 开发框架支持:存储的数据多样化,要求开发框架架构层面要提供多样化的支撑,并确保访问易用性
- 数据运维:多种数据服务器对运维的要求提升,机器的数据维护与灾备工作量加大
- 数据安全:多种数据存储的权限,授权与访问隔离需要注意
六、总结与思考
- 常见的数据库有哪些?持久层框架呢?
- 什么是分库,什么是分表?分表有哪些分法?
- 缓存有哪些问题,各是什么样的场景?
以上是关于互联网架构演变过程 -- 数据架构的主要内容,如果未能解决你的问题,请参考以下文章