4 kafka集群部署及生产者java客户端编程 + kafka消费者java客户端编程
Posted 大数据和人工智能躺过的坑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了4 kafka集群部署及生产者java客户端编程 + kafka消费者java客户端编程相关的知识,希望对你有一定的参考价值。
本博文的主要内容有
kafka的单机模式部署
kafka的分布式模式部署
生产者java客户端编程
消费者java客户端编程
运行kafka ,需要依赖 zookeeper,你可以使用已有的 zookeeper 集群或者利用 kafka自带的zookeeper。
单机模式,用的是kafka自带的zookeeper,
分布式模式,用的是外部安装的zookeeper,即公共的zookeeper。
说在前面的话

我这里是使用的是,kafka自带的zookeeper。
以及关于kafka的日志文件啊,都放在默认里即/tmp下,我没修改。保存默认的
1、 [hadoop@sparksinglenode kafka_2.10-0.8.1.1]$ jps
2625 Jps
2、 [hadoop@sparksinglenode kafka_2.10-0.8.1.1]$ bin/zookeeper-server-start.sh config/zookeeper.properties &
此刻,这时,会一直停在这,因为是前端运行。
另开一窗口,
3、 [hadoop@sparksinglenode kafka_2.10-0.8.1.1]$ bin/kafka-server-start.sh config/server.properties &
也是前端运行。
推荐做法!!!
但是,我这里,自己在kafka安装目录下,为了自己的方便,写了个startkafka.sh和startzookeeper.sh
nohup bin/kafka-server-start.sh config/server.properties > kafka.log 2>&1 &
nohup bin/zookeeper-server-start.sh config/zookeeper.properties > zookeeper.log 2>&1 &
注意还要,root用户来,附上执行权限。chmod +x ./startkafka.sh chmod +x ./startzookeeper.sh
这样,就会在kafka安装目录下,对应生出kafka.log和zookeeper.log。
1、[spark@sparksinglenode kafka_2.10-0.8.1.1]$ jps
5098 Jps
2、[spark@sparksinglenode kafka_2.10-0.8.1.1]$ bash startzookeeper.sh
[spark@sparksinglenode kafka_2.10-0.8.1.1]$ jps
5125 Jps
5109 QuorumPeerMain
3、[spark@sparksinglenode kafka_2.10-0.8.1.1]$ bash startkafka.sh
[spark@sparksinglenode kafka_2.10-0.8.1.1]$ jps
5155 Jps
5140 Kafka
5109 QuorumPeerMain
[spark@sparksinglenode kafka_2.10-0.8.1.1]$


我了个去,启动是多么方便!
运行 kafka ,需要依赖 zookeeper,你可以使用已有的 zookeeper 集群或者利用 kafka自带的zookeeper。
这里,我安装的是单机模式,来玩玩而已,入门。当然,在实际生产中,是分布式的。即用到是,外部安装的zookeeper集群(3节点)。
1、kafka的单机模式部署
1、 kafka_2.10-0.8.1.1.tgz的下载
官方文档:http://kafka.apache.org/documentation.html#quickstart
http://archive.apache.org/dist/kafka/
http://archive.apache.org/dist/kafka/0.8.1.1/


2、 kafka_2.10-0.8.1.1.tgz的上传
sftp> cd /home/hadoop/app/
sftp> put c:/kafka_2.10-0.8.1.1.tgz
Uploading kafka_2.10-0.8.1.1.tgz to /home/hadoop/app/kafka_2.10-0.8.1.1.tgz
100% 13467KB 13467KB/s 00:00:01
c:/kafka_2.10-0.8.1.1.tgz: 13790731 bytes transferred in 1 seconds (13467 KB/s)
sftp>

[hadoop@weekend110 app]$ ls
hadoop-2.4.1 hbase-0.96.2-hadoop2 hive-0.12.0 jdk1.7.0_65
[hadoop@weekend110 app]$ ls
hadoop-2.4.1 hbase-0.96.2-hadoop2 hive-0.12.0 jdk1.7.0_65 kafka_2.10-0.8.1.1.tgz
[hadoop@weekend110 app]$ ll
total 13484
drwxr-xr-x. 11 hadoop hadoop 4096 Jul 18 20:11 hadoop-2.4.1
drwxrwxr-x. 8 hadoop hadoop 4096 Oct 12 12:19 hbase-0.96.2-hadoop2
drwxrwxr-x. 10 hadoop hadoop 4096 Oct 10 21:30 hive-0.12.0
drwxr-xr-x. 8 hadoop hadoop 4096 Jun 17 2014 jdk1.7.0_65
-rw-r--r--. 1 root root 13790731 May 12 03:44 kafka_2.10-0.8.1.1.tgz
[hadoop@weekend110 app]$
3、 kafka_2.10-0.8.1.1.tgz的解压和删除压缩包
[hadoop@weekend110 app]$ ls
hadoop-2.4.1 hbase-0.96.2-hadoop2 hive-0.12.0 jdk1.7.0_65 kafka_2.10-0.8.1.1.tgz
[hadoop@weekend110 app]$ tar -zxvf kafka_2.10-0.8.1.1.tgz
4、 kafka_2.10-0.8.1.1.tgz的配置

[hadoop@weekend110 app]$ ll
total 13488
drwxr-xr-x. 11 hadoop hadoop 4096 Jul 18 20:11 hadoop-2.4.1
drwxrwxr-x. 8 hadoop hadoop 4096 Oct 12 12:19 hbase-0.96.2-hadoop2
drwxrwxr-x. 10 hadoop hadoop 4096 Oct 10 21:30 hive-0.12.0
drwxr-xr-x. 8 hadoop hadoop 4096 Jun 17 2014 jdk1.7.0_65
drwxr-xr-x. 5 hadoop hadoop 4096 Apr 23 2014 kafka_2.10-0.8.1.1
-rw-r--r--. 1 root root 13790731 May 12 03:44 kafka_2.10-0.8.1.1.tgz
[hadoop@weekend110 app]$ rm kafka_2.10-0.8.1.1.tgz
rm: remove write-protected regular file `kafka_2.10-0.8.1.1.tgz\'? y
[hadoop@weekend110 app]$ ll
total 20
drwxr-xr-x. 11 hadoop hadoop 4096 Jul 18 20:11 hadoop-2.4.1
drwxrwxr-x. 8 hadoop hadoop 4096 Oct 12 12:19 hbase-0.96.2-hadoop2
drwxrwxr-x. 10 hadoop hadoop 4096 Oct 10 21:30 hive-0.12.0
drwxr-xr-x. 8 hadoop hadoop 4096 Jun 17 2014 jdk1.7.0_65
drwxr-xr-x. 5 hadoop hadoop 4096 Apr 23 2014 kafka_2.10-0.8.1.1
[hadoop@weekend110 app]$
注意,将Kafka安装目录下的bin下的脚本,都附上执行权限。
为了自己日后操作方便,这里,自己写个脚本。

nohup bin/kafka-server-start.sh config/server.properties > kafka.log 2>&1 &

[hadoop@weekend110 config]$ pwd
/home/hadoop/app/kafka_2.10-0.8.1.1/config
[hadoop@weekend110 config]$ ls
consumer.properties producer.properties test-log4j.properties zookeeper.properties
log4j.properties server.properties tools-log4j.properties
[hadoop@weekend110 config]$ vim zookeeper.properties

若是,单机模式的安装kafka,用kafka自带的zookeeper,则不需修改。看看就好,
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# the directory where the snapshot is stored.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0
zookeeper的配置文件zookeeper.properties里面的关键属性:
# the directory where the snapshot is stored.
dataDir=/tmp/zookeeper
//这里,当然,可以自己新建其他目录,否则,每次开机就会清除这个临时目录。
# the port at which the clients will connect
clientPort=2181
默认情况下,zookeeper的snapshot 文件会存储在/tmp/zookeeper下,zookeeper服务器会监听 2181端口。
若是,自己新建其他目录,则可以是。
dataDir=/home/hadoop/data/zookeeper
dataLogDir=/home/hadoop/data/zkdatalog

[hadoop@weekend110 config]$ vim server.properties
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see kafka.server.KafkaConfig for additional details and defaults
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
############################# Socket Server Settings #############################
# The port the socket server listens on
port=9092
# Hostname the broker will bind to. If not set, the server will bind to all interfaces
# host.name=localhost
# Hostname the broker will advertise to producers and consumers. If not set, it uses the
# value for "host.name" if configured. Otherwise, it will use the value returned from
# java.net.InetAddress.getCanonicalHostName().
#advertised.host.name=<hostname routable by clients>
# The port to publish to ZooKeeper for clients to use. If this is not set,
# it will publish the same port that the broker binds to.
#advertised.port=<port accessible by clients>
# The number of threads handling network requests
num.network.threads=2
# The number of threads doing disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=1048576
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=1048576
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs // 或者可以自己新建目录,
/home/hadoop/data/kafka-logs
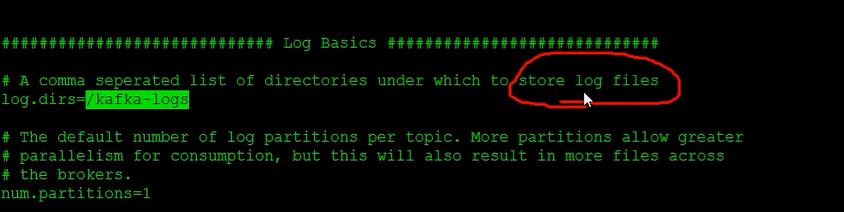
也可以如这样,注意啦。就是在这里。即kafka安装目录下的根目录。
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=2
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to exceessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
# segments don\'t drop below log.retention.bytes.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=536870912
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=60000
# By default the log cleaner is disabled and the log retention policy will default to just delete segments after their retention expires.
# If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction.
log.cleaner.enable=false
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=1000000
5、kafka_2.10-0.8.1.1.tgz的配置环境变量

[hadoop@weekend110 kafka_2.10-0.8.1.1]$ su root
Password:
[root@weekend110 kafka_2.10-0.8.1.1]# pwd
/home/hadoop/app/kafka_2.10-0.8.1.1
[root@weekend110 kafka_2.10-0.8.1.1]# ls
bin config libs LICENSE NOTICE
[root@weekend110 kafka_2.10-0.8.1.1]# vim /etc/profile
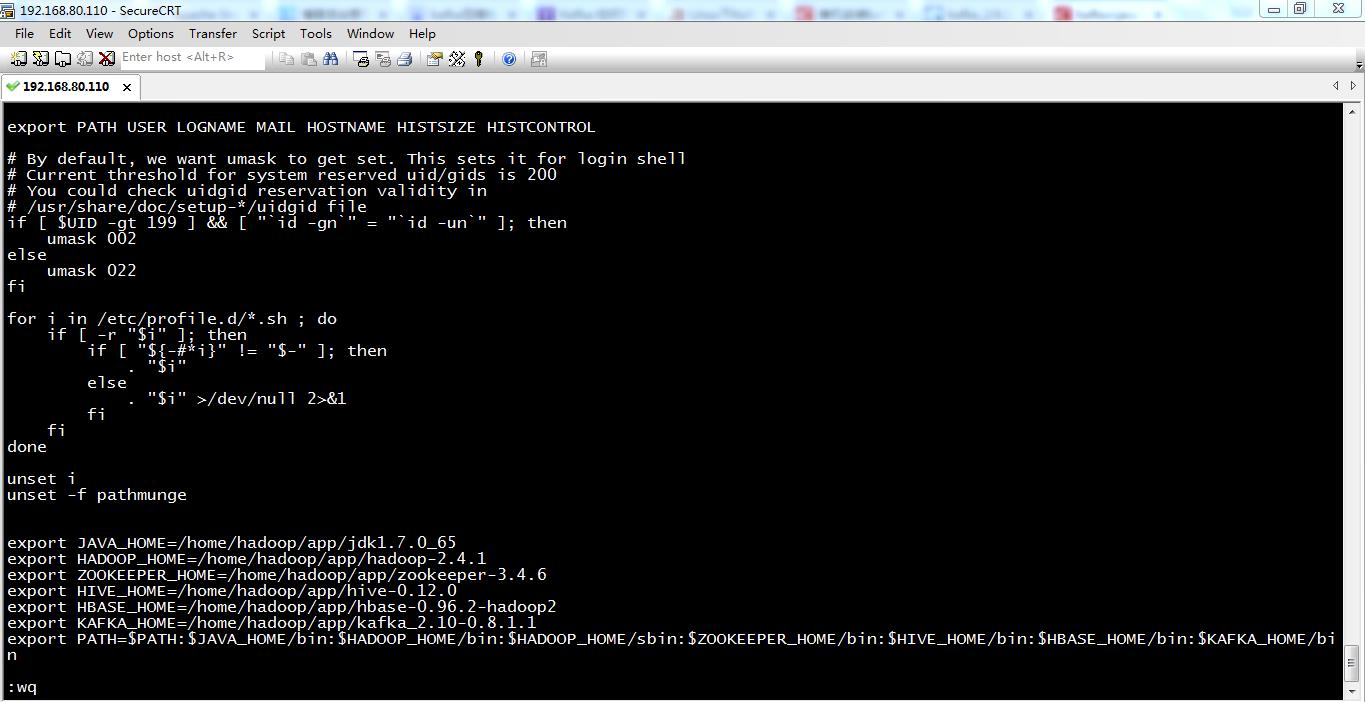
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export HADOOP_HOME=/home/hadoop/app/hadoop-2.4.1
export ZOOKEEPER_HOME=/home/hadoop/app/zookeeper-3.4.6
export HIVE_HOME=/home/hadoop/app/hive-0.12.0
export HBASE_HOME=/home/hadoop/app/hbase-0.96.2-hadoop2
export KAFKA_HOME=/home/hadoop/app/kafka_2.10-0.8.1.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin:$HBASE_HOME/bin:$KAFKA_HOME/bin

[root@weekend110 kafka_2.10-0.8.1.1]# clear
[root@weekend110 kafka_2.10-0.8.1.1]# source /etc/profile
[root@weekend110 kafka_2.10-0.8.1.1]# kafka -version
bash: kafka: command not found
因为,kafka里,没有这样的查看版本命令了,这是要注意的地方。
先将zookeeper启动,再启动kafka。
我这里,采用的是kafk自带的zookeeper。
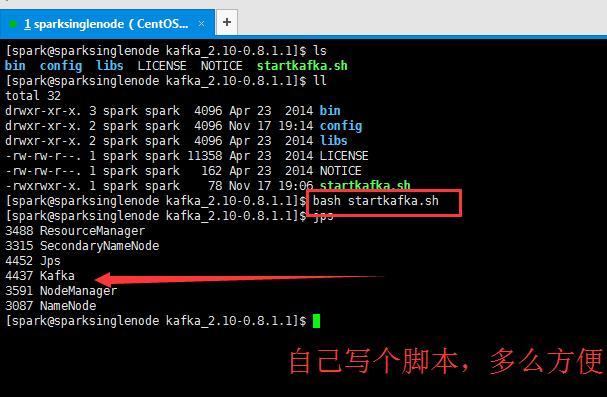
以后就是可以这么干啦( 适应于 在单机模式下安装的kafka,而且还是用的kafka自带的zookeeper)
启动和停止
运行 kafka ,需要依赖 zookeeper,你可以使用已有的 zookeeper 集群或者利用 kafka 提供的脚本启动一个 zookeeper 实例:
$ bin/zookeeper-server-start.sh config/zookeeper.properties & (其实,本博文最顶部的,写在前面的话,那样更好!强烈建议)
默认的,zookeeper 会监听在 *:2181/tcp。
停止刚才启动的 zookeeper 实例:
$ bin/zookeeper-server-stop.sh
启动Kafka server:
$ bin/kafka-server-start.sh config/server.properties &

出现如下的错误,
参考 http://www.bkjia.com/yjs/947570.html
解决方法:
找到bin/kafka-run-class.sh 文件,使用vim打开,我的这个版本是在115行
113 # JVM performance options
114 if [ -z "$KAFKA_JVM_PERFORMANCE_OPTS" ]; then
115 KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseCompressedOops -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled -XX:+CMSScavengeBeforeRe mark -XX:+DisableExplicitGC -Djava.awt.headless=true"
116 fi
去掉-XX:+UseCompressedOops这个设置


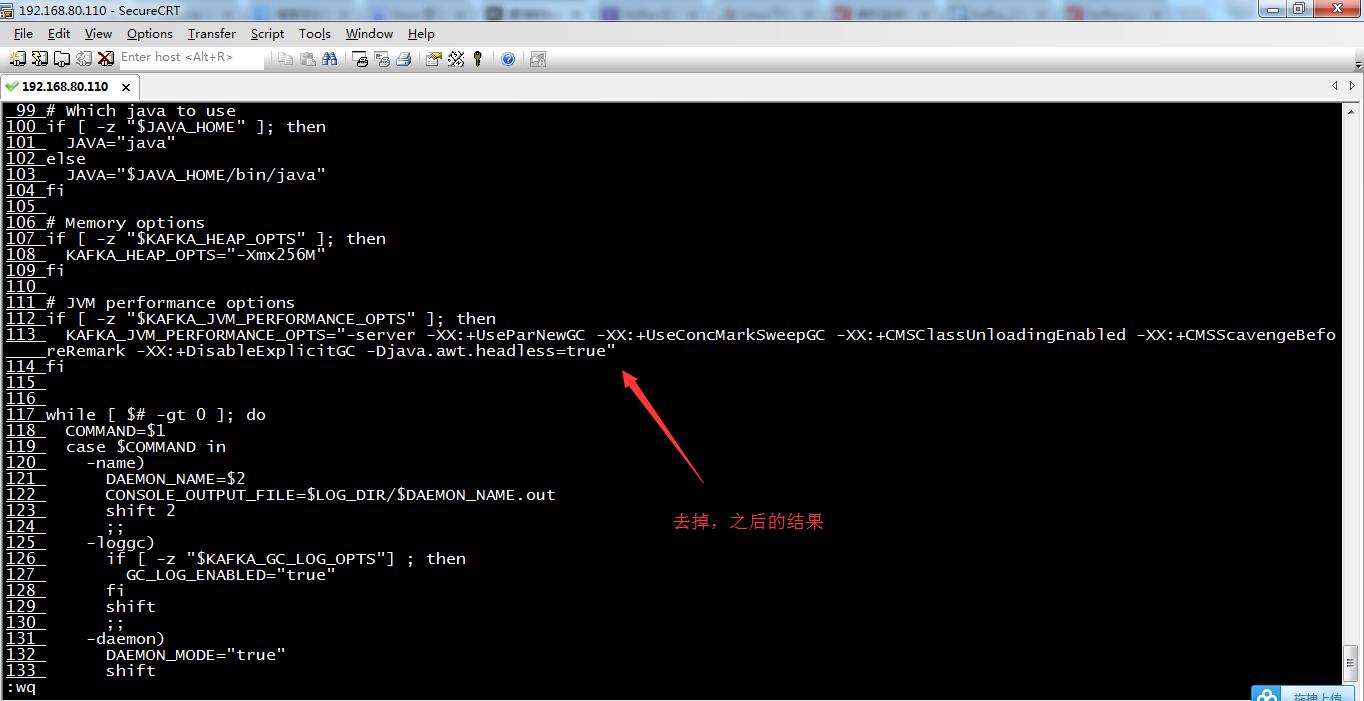
111 # JVM performance options
112 if [ -z "$KAFKA_JVM_PERFORMANCE_OPTS" ]; then
113 KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled -XX:+CMSScavengeBefo reRemark -XX:+DisableExplicitGC -Djava.awt.headless=true"
114 fi
然后,现在,再启动kafka自带的 zookeeper,再启动kafka。
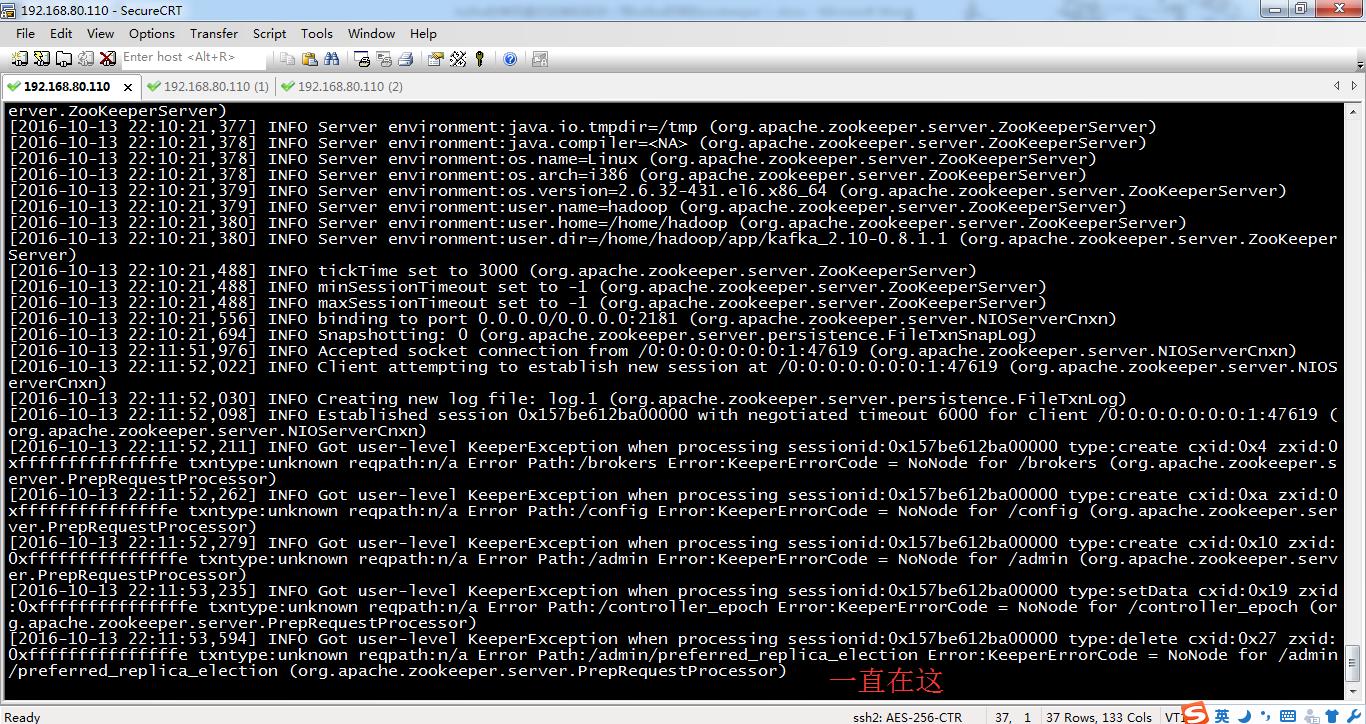
[hadoop@weekend110 kafka_2.10-0.8.1.1]$ jps
2625 Jps
[hadoop@weekend110 kafka_2.10-0.8.1.1]$ bin/zookeeper-server-start.sh config/zookeeper.properties &
[1] 2634
[hadoop@weekend110 kafka_2.10-0.8.1.1]$ [2016-10-13 22:10:21,122] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
[2016-10-13 22:10:21,126] WARN Either no config or no quorum defined in config, running in standalone mode (org.apache.zookeeper.server.quorum.QuorumPeerMain)
[2016-10-13 22:10:21,287] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
[2016-10-13 22:10:21,292] INFO Starting server (org.apache.zookeeper.server.ZooKeeperServerMain)
[2016-10-13 22:10:21,366] INFO Server environment:zookeeper.version=3.3.3-1203054, built on 11/17/2011 05:47 GMT (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,367] INFO Server environment:host.name=weekend110 (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,370] INFO Server environment:java.version=1.7.0_65 (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,370] INFO Server environment:java.vendor=Oracle Corporation (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,370] INFO Server environment:java.home=/home/hadoop/app/jdk1.7.0_65/jre (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,371] INFO Server environment:java.class.path=:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../core/build/dependant-libs-2.8.0/*.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../perf/build/libs//kafka-perf_2.8.0*.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../clients/build/libs//kafka-clients*.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../examples/build/libs//kafka-examples*.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../contrib/hadoop-consumer/build/libs//kafka-hadoop-consumer*.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../contrib/hadoop-producer/build/libs//kafka-hadoop-producer*.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/jopt-simple-3.2.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/kafka_2.10-0.8.1.1.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/kafka_2.10-0.8.1.1-javadoc.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/kafka_2.10-0.8.1.1-scaladoc.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/kafka_2.10-0.8.1.1-sources.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/log4j-1.2.15.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/metrics-core-2.2.0.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/scala-library-2.10.1.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/slf4j-api-1.7.2.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/snappy-java-1.0.5.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/zkclient-0.3.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/zookeeper-3.3.4.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../core/build/libs/kafka_2.8.0*.jar (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,377] INFO Server environment:java.library.path=/usr/java/packages/lib/i386:/lib:/usr/lib (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,377] INFO Server environment:java.io.tmpdir=/tmp (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,378] INFO Server environment:java.compiler=<NA> (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,378] INFO Server environment:os.name=Linux (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,378] INFO Server environment:os.arch=i386 (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,379] INFO Server environment:os.version=2.6.32-431.el6.x86_64 (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,379] INFO Server environment:user.name=hadoop (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,380] INFO Server environment:user.home=/home/hadoop (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,380] INFO Server environment:user.dir=/home/hadoop/app/kafka_2.10-0.8.1.1 (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,488] INFO tickTime set to 3000 (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,488] INFO minSessionTimeout set to -1 (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,488] INFO maxSessionTimeout set to -1 (org.apache.zookeeper.server.ZooKeeperServer)
[2016-10-13 22:10:21,556] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NioserverCnxn)
[2016-10-13 22:10:21,694] INFO Snapshotting: 0 (org.apache.zookeeper.server.persistence.FileTxnSnapLog)
[2016-10-13 22:11:51,976] INFO Accepted socket connection from /0:0:0:0:0:0:0:1:47619 (org.apache.zookeeper.server.NIOServerCnxn)
[2016-10-13 22:11:52,022] INFO Client attempting to establish new session at /0:0:0:0:0:0:0:1:47619 (org.apache.zookeeper.server.NIOServerCnxn)
[2016-10-13 22:11:52,030] INFO Creating new log file: log.1 (org.apache.zookeeper.server.persistence.FileTxnLog)
[2016-10-13 22:11:52,098] INFO Established session 0x157be612ba00000 with negotiated timeout 6000 for client /0:0:0:0:0:0:0:1:47619 (org.apache.zookeeper.server.NIOServerCnxn)
[2016-10-13 22:11:52,211] INFO Got user-level KeeperException when processing sessionid:0x157be612ba00000 type:create cxid:0x4 zxid:0xfffffffffffffffe txntype:unknown reqpath:n/a Error Path:/brokers Error:KeeperErrorCode = NoNode for /brokers (org.apache.zookeeper.server.PrepRequestProcessor)
[2016-10-13 22:11:52,262] INFO Got user-level KeeperException when processing sessionid:0x157be612ba00000 type:create cxid:0xa zxid:0xfffffffffffffffe txntype:unknown reqpath:n/a Error Path:/config Error:KeeperErrorCode = NoNode for /config (org.apache.zookeeper.server.PrepRequestProcessor)
[2016-10-13 22:11:52,279] INFO Got user-level KeeperException when processing sessionid:0x157be612ba00000 type:create cxid:0x10 zxid:0xfffffffffffffffe txntype:unknown reqpath:n/a Error Path:/admin Error:KeeperErrorCode = NoNode for /admin (org.apache.zookeeper.server.PrepRequestProcessor)
[2016-10-13 22:11:53,235] INFO Got user-level KeeperException when processing sessionid:0x157be612ba00000 type:setData cxid:0x19 zxid:0xfffffffffffffffe txntype:unknown reqpath:n/a Error Path:/controller_epoch Error:KeeperErrorCode = NoNode for /controller_epoch (org.apache.zookeeper.server.PrepRequestProcessor)
[2016-10-13 22:11:53,594] INFO Got user-level KeeperException when processing sessionid:0x157be612ba00000 type:delete cxid:0x27 zxid:0xfffffffffffffffe txntype:unknown reqpath:n/a Error Path:/admin/preferred_replica_election Error:KeeperErrorCode = NoNode for /admin/preferred_replica_election (org.apache.zookeeper.server.PrepRequestProcessor)
[hadoop@weekend110 kafka_2.10-0.8.1.1]$ pwd
/home/hadoop/app/kafka_2.10-0.8.1.1
[hadoop@weekend110 kafka_2.10-0.8.1.1]$ bin/kafka-server-start.sh config/server.properties &
[1] 2692
[hadoop@weekend110 kafka_2.10-0.8.1.1]$ [2016-10-13 22:11:51,302] INFO Verifying properties (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,586] INFO Property broker.id is overridden to 0 (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,593] INFO Property log.cleaner.enable is overridden to false (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,597] INFO Property log.dirs is overridden to /home/hadoop/data/kafka-logs (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,597] INFO Property log.retention.check.interval.ms is overridden to 60000 (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,605] INFO Property log.retention.hours is overridden to 168 (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,608] INFO Property log.segment.bytes is overridden to 536870912 (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,610] INFO Property num.io.threads is overridden to 8 (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,610] INFO Property num.network.threads is overridden to 2 (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,626] INFO Property num.partitions is overridden to 2 (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,627] INFO Property port is overridden to 9092 (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,628] INFO Property socket.receive.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,629] INFO Property socket.request.max.bytes is overridden to 104857600 (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,635] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,636] INFO Property zookeeper.connect is overridden to localhost:2181 (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,637] INFO Property zookeeper.connection.timeout.ms is overridden to 1000000 (kafka.utils.VerifiableProperties)
[2016-10-13 22:11:51,800] INFO [Kafka Server 0], starting (kafka.server.KafkaServer)
[2016-10-13 22:11:51,805] INFO [Kafka Server 0], Connecting to zookeeper on localhost:2181 (kafka.server.KafkaServer)
[2016-10-13 22:11:51,839] INFO Starting ZkClient event thread. (org.I0Itec.zkclient.ZkEventThread)
[2016-10-13 22:11:51,869] INFO Client environment:zookeeper.version=3.3.3-1203054, built on 11/17/2011 05:47 GMT (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,870] INFO Client environment:host.name=weekend110 (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,870] INFO Client environment:java.version=1.7.0_65 (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,870] INFO Client environment:java.vendor=Oracle Corporation (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,870] INFO Client environment:java.home=/home/hadoop/app/jdk1.7.0_65/jre (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,870] INFO Client environment:java.class.path=:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../core/build/dependant-libs-2.8.0/*.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../perf/build/libs//kafka-perf_2.8.0*.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../clients/build/libs//kafka-clients*.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../examples/build/libs//kafka-examples*.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../contrib/hadoop-consumer/build/libs//kafka-hadoop-consumer*.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../contrib/hadoop-producer/build/libs//kafka-hadoop-producer*.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/jopt-simple-3.2.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/kafka_2.10-0.8.1.1.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/kafka_2.10-0.8.1.1-javadoc.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/kafka_2.10-0.8.1.1-scaladoc.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/kafka_2.10-0.8.1.1-sources.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/log4j-1.2.15.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/metrics-core-2.2.0.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/scala-library-2.10.1.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/slf4j-api-1.7.2.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/snappy-java-1.0.5.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/zkclient-0.3.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../libs/zookeeper-3.3.4.jar:/home/hadoop/app/kafka_2.10-0.8.1.1/bin/../core/build/libs/kafka_2.8.0*.jar (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,870] INFO Client environment:java.library.path=/usr/java/packages/lib/i386:/lib:/usr/lib (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,871] INFO Client environment:java.io.tmpdir=/tmp (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,871] INFO Client environment:java.compiler=<NA> (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,871] INFO Client environment:os.name=Linux (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,872] INFO Client environment:os.arch=i386 (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,872] INFO Client environment:os.version=2.6.32-431.el6.x86_64 (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,872] INFO Client environment:user.name=hadoop (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,872] INFO Client environment:user.home=/home/hadoop (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,872] INFO Client environment:user.dir=/home/hadoop/app/kafka_2.10-0.8.1.1 (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,875] INFO Initiating client connection, connectString=localhost:2181 sessionTimeout=6000 watcher=org.I0Itec.zkclient.ZkClient@7b7258 (org.apache.zookeeper.ZooKeeper)
[2016-10-13 22:11:51,955] INFO Opening socket connection to server localhost/0:0:0:0:0:0:0:1:2181 (org.apache.zookeeper.ClientCnxn)
[2016-10-13 22:11:51,992] INFO Socket connection established to localhost/0:0:0:0:0:0:0:1:2181, initiating session (org.apache.zookeeper.ClientCnxn)
[2016-10-13 22:11:52,101] INFO Session establishment complete on server localhost/0:0:0:0:0:0:0:1:2181, sessionid = 0x157be612ba00000, negotiated timeout = 6000 (org.apache.zookeeper.ClientCnxn)
[2016-10-13 22:11:52,107] INFO zookeeper state changed (SyncConnected) (org.I0Itec.zkclient.ZkClient)
[2016-10-13 22:11:52,587] INFO Starting log cleanup with a period of 60000 ms. (kafka.log.LogManager)
[2016-10-13 22:11:52,597] INFO Starting log flusher with a default period of 9223372036854775807 ms. (kafka.log.LogManager)
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
[2016-10-13 22:11:52,707] INFO Awaiting socket connections on 0.0.0.0:9092. (kafka.network.Acceptor)
[2016-10-13 22:11:52,709] INFO [Socket Server on Broker 0], Started (kafka.network.SocketServer)
[2016-10-13 22:11:53,049] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2016-10-13 22:11:53,223] INFO 0 successfully elected as leader (kafka.server.ZookeeperLeaderElector)
[2016-10-13 22:11:53,771] INFO Registered broker 0 at path /brokers/ids/0 with address weekend110:9092. (kafka.utils.ZkUtils$)
[2016-10-13 22:11:53,825] INFO [Kafka Server 0], started (kafka.server.KafkaServer)
[2016-10-13 22:11:53,999] INFO New leader is 0 (kafka.server.ZookeeperLeaderElector$LeaderChangeListener)

[hadoop@weekend110 ~]$ jps
2769 Jps
2692 Kafka
2634 QuorumPeerMain
[hadoop@weekend110 ~]$
利用 kafka 提供的脚本启动一个 zookeeper 实例:
$ bin/zookeeper-server-start.sh config/zookeeper.properties &
停止刚才启动的 zookeeper 实例:
$ bin/zookeeper-server-stop.sh
启动Kafka server:
$ bin/kafka-server-start.sh config/server.properties &
停止 Kafka server :
$ bin/kafka-server-stop.sh
kafka_2.10-0.8.1.1.tgz的使用介绍:
参考http://liyonghui160com.iteye.com/blog/2105824
创建topic
列出topic
Producer
Comsumer
http://kafka.apache.org/documentation
参考官网
创建只有一个Partition的topic
这里创建了一个test的topic、和列出它。

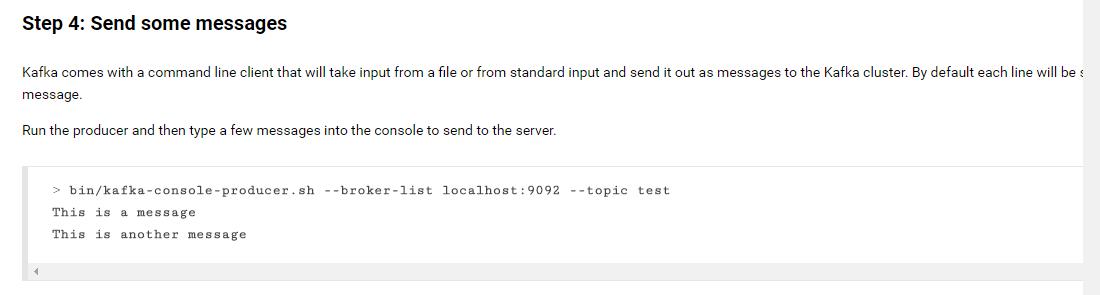
启动一个生产者进程来发送消息
其中,(1)参数broker-list定义了生产者要推送消息的broker地址,以<IP地址:端口>形式 ,由上面的broker的配置文件可知 为localhost:9092;
(2)参数topic指定生产者发送给哪个topic。
生产者配置文件关键属性:
# list of brokers used for bootstrapping knowledge about the rest of the cluster
# format: host1:port1,host2:port2 ...
metadata.broker.list=localhost:9092
# specifies
whether the messages are sent asynchronously (async) or synchronously (sync)
producer.type=sync
# message encoder
serializer.class=kafka.serializer.DefaultEncoder
接着你就可以输入你想要发送给消费者的消息了。(也可以先启动消费者进程,这样生产者发送的消息可以立刻显示)。

[hadoop@weekend110 kafka_2.10-0.8.1.1]$ jps
2969 QuorumPeerMain
3024 Kafka
3109 Jps
[hadoop@weekend110 kafka_2.10-0.8.1.1]$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Created topic "test".
[hadoop@weekend110 kafka_2.10-0.8.1.1]$ bin/kafka-topics.sh --list --zookeeper localhost:2181
test
[hadoop@weekend110 kafka_2.10-0.8.1.1]$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
iphone
xiaomi
meizu
niubi
启动一个消费者进程来消费消息
需要另外打开一个终端:
其中,(1)参数zookeeper指定了连接zookeeper的地址,以<IP地址:端口>形式;
(2)topic参数指定了从哪个topic来pull消息。
当你执行这个命令之后,你便可以看到控制台上打印出的生产者生产的消息:
消费者配置文件consumer.properties关键属性:
# Zookeeper connection string
# comma separated host:port pairs, each corresponding
to a zk
# server. e.g.
"127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002"
zookeeper.connect=localhost:2181
# timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=60000
#consumer group id
group.id=test-consumer-group


[hadoop@weekend110 kafka_2.10-0.8.1.1]$ bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
iphone
xiaomi
meizu
niubi
我这边,继续写,
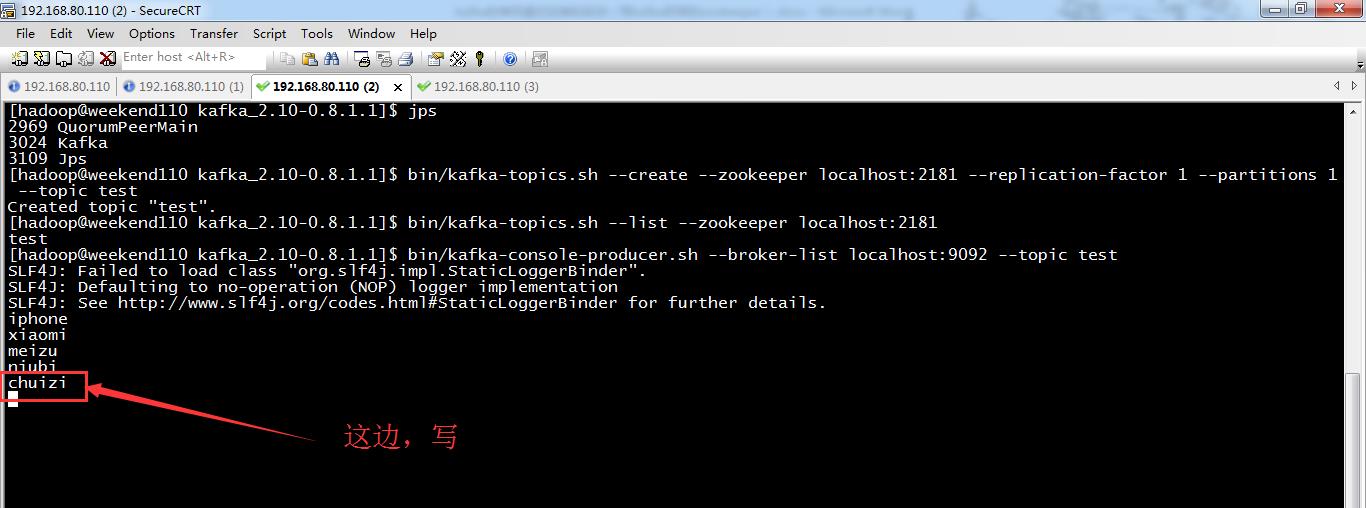
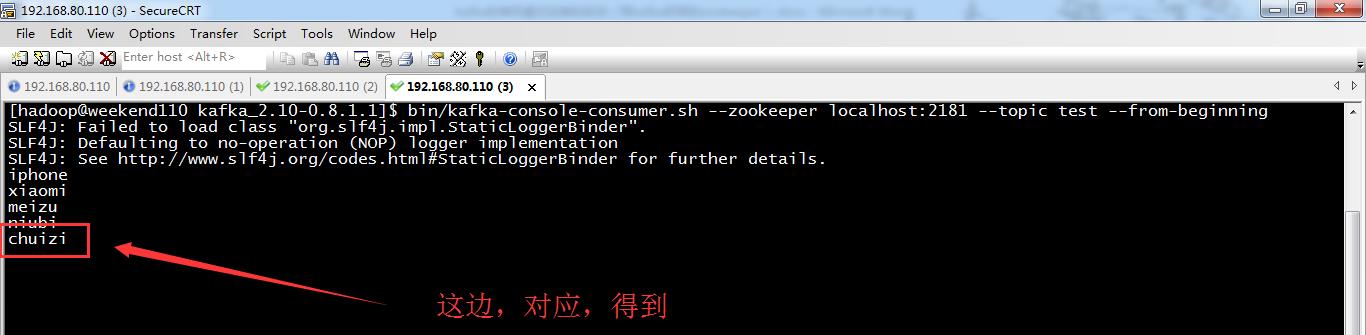


直接,读取,照样,得到。因为,kafka已经保存进去了。
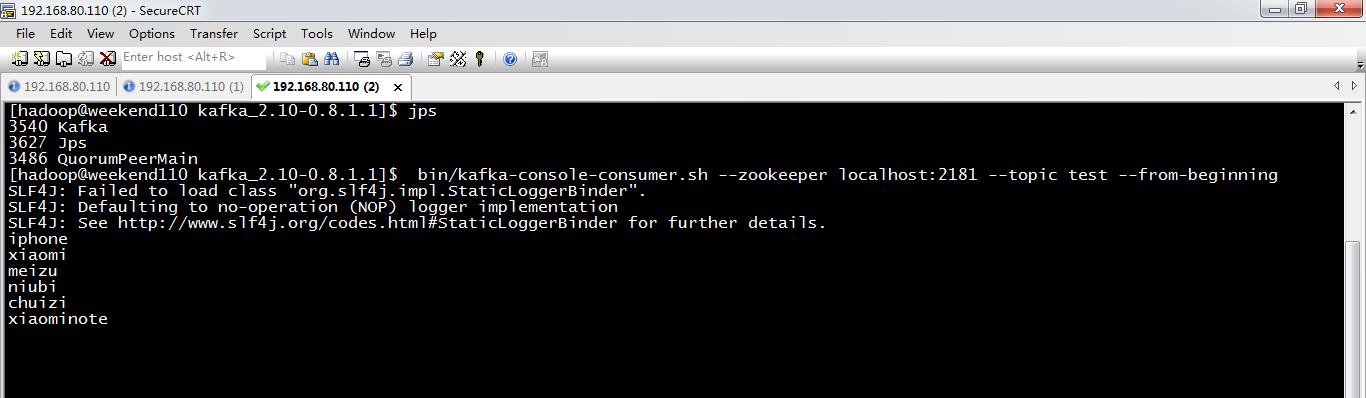
Kafka的集群配置一般有三种方法,即
(1)Single node – single broker集群;
(2)Single node – multiple broker集群;
(3)Multiple node – multiple broker集群。

参考:http://www.itnose.net/detail/6636559.html
参考:http://www.itnose.net/detail/6636559.html
参考:http://www.itnose.net/detail/6636559.html
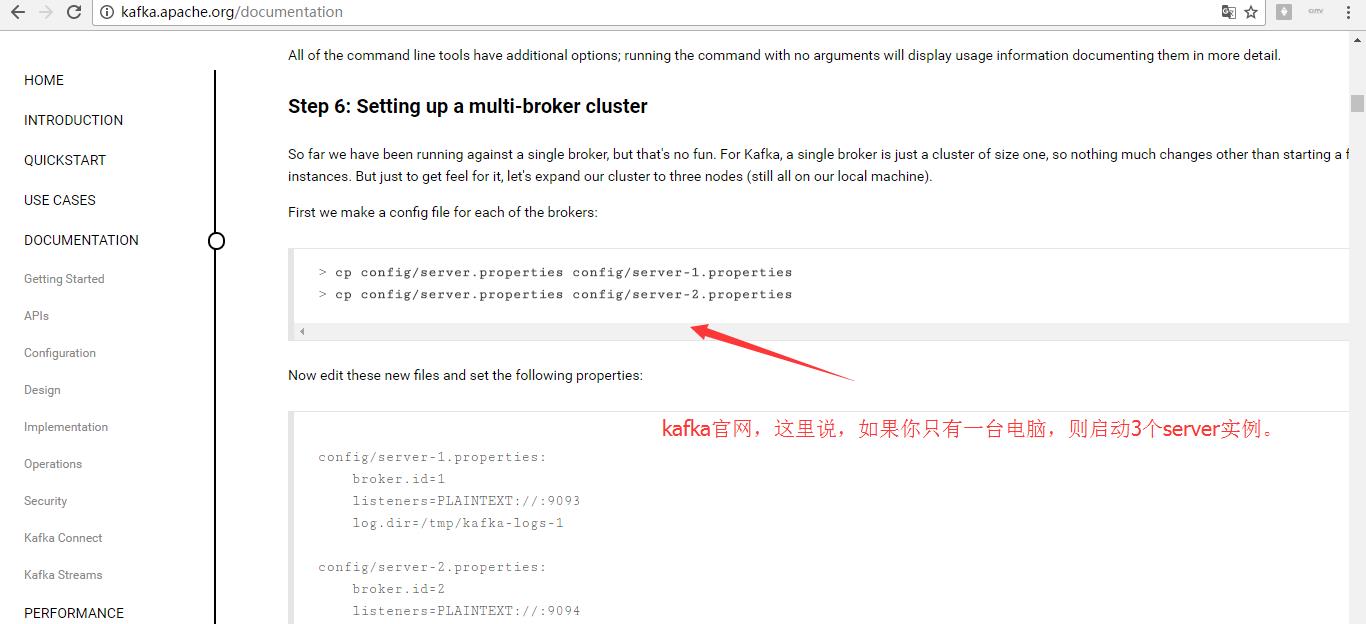
Step 6: Setting up a multi-broker cluster
So far we have been running against a single broker, but that\'s no fun. For Kafka, a single broker is just a cluster of size one, so nothing much changes other than starting a few more broker instances. But just to get feel for it, let\'s expand our cluster to three nodes (still all on our local machine).
First we make a config file for each of the brokers:
> cp config/server.properties config/server-1.properties
> cp config/server.properties config/server-2.properties
Now edit these new files and set the following properties:
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-2
The broker.id property is the unique and permanent name of each node in the cluster. We have to override the port and log directory only because we are running these all on the same machine and we want to keep the brokers from all trying to register on the same port or overwrite each others data.
We already have Zookeeper and our single node started, so we just need to start the two new nodes:
> bin/kafka-server-start.sh config/server-1.properties &
...
> bin/kafka-server-start.sh config/server-2.properties &
...
Now create a new topic with a replication factor of three:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
Okay but now that we have a cluster how can we know which broker is doing what? To see that run the "describe topics" command:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Here is an explanation of output. The first line gives a summary of all the partitions, each additional line gives information about one partition. Since we have only one partition for this topic there is only one line.
- "leader" is the node responsible for all reads and writes for the given partition. Each node will be the leader for a randomly selected portion of the partitions.
- "replicas" is the list of nodes that replicate the log for this partition regardless of whether they are the leader or even if they are currently alive.
- "isr" is the set of "in-sync" replicas. This is the subset of the replicas list that is currently alive and caught-up to the leader.
Note that in my example node 1 is the leader for the only partition of the topic.
We can run the same command on the original topic we created to see where it is:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
So there is no surprise there—the original topic has no replicas and is on server 0, the only server in our cluster when we created it.
Let\'s publish a few messages to our new topic:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
...
my test message 1
my test message 2
^C
Now let\'s consume these messages:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2
^C
Now let\'s test out fault-tolerance. Broker 1 was acting as the leader so let\'s kill it:
> ps | grep server-1.properties
7564 ttys002 0:15.91 /System/Library/Frameworks/JavaVM.framework/Versions/1.8/Home/bin/java...
> kill -9 7564
Leadership has switched to one of the slaves and node 1 is no longer in the in-sync replica set:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
But the messages are still be available for consumption even though the leader that took the writes originally is down:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2
^C
其实啊,一般都是kafka集群,在业务里,也没什么,改下kafka_2.10-0.8.1.1/config/下的配置文件server.properties,就好。

[hadoop@weekend110 config]$ pwd
/home/hadoop/app/kafka_2.10-0.8.1.1/config
[hadoop@weekend110 config]$ ll
total 32
-rw-rw-r--. 1 hadoop hadoop 1202 Apr 23 2014 consumer.properties
-rw-rw-r--. 1 hadoop hadoop 3828 Apr 23 2014 log4j.properties
-rw-rw-r--. 1 hadoop hadoop 2217 Apr 23 2014 producer.properties
-rw-rw-r--. 1 hadoop hadoop 5331 Oct 13 22:08 server.properties
-rw-rw-r--. 1 hadoop hadoop 3326 Apr 23 2014 test-log4j.properties
-rw-rw-r--. 1 hadoop hadoop 995 Apr 23 2014 tools-log4j.properties
-rw-rw-r--. 1 hadoop hadoop 1025 Oct 13 22:06 zookeeper.properties
[hadoop@weekend110 config]$ cp server.properties server-1.properties
[hadoop@weekend110 config]$ cp server.properties server-2.properties
[hadoop@weekend110 config]$ ll
total 48
-rw-rw-r--. 1 hadoop hadoop 1202 Apr 23 2014 consumer.properties
-rw-rw-r--. 1 hadoop hadoop 3828 Apr 23 2014 log4j.properties
-rw-rw-r--. 1 hadoop hadoop 2217 Apr 23 2014 producer.properties
-rw-rw-r--. 1 hadoop hadoop 5331 Oct 14 09:21 server-1.properties
-rw-rw-r--. 1 hadoop hadoop 5331 Oct 14 09:21 server-2.properties
-rw-rw-r--. 1 hadoop hadoop 5331 Oct 13 22:08 server.properties
-rw-rw-r--. 1 hadoop hadoop 3326 Apr 23 2014 test-log4j.properties
-rw-rw-r--. 1 hadoop hadoop 995 Apr 23 2014 tools-log4j.properties
-rw-rw-r--. 1 hadoop hadoop 1025 Oct 13 22:06 zookeeper.properties
[hadoop@weekend110 config]$

[hadoop@weekend110 config]$ vim server-1.properties
broker.id=1
log.dirs=/home/hadoop/data/kafka-logs-1
或者
log.dirs=/tmp/kafka-logs-1
port=9093

修改之后的结果:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see kafka.server.KafkaConfig for additional details and defaults
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
############################# Socket Server Settings #############################
# The port the socket server listens on
port=9093
# Hostname the broker will bind to. If not set, the server will bind to all interfaces
# host.name=localhost
# Hostname the broker will advertise to producers and consumers. If not set, it uses the
# value for "host.name" if configured. Otherwise, it will use the value returned from
# java.net.InetAddress.getCanonicalHostName().
#advertised.host.name=<hostname routable by clients>
# The port to publish to ZooKeeper for clients to use.
以上是关于4 kafka集群部署及生产者java客户端编程 + kafka消费者java客户端编程的主要内容,如果未能解决你的问题,请参考以下文章