数据结构详解
Posted Monster_起飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构详解相关的知识,希望对你有一定的参考价值。
数据结构的分类
我们在开发中,也都经常的用到数据结构,只是不是很在意这个名词,而是直接使用他们的另外的说法,比如:
- 数组
- 链表
- 堆
- 栈
上面的这四个数结构,可以统称为线性表。而除了线性表,我们还有其他的数据结构,比如散列表,树,还有图。
散列表有:
- hash
- 位图
树有:
- 二叉树
- 多路树
- 堆
图包含:
- 有向图
- 无向图
- 带权图
我们今天也别分析太多的内容,我们从最熟悉的入手,那么什么是我们最熟悉的呢?毫无疑问,那就是线性表中的内容,因为 数组,链表,堆,栈,这都是我们经常会在面试中遇到的,而且也是在代码中经常能够看到的,而有的同学会说,根本没用过,那这就是有点不太理解了,毕竟你用的都是上层的封装类,而不是具体的底层。
我们先说数组:
数组
数组(Array)是有限个相同类型的变量所组成的有序集合,数组中的每一个变量被称为元素。数组是 最为简单、最为常用的数据结构。
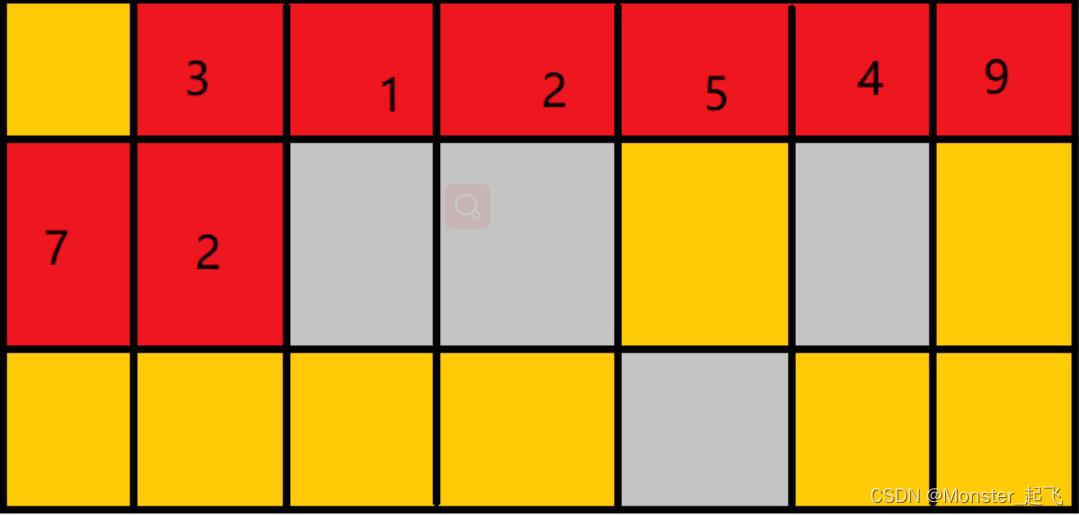
就比如下图,灰色标志的是被使用的内存,而红色格子表示的就是数组占用的连续内存,而黄色格子表示的就是空闲的内存。
上面这个图,就是数组在内存中的存储空间示意图,其实主要目的还是了不起想给大家说这个数组在内存中存储的时候,是一个连续的内存空间,不会出现隔一个格子出现一个。
而数组呢,可以根据下标随机访问数据,其实说随机,而此随机非彼随机。
他说随机,也只是说随机元素寻址,而不是说随机取数据。
比如我们的 int 是 4 字节,也就是(32位),实际上内存存储的是位
如果这时候随机元素寻址的话,
复制
int a[5]
1.
采用随机元素寻址,那么就是
复制
a[i]_address=a[0]_address+i*4
1.
那么我们就得知道这个操作这个数组的内存空间是都干了什么
第一步,读取元素
第二步更新元素
读取和更新都是可以随机访问的,时间复杂度大家可以猜测一下,欢迎在文章末尾回复。
那么插入元素的时候就会有三种情况了,尾部插入,中间插入,还有超范围的插入。
那么什么是尾部插入呢?
尾部插入
其实尾部茶壶如是最简单的实现方式,
在数据的实际元素数量小于数组长度的情况下:直接把插入的元素放在数组尾部的空闲位置即可,等同于更新元素的操作
中间插入
在数据的实际元素数量小于数组长度的情况下:由于数组的每一个元素都有其固定下标,所以首先把插入位置及后面的元素向后移动,腾出地方, 再把要插入的元素放到对应的数组位置上。
超范围插入
假如现在有一个数组,已经装满了元素,这时还想插入一个新元素,或者插入位置是越界的 这时就要对原数组进行扩容:可以创建一个新数组,长度是旧数组的2倍,再把旧数组中的元素统 统复制过去,这样就实现了数组的扩容。
那么使用数组的优缺点都有什么呢?
数组的优缺点
优点:
数组拥有非常高效的随机访问能力,只要给出下标,就可以用常量时间找到对应元素
缺点:
插入和删除元素方面。由于数组元素连续紧密地存储在内存中,插入、删除元素都会导致大量元素被迫 移动,影响效率。(ArrayList LinkedList ) 申请的空间必须是连续的,也就是说即使有空间也可能因为没有足够的连续空间而创建失败。
如果超出范围,需要重新申请内存进行存储,原空间就浪费了
一般的,数组是基础的数据结构,应用太广泛了,ArrayList、Redis、消息队列等等,这些都是使用了数组这种数据结构,这种数据结构也是在面试的时候经常会和其他的数据结构拿出来做对比的,关于这个数据结构的数组。
以上是关于数据结构详解的主要内容,如果未能解决你的问题,请参考以下文章