java 实现word关键字在网上的搜索
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java 实现word关键字在网上的搜索相关的知识,希望对你有一定的参考价值。
您们好,我想问一下如何用java实现一个将word中的关键字自动的在网络上的一些网页文章进行匹配,并且将相关度大的网页网址记录在txt文档中。
需要用到爬虫吗?爬虫爬的是什么呢?是网页还是网址?这个过程用到的java 工具包有哪些呢?
lucene,poi,htmaparse这三个有用吗?还需要哪些?
麻烦请告知,十分感谢!(不需要代码,如果可以请推荐一些包和相关方法,是否需要爬虫(很关键的!))注:目前还没有学到jsp,单单用SE能解决吗?
尼玛,百度这个垃圾的无赖行径!!!
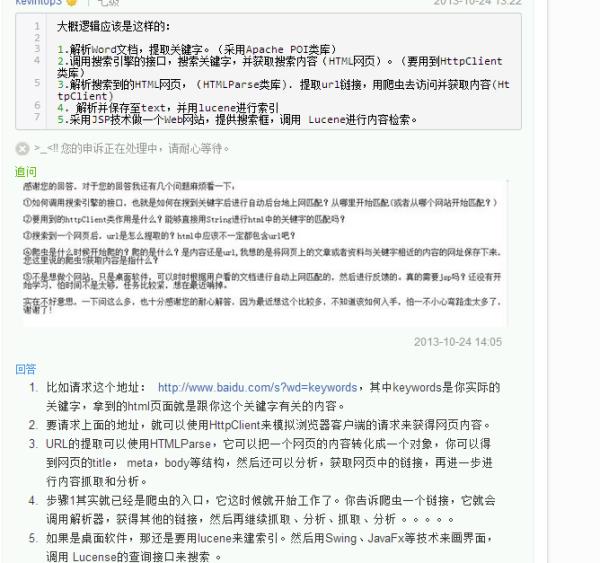

您好,感谢您的回答。
您说到爬虫爬的是固定的URL,如果我想在关键字提取的基础上,进行网上的各种搜索和匹配次关键字的网页然后将符合的网页的URL提取下来该怎么做呢?
也就是说爬虫智能根据url来爬网页内容而不能根据内容来爬url吗?
通常按照我的理解,爬虫是一个客户端,而网页是服务端反馈客户端给予的内容,经过客户端浏览器解析后显示为网页了,那么也就是说发起端是在客户端,在没有服务器反馈内容的情况下,又去何处搜索关键字呢?也就是说没有数据,自然就无法查询了。所以限定一个url范围是搜索关键字的前提,然后根据设定的规则遍历范围内的全部url,这样才能实现爬虫的效果。当然,你所说的word中的关键字搜索还可以采用另外一种变通的方式,举个例子,你可以将这个字符串通过百度搜索,反馈的网页,再用这些网页作为数据源去爬更多的内容,发散式搜索,但这样将会产生庞大的数据量,必须定义好规则才能确保你最终需要的数据能够获得,比如百度查询"美食"会列出很多网页,而你则要去解析百度的网页,并将所需的网页内容获得出来。
参考技术B 红果果凤飞飞以上是关于java 实现word关键字在网上的搜索的主要内容,如果未能解决你的问题,请参考以下文章