Java面试05|MySQL及InnoDB引擎
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java面试05|MySQL及InnoDB引擎相关的知识,希望对你有一定的参考价值。
1、InnoDB引擎索引
InnoDB支持的索引有以下几种:
(1)哈希索引
(2)全文索引
(1)B+树索引 又可以分为聚集索引与辅助索引
索引的创建可以在CREATE TABLE语句中进行,也可以单独用CREATE INDEX或ALTER TABLE来给表增加索引。删除索引可以利用ALTER TABLE或DROP INDEX语句来实现。
(1)使用ALTER TABLE语句创建索引。
语法如下:
alter table table_name add index index_name (column_list) ; alter table table_name add unique (column_list) ; alter table table_name add primary key (column_list) ;
其中包括普通索引、UNIQUE索引和PRIMARY KEY索引3种创建索引的格式,table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。索引名index_name可选,缺省时,mysql将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以同时创建多个索引。
创建索引的示例如下:
mysql> alter table table_test add index index_test1(name) ; Query OK, 2 rows affected (0.08 sec)
(2)使用CREATE INDEX语句对表增加索引。
能够增加普通索引和UNIQUE索引两种。其格式如下:
create index index_name on table_name (column_list) ; create unique index index_name on table_name (column_list) ;
创建索引的示例如下:
mysql>create index index_test2 on table_test(age); Query OK, 2 rows affected (0.08 sec)
说明:table_name、index_name和column_list具有与ALTER TABLE语句中相同的含义,索引名不可选。另外,不能用CREATE INDEX语句创建PRIMARY KEY索引。
(3)删除索引
删除索引可以使用ALTER TABLE或DROP INDEX语句来实现。DROP INDEX可以在ALTER TABLE内部作为一条语句处理,其格式如下:
drop index index_name on table_name ; alter table table_name drop index index_name ; alter table table_name drop primary key ;
其中,在前面的两条语句中,都删除了table_name中的索引index_name。而在最后一条语句中,只在删除PRIMARY KEY索引中使用,因为一个表只可能有一个PRIMARY KEY索引,因此不需要指定索引名。如果没有创建PRIMARY KEY索引,但表具有一个或多个UNIQUE索引,则MySQL将删除第一个UNIQUE索引。
如果从表中删除某列,则索引会受影响。对于多列组合的索引,如果删除其中的某列,则该列也会从索引中删除。如果删除组成索引的所有列,则整个索引将被删除。
删除索引的操作,如下面的代码:
mysql> drop index name on table_test ; Query OK, 2 rows affected (0.08 sec)
2、建立索引的几大原则
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
3.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
3、MySQL的几种优化
参考《构建高性能Web站点》第11章 数据库性能优化
(1)建立索引
根据预计的数据量和查询来设计索引,关于索引的选择,应该注意:
A、根据数据量决定哪些表需要增加索引,数据量小的可以只有主键
B、根据使用频率决定哪些字段需要建立索引,选择经常作为连接条件、筛选条件、聚合查询、排序的字段作为索引的候选字段
C、把经常一起出现的字段组合在一起,组成组合索引,组合索引的字段顺序与主键一样,也需要把最常用的字段放在前面,把重复率低的字段放在前面(注意索引的顺序)
D、一个表不要加太多索引,因为索引影响插入和更新的速度,因为 insert 或 update 时有可能会重建索引
(2)表数据字段的冗余(反范式)
(3)表的设计 垂直与水平分表,垂直分库与水平分库
表的垂直拆分
可以参阅文章:一分钟掌握数据库垂直拆分 http://mp.weixin.qq.com/s/ezD0CWHAr0RteC9yrwqyZA
随着需求越来越多,某一张表的列越来越增加,为了控制表的宽度可以进行表的垂直拆分。 将表进行垂直拆分:
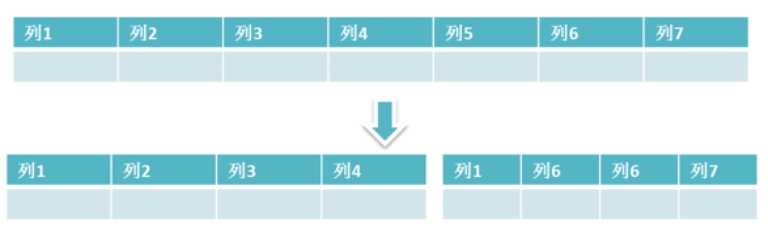
原因:数据库以页存储,表越宽,每一行的数据越大,一页中所能存储的行数就会越来越少。拆分成多张窄表,每一张表中所含长度不会大,优化了IO效率。
原则:
原来一张大表有上亿数据,需要减少表中的数据量,为了控制表的大小可以进行表的水平拆分。 将表进行水平拆分:
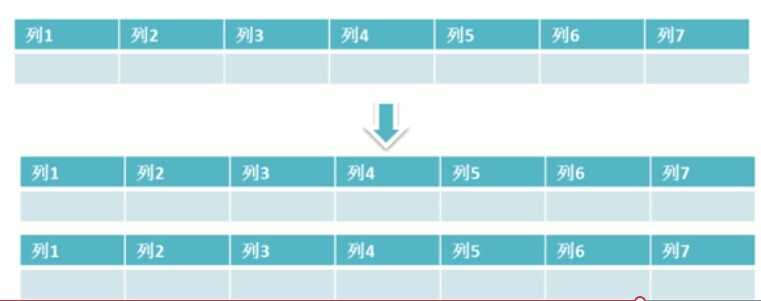
那么如何把一张大表中的数据,分配到多张小表中呢?拆分可以按照Hash方式,如下图:
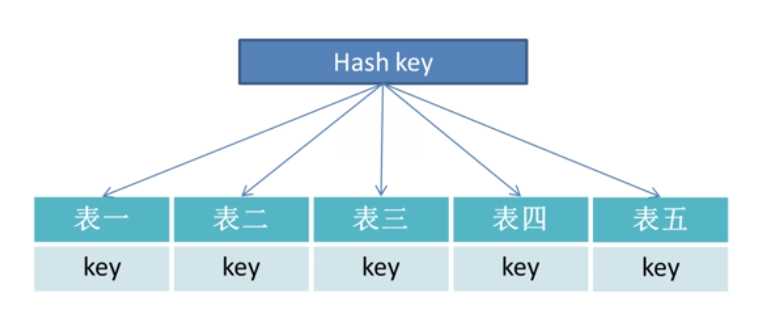
每一张表都拥有一个主键值,通过对主键值进行哈希操作,比如说主键按摩取值,把一张大表平均分配到几张小表中,解决了表中数据量的问题。
3、MySQL常用函数
convert()
cast()
truncate() 截断小数
round() 四舍五入
lower()/upper() 把参数变为大小写
length() 求参数的长度
concat(参数1,参数2): 把参数1和参数2连接起来
floor(参数):返回小于或等于参数的最大整数
ceil(参数):返回大于或等于参数的最小整数
abs(参数):求参数的绝对值
mod(参数1,参数2): 求参数1除以参数2后的余数
substr(x,start ,[length]) 取子串
if()
ifnull()
date_format()
聚合函数有:
count() 求该字段的总记录
min()/max() 求字段的最小最大值
sum() 求该字段的和
avg() 求平均
group_concat() 迭代分组后中的每个数据行
4、MySQL数据库插入和删除一条数据的过程在底层是如何执行的?
MySQL的加锁, 锁是作用于索引的,行级锁都是基于索引的。只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
分析时主要涉及到的点:
(1)WHERE条件的拆分
(2)关于索引与事务隔离级别的组合
参考:
(1)mysql事务和锁InnoDB http://www.cnblogs.com/zhaoyl/p/4121010.html
(2)http://www.cnblogs.com/exceptioneye/p/5450874.html
5、MySQL的事务是如何实现的?
事务有ACID属性,所以就是如何保证这几个特性就可以实现事务。
(1)隔离性由锁来保证。一个事务在操作过程中看到了其他事务的结果,如幻读。锁是用于解决隔离性的一种机制。事务的隔离级别通过锁的机制来实现。
(2)一致性由undo log来保证,可以做事务回滚和MVCC的功能。
(3)原子性与持久性由redo log来保证。事务在提交时,必须将该事务的所有日志写入重做日志文件进行持久化。
6、MySQL的事务及其隔离级别
数据库的事务隔离级别有(多个事务并发的情况下):
1、read uncommitted
#首先,修改隔离级别
set tx_isolation=‘READ-UNCOMMITTED‘;
select @@tx_isolation;
+------------------+
| @@tx_isolation |
+------------------+
| READ-UNCOMMITTED |
+------------------+
#事务A:启动一个事务
start transaction;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+
#事务B:也启动一个事务(那么两个事务交叉了)
在事务B中执行更新语句,且不提交
start transaction;
update tx set num=10 where id=1;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+
#事务A:那么这时候事务A能看到这个更新了的数据吗?
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 | --->可以看到!说明我们读到了事务B还没有提交的数据
| 2 | 2 |
| 3 | 3 |
+------+------+
#事务B:事务B回滚,仍然未提交
rollback;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+
#事务A:在事务A里面看到的也是B没有提交的数据
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 | --->脏读意味着我在这个事务中(A中),事务B虽然没有提交,但它任何一条数据变化,我都可以看到!
| 2 | 2 |
| 3 | 3 |
+------+------+
2、read committed
#首先修改隔离级别
set tx_isolation=‘read-committed‘;
select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| READ-COMMITTED |
+----------------+
#事务A:启动一个事务
start transaction;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
+------+------+
#事务B:也启动一个事务(那么两个事务交叉了)在这事务中更新数据,且未提交
start transaction;
update tx set num=10 where id=1;
select * from tx;
+------+------+
| id | num |
+------+------+
| 1 | 10 |
| 2 | 2 |
| 3 | 3 |
+------+------+
#事务A:这个时候我们在事务A中能看到数据的变化吗?
select * from tx; ------------->
+------+------+ |
| id | num | |
+------+------+ |
| 1 | 1 |--->并不能看到! |
| 2 | 2 | |
| 3 | 3 | |
+------+------+ |——>相同的select语句,结果却不一样
|
#事务B:如果提交了事务B呢? |
commit; |
|
#事务A: |
select * from tx; ------------->
+------+------+
| id | num |
+------+------+
| 1 | 10 |--->因为事务B已经提交了,所以在A中我们看到了数据变化
| 2 | 2 |
| 3 | 3 |
+------+------+
3、repeatable read
#首先,更改隔离级别 set tx_isolation=‘repeatable-read‘; select @@tx_isolation; +-----------------+ | @@tx_isolation | +-----------------+ | REPEATABLE-READ | +-----------------+ #事务A:启动一个事务 start transaction; select * from tx; +------+------+ | id | num | +------+------+ | 1 | 1 | | 2 | 2 | | 3 | 3 | +------+------+ #事务B:开启一个新事务(那么这两个事务交叉了) 在事务B中更新数据,并提交 start transaction; update tx set num=10 where id=1; select * from tx; +------+------+ | id | num | +------+------+ | 1 | 10 | | 2 | 2 | | 3 | 3 | +------+------+ commit; #事务A:这时候即使事务B已经提交了,但A能不能看到数据变化? select * from tx; +------+------+ | id | num | +------+------+ | 1 | 1 | --->还是看不到的!(这个级别2不一样,也说明级别3解决了不可重复读问题) | 2 | 2 | | 3 | 3 | +------+------+ #事务A:只有当事务A也提交了,它才能够看到数据变化 commit; select * from tx; +------+------+ | id | num | +------+------+ | 1 | 10 | | 2 | 2 | | 3 | 3 | +------+------+
4、serializable
#首先修改隔离界别 set tx_isolation=‘serializable‘; select @@tx_isolation; +----------------+ | @@tx_isolation | +----------------+ | SERIALIZABLE | +----------------+ #事务A:开启一个新事务 start transaction; #事务B:在A没有commit之前,这个交叉事务是不能更改数据的 start transaction; insert tx values(‘4‘,‘4‘); ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction update tx set num=10 where id=1; ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
总结一下:
√: 可能出现 ×: 不会出现
| 事务的隔离级别 | 脏读 事务1更新了记录,但没有提交,事务2读取了更新后的行,然后事务T1回滚,现在T2读取无效。违反隔离性导致的问题,添加行锁实现 | 不可重复读 事务1读取记录时,事务2更新了记录并提交,事务1再次读取时可以看到事务2修改后的记录(修改批更新或者删除)需要添加行锁进行实现 |
幻读 事务1读取记录时事务2增加了记录并提交,事务1再次读取时可以看到事务2新增的记录。需要添加表锁进行实现。InnoDB存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题 |
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable read | × | × | √ |
| Serializable | × | × | × |
对应着Spring中的5个事务隔离级别(通过lsolation的属性值指定)
1、default 默认的事务隔离级别。使用的是数据库默认的事务隔离级别
2、read_uncommitted 读未提交,一个事务可以操作另外一个未提交的事务,不能避免脏读,不可重复读,幻读,隔离级别最低,并发性能最高
3、read_committed(脏读) 大多数数据库默认的事务隔离级别。读已提交,一个事务不可以操作另外一个未提交的事务, 能防止脏读,不能避免不可重复读,幻读
4、repeatable_read(不可重复读) innodb默认的事务隔离级别。能够避免脏读,不可重复读,不能避免幻读
5、serializable(幻读) innodb存储引擎在这个级别才能有分布式XA事务的支持。隔离级别最高,消耗资源最低,代价最高,能够防止脏读, 不可重复读,幻读
7、数据库范式与反范式
1、范式
数据库逻辑设计的规范化就是我们一般所说的范式,我们可以这样来简单理解范式:
(1)第一范式(确保每列保持原子性)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如 某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式。
(2)第二范式(确保表中的每列都和主键相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
订单信息表
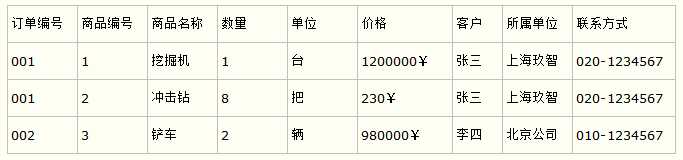
这样就产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。
而如果把这个订单信息表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。
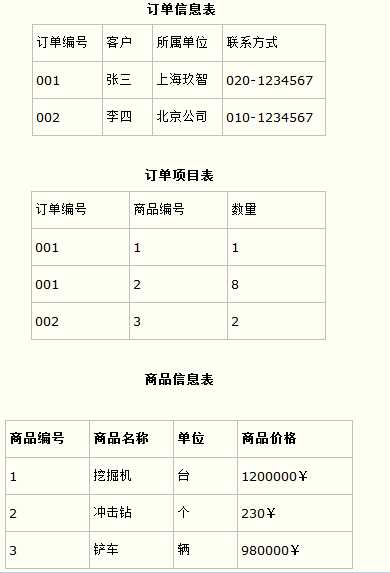
(3)第三范式(确保每列都和主键列直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。如下面这两个表所示的设计就是一个满足第三范式的数据库表。
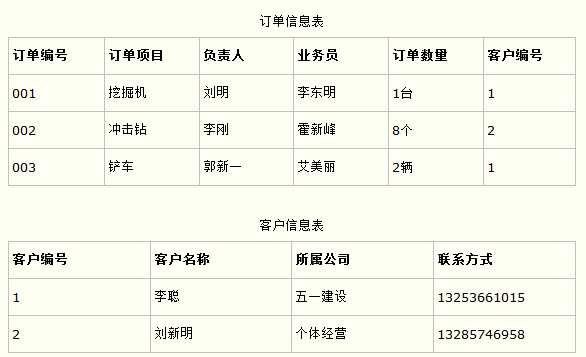
这样在查询订单信息的时候,就可以使用客户编号来引用客户信息表中的记录,也不必在订单信息表中多次输入客户信息的内容,减小了数据冗余。
更高的范式要求这里就不再作介绍了,个人认为,如果全部达到第二范式,大部分达到第三范式,系统会产生较少的列和较多的表,因而减少了数据冗余,也利于性能的提高。
完全按照规范化设计的系统几乎是不可能的,除非系统特别的小,在规范化设计后,有计划地加入冗余是必要的。
从性能角度来说,冗余数据库可以分散数据库压力,冗余表可以分散数据量大的表的并发压力,也可以加快特殊查询的速度,冗余字段可以有效减少数据库表的连接,提高效率。
2、反范式
通过适当的数据冗余,来提高读的效率
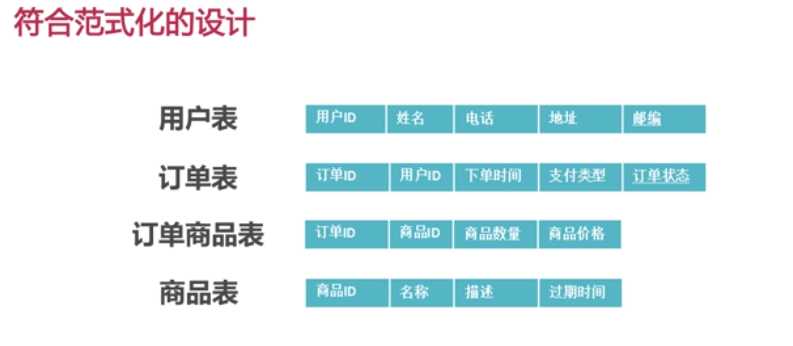
如何查询订单详情信息?
SELECT b.用户名, b.电话, b.地址, a.订单ID, sum(c.商品价格* c.商品数量)AS 订单价格, c.商品价格, d.商品名称 FROM ‘订单表‘ a JOIN ‘用户表‘ b ON a.用户ID = b.用户ID JOIN ‘订单商品表‘ c ON c.订单ID = b.订单ID JOIN ‘商品表‘ d ON d.商品ID = c.商品ID GROUP BY b.用户名,b.电话,b.地址,a.订单ID,c.商品价格,d.商品名称
该查询需要关联多张表,然后再通过sum汇总出价格,查询效率不太高。 如果通过表中部分数据的冗余,进行反范式化设计,如下图:

简化sql的查询
SELECT b.用户名, b.电话, b.地址, a.订单ID, a.订单价格, c.商品价格, c.商品名称 FROM ‘订单表‘ a JOIN ‘用户表‘ b ON a.用户ID = b.用户ID JOIN ‘订单商品表‘ c ON c.订单ID = b.订单ID
互联网项目中,读写比率大概是3:1或是4:1的关系,读远远高于写,写的时候增加数据冗余,增加了读的效率,这样还是很值得的。
反范式的目的是减少读取数据的开销,那么随之带来的就是更多写数据的开销。因为我们需要预先定稿大量的数据副本。
反范式还会带来数据的不一致,可以通过异步的写来进行定期数据整理,修复不一致的数据。
必看文章:细聊冗余表数据一致性(架构师之路) http://www.jianshu.com/p/65743dc5bdea
以上是关于Java面试05|MySQL及InnoDB引擎的主要内容,如果未能解决你的问题,请参考以下文章