Hadoop基础之《—整合HBase+Phoenix+Hive》
Posted csj50
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop基础之《—整合HBase+Phoenix+Hive》相关的知识,希望对你有一定的参考价值。
一、HBase简介
1、HBase定义
Apache HBase是以HDFS为数据存储的,一种分布式、可扩展的NoSQL数据库(非关系型,以k,v的形式存储数据)。
HBase可以认为是以HDFS为存储的数据库。
2、HBase数据模型
(1)HBase的设计理念依据Google的BigTable论文,论文中对于数据模型的首句介绍:
Bigtable是一个稀疏的、分布式的、持久的多维排序map(代码里的hashmap是单维的,并且一定是有序的)。
(2)之后对于映射的解释如下:
该映射由行键、列键和时间戳索引;映射中的每个值都是一个未解释的字节数组。
(3)最终HBase关于数据模型和BigTable的对应关系如下:
HBase使用与Bigtable非常相似的数据模型。用户将数据行存储在带标签的表中。数据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列。
(4)最终理解HBase数据模型的关键在于稀疏、分布式、多维、排序的映射。其中映射map指代非关系型数据库的key-value结构。
二、HBase逻辑结构
1、存储数据稀疏,原数据有留空的部分。
2、数据存储多维,不同的行具有不同的列。
3、数据存储整体有序,按照RowKey的字典序排列,RowKey为Byte数组。
4、列、列族、Row key
row key是按照字典顺序排序的。
5、按照行进行拆分
拆分出Region,它会有对应的row key的一个范围。每个Region的row key范围不交叉。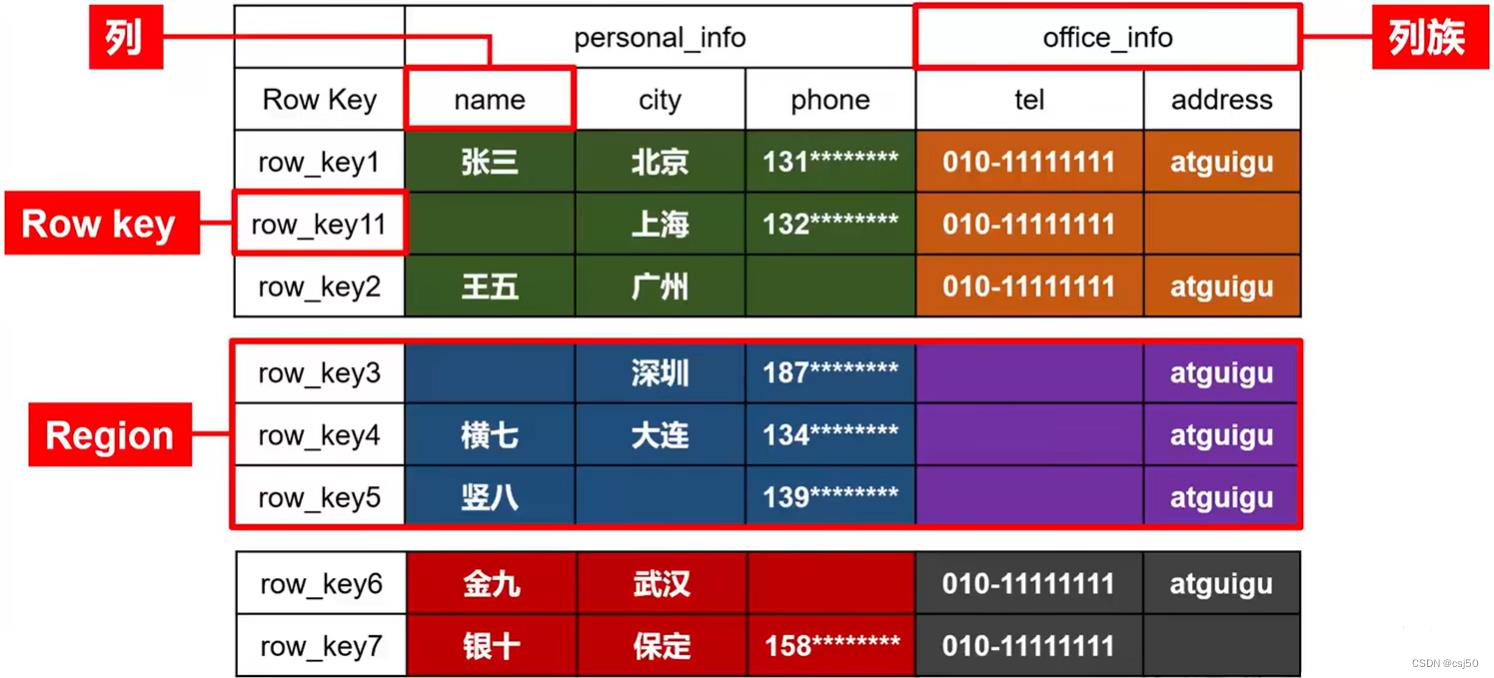
将表格按照行拆分,块名称为Region,用于实现分布式结构。
6、竖着进行拆分
拆分出来的叫store。以列族为单位。
按照列族切分为store用于底层存储到不同的文件夹中,便于文件对应。
三、HBase物理存储结构
1、物理结构
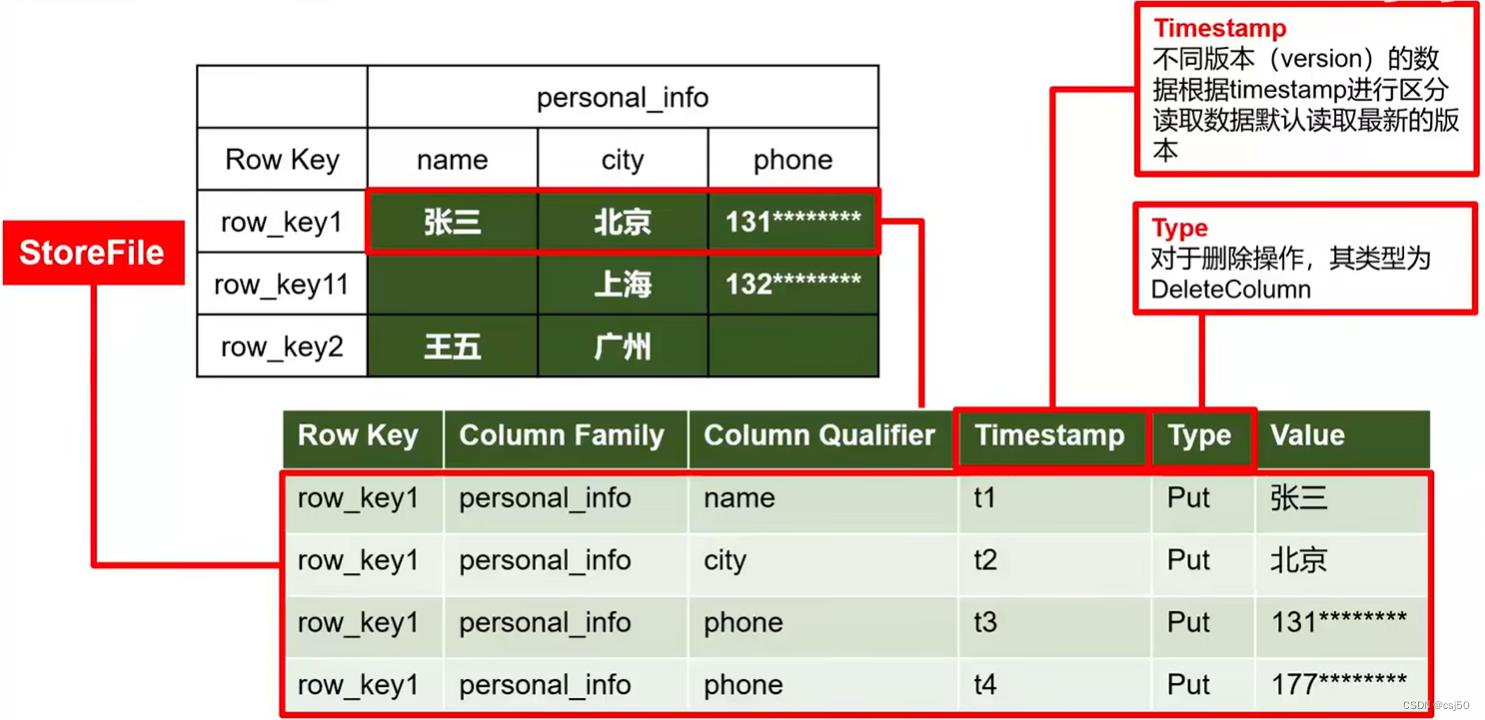
物理存储结构即为数据映射关系,而在概念视图的空单元格,底层实际根本不存储。
列是:Row Key + 列族 + 列名 + 时间戳。
HDFS有一个特点,不能修改数据,只能删除、重写、追加写。
HBase要在不能改数据的基础上,实现改数据的功能,如何实现——以时间戳标记不同的版本。实际上删除、重写、追加写也是加标记。
四、数据模型概念
1、Name Space
命名空间,类似于关系型数据库的database概念,每个命名空间下有多个表。HBase两个自带的命名空间,分别是hbase和default。hbase存放的是HBase内置的表,default表是用户默认使用的命名空间。
以上是关于Hadoop基础之《—整合HBase+Phoenix+Hive》的主要内容,如果未能解决你的问题,请参考以下文章