Java的数据结构相关的类实现
Posted coder为
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java的数据结构相关的类实现相关的知识,希望对你有一定的参考价值。
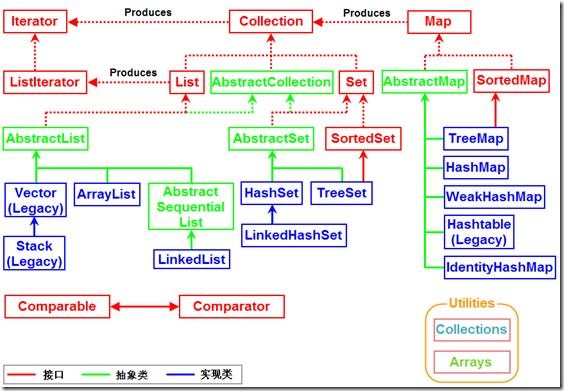
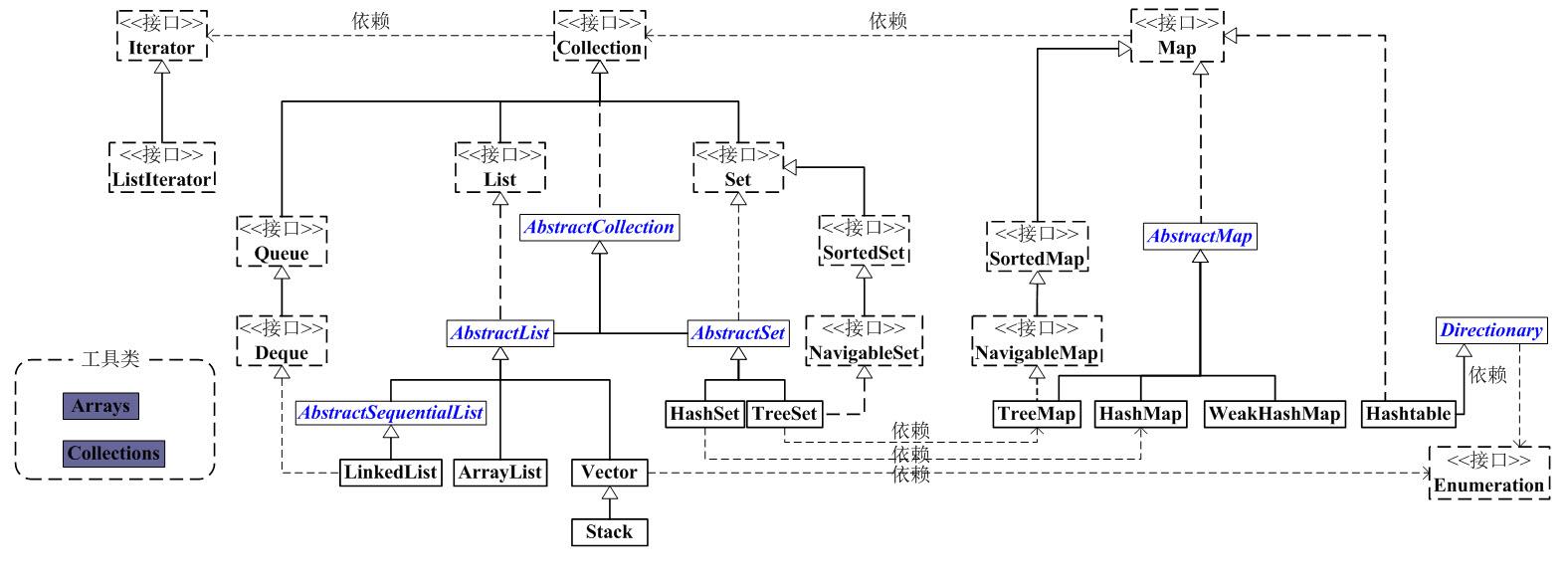
看上面的框架图,先抓住它的主干,即Collection和Map。
1 Collection是一个接口,是高度抽象出来的集合,它包含了集合的基本操作和属性。
Collection包含了List和Set两大分支。
(01) List是一个有序的队列,每一个元素都有它的索引。第一个元素的索引值是0。
List的实现类有LinkedList, ArrayList, Vector, Stack。
(02) Set是一个不允许有重复元素的集合。
Set的实现类有HastSet和TreeSet。HashSet依赖于HashMap,它实际上是通过HashMap实现的;TreeSet依赖于TreeMap,它实际上是通过TreeMap实现的。
2 Map是一个映射接口,即key-value键值对。Map中的每一个元素包含“一个key”和“key对应的value”。
AbstractMap是个抽象类,它实现了Map接口中的大部分API。而HashMap,TreeMap,WeakHashMap都是继承于AbstractMap。
Hashtable虽然继承于Dictionary,但它实现了Map接口。
接下来,再看Iterator。它是遍历集合的工具,即我们通常通过Iterator迭代器来遍历集合。我们说Collection依赖于Iterator,是因为Collection的实现类都要实现iterator()函数,返回一个Iterator对象。
ListIterator是专门为遍历List而存在的。
再看Enumeration,它是JDK 1.0引入的抽象类。作用和Iterator一样,也是遍历集合;但是Enumeration的功能要比Iterator少。在上面的框图中,Enumeration只能在Hashtable, Vector, Stack中使用。
最后,看Arrays和Collections。它们是操作数组、集合的两个工具类。
Iterable:
public interface Iterable<T>
迭代器接口,是Collection接口的父接口。Implementing this interface allows an object to be the target of the "foreach" statement. 也就是说,所有的Collection集合对象都具有foreach可遍历性。
Collection:
public interface Collection<E>
extends Iterable<E>
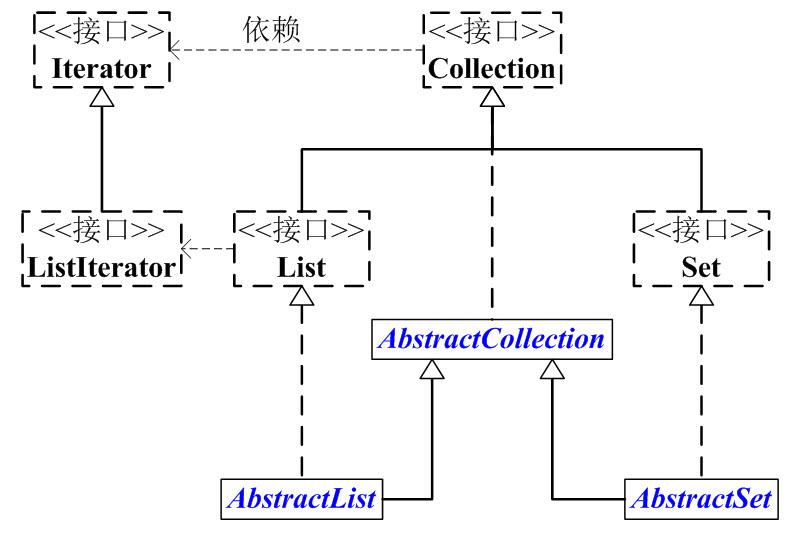
是集合层级结构的根接口, 是高度抽象出来的集合,它包含了集合的基本操作和属性。一个collection代表一组object,也称为元素。有些collections允许重复元素,有些不允许。有些collections是有序的,有些是无序的。JDK没有提供这个接口的直接实现,而是提供了一些更具体的子接口,如Set,List。
另外,Collection中有一个iterator()函数,它的作用是返回一个Iterator接口。通常,我们通过Iterator迭代器来遍历集合。
Iterator的定义如下:
public interface Iterator<E> {}
Iterator是一个接口,它是集合的迭代器。集合可以通过Iterator去遍历集合中的元素。Iterator提供的API接口,包括:是否存在下一个元素、获取下一个元素、删除当前元素。
注意:Iterator遍历Collection时,是fail-fast机制的。即,当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出ConcurrentModificationException异常,产生fail-fast事件。
// Iterator的API abstract boolean hasNext() abstract E next() abstract void remove()
AbstractCollection:
public abstract class AbstractCollection<E>
extends Object
implements Collection<E>
为了方便,我们抽象出了AbstractCollection抽象类,它实现了Collection中的绝大部分函数;这样,在Collection的实现类中,我们就可以通过继承AbstractCollection省去重复编码。AbstractList和AbstractSet都继承于AbstractCollection,具体的List实现类继承于AbstractList,而Set的实现类则继承于AbstractSet。
List
public interface List<E>
extends Collection<E>
List像是一个竹筒。集合代表一个元素有序、可重复的集合,集合中每个元素都有其对应的顺序索引。List集合允许加入重复元素,因为它可以通过索引来访问指定位置的集合元素。List集合默认按元素的添加顺序设置元素的索引.
ListIterator是List接口所特有的,在List接口中,通过ListIterator()返回一个ListIterator对象。
ListIterator的定义如下:
public interface ListIterator<E> extends Iterator<E> {}
ListIterator是一个继承于Iterator的接口,它是队列迭代器。专门用于遍历List,能提供向前/向后遍历。相比于Iterator,它新增了添加、是否存在上一个元素、获取上一个元素等等API接口。
如果涉及到“栈”、“队列”、“链表”等操作,应该考虑用List,具体的选择哪个List,根据下面的标准来取舍。
(01) 对于需要快速插入,删除元素,应该使用LinkedList。
(02) 对于需要快速随机访问元素,应该使用ArrayList。
(03) 对于“单线程环境” 或者 “多线程环境,但List仅仅只会被单个线程操作”,此时应该使用非同步的类(如ArrayList)。
对于“多线程环境,且List可能同时被多个线程操作”,此时,应该使用同步的类。
AbstractList
public abstract class AbstractList<E>
extends AbstractCollection<E>
implements List<E>
This class provides a skeletal implementation of the List interface to minimize the effort required to implement this interface backed by a "random access" data store (such as an array). For sequential access data (such as a linked list), AbstractSequentialList should be used in preference to this class.
AbstractSequentialList
public abstract class AbstractSequentialList<E>
extends AbstractList<E>
This class provides a skeletal implementation of the List interface to minimize the effort required to implement this interface backed by a "sequential access" data store (such as a linked list). For random access data (such as an array), AbstractList should be used in preference to this class.
ArrayList:
public class ArrayList<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, Serializable
基于数组实现的List,可以通过索引随机访问。它封装了一个动态增长的,允许再分配的Object[] 数组。ArrayList 是一个数组队列,相当于 动态数组。与Java中的数组相比,它的容量能动态增长。
ArrayList 实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在ArrayList中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。
可被克隆,可被序列化。
和Vector不同,ArrayList中的操作不是线程安全的!所以,建议在单线程中才使用ArrayList,而在多线程中可以选择Vector或者CopyOnWriteArrayList。
ArrayList包含了两个重要的对象:elementData 和 size。
(01) elementData 是"Object[]类型的数组",它保存了添加到ArrayList中的元素。实际上,elementData是个动态数组,我们能通过构造函数 ArrayList(int initialCapacity)来执行它的初始容量为initialCapacity;如果通过不含参数的构造函数ArrayList()来创建ArrayList,则elementData的容量默认是10。elementData数组的大小会根据ArrayList容量的增长而动态的增长,具体的增长方式,请参考源码分析中的ensureCapacity()函数。
(02) size 则是动态数组的实际大小。
总结:
(01) ArrayList 实际上是通过一个数组去保存数据的。当我们构造ArrayList时;若使用默认构造函数,则ArrayList的默认容量大小是10。
(02) 当ArrayList容量不足以容纳全部元素时,ArrayList会grow,int newCapacity = oldCapacity + (oldCapacity >> 1);。
(03) ArrayList的克隆函数,即是将全部元素克隆到一个数组中。
(04) ArrayList实现java.io.Serializable的方式。当写入到输出流时,先写入“容量”,再依次写入“每一个元素”;当读出输入流时,先读取“容量”,再依次读取“每一个元素”。
ArrayList支持3种遍历方式
(01) 第一种,通过迭代器遍历。即通过Iterator去遍历。
Integer value = null;
Iterator iter = list.iterator();
while (iter.hasNext()) {
value = (Integer)iter.next();
}
(02) 第二种,随机访问,通过索引值去遍历。
由于ArrayList实现了RandomAccess接口,它支持通过索引值去随机访问元素。
Integer value = null;
int size = list.size();
for (int i=0; i<size; i++) {
value = (Integer)list.get(i);
}
(03) 第三种,for循环遍历。如下:
Integer value = null;
for (Integer integ:list) {
value = integ;
}
遍历ArrayList时,使用随机访问(即,通过索引序号访问)效率最高,而使用迭代器的效率最低!
Vector
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, Serializable
方法和ArrayList完全一样,不同在于Vector中的操作是线程安全的,读取和插入都加了synchronized。
Vector的api描述是:从jdk 1.2版本开始,该类被修正为实现List接口,并成为Java Collection集合框架的一员,区别于其他一些新的集合实现类,Vector是线程安全的。如果是一个线程安全的实现,推荐使用ArrayList代替Vector。
为什么Vector被淘汰?
Vector synchronizes on each individual operation. That\'s almost never what you want to do.
Generally you want to synchronize a whole sequence of operations. Synchronizing individual operations is both less safe (if you iterate over a Vector, for instance, you still need to take out a lock to avoid anyone else changing the collection at the same time, which would cause a ConcurrentModificationException in the iterating thread) but also slower (why take out a lock repeatedly when once will be enough)?
Of course, it also has the overhead of locking even when you don\'t need to.
Basically, it\'s a very flawed approach to synchronization in most situations. As Mr Brian Henkpointed out, you can decorate a collection using the calls such as Collections.synchronizedList - the fact that Vector combines both the "resized array" collection implementation with the "synchronize every operation" bit is another example of poor design; the decoration approach gives cleaner separation of concerns.
As for a Stack equivalent - I\'d look at Deque/ArrayDeque to start with.
Vector为get()和set()加了锁,当一个线程在遍历某个vector,另一个线程也在遍历这个vector并修改其中的内容时,并不能保证线程安全,而是会抛出ConcurrentModificationException,并且速度会特别慢。由于这样的缺点,导致Vector并不是所谓的线程安全,所以被淘汰。
总结:
(01) Vector实际上是通过一个数组去保存数据的。当我们构造Vecotr时;若使用默认构造函数,则Vector的默认容量大小是10。
(02) 当Vector容量不足以容纳全部元素时,Vector的容量会增加。若容量增加系数 >0,则将容量的值增加“容量增加系数”;否则,将容量大小增加一倍。
(03) Vector的克隆函数,即是将全部元素克隆到一个数组中。
Vector vs ArrayList
相同之处:
1,都是List。都继承AbstractList,并都实现List
2,都实现了RandomAccess和Cloneable接口,都实现了Serializable接口。
3,都是通过数组实现的,本质上都是动态数组。
4,默认数组容量都是10。
5,都支持Iterator和listIterator
不同之处:
1,线程安全性不一样,ArrayList是非线程安全的,Vector是线程安全的,它的函数都是synchronized,ArrayList适合单线程,Vector适合多线程。
2,构造函数个数不同,ArrayList有3个构造函数,而Vector有4个构造函数。Vector除了包括和ArrayList类似的3个构造函数之外,另外的一个构造函数可以指定容量增加系数。
3,容量增加方式不同,ArrayList:newCap = oldCap + (oldCap>>1); Vector: 容量增长与“增长系数有关”,若指定了“增长系数”,且“增长系数有效(即,大于0)”;那么,每次容量不足时,“新的容量”=“原始容量+增长系数”。若增长系数无效(即,小于/等于0),则“新的容量”=“原始容量 x 2”。
4, 对Enumeration的支持不同。Vector支持通过Enumeration去遍历,而ArrayList不允许。
Stack:
public class Stack<E>
extends Vector<E>
用于模拟LIFO后进先出的栈操作。
总结:
(01) Stack实际上也是通过数组去实现的。
执行push时(即,将元素推入栈中),是通过将元素追加的数组的末尾中。
执行peek时(即,取出栈顶元素,不执行删除),是返回数组末尾的元素。
执行pop时(即,取出栈顶元素,并将该元素从栈中删除),是取出数组末尾的元素,然后将该元素从数组中删除。
(02) Stack继承于Vector,意味着Vector拥有的属性和功能,Stack都拥有。
LinkedList:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, Serializable
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
LinkedList 实现 List 接口,能对它进行队列操作。
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
LinkedList 是非同步的。
Set:
public interface Set<E>
extends Collection<E>
Set像是一个罐子,所以元素无序,也不能重复。
Set判断两个对象是否相同不是用== ,而是用equals方法,也就是说,在加入一个新元素的时候,如果这个新元素和Set中已有对象用equals比较都返回false,那么这个元素就可以被加入到Set中,否则就不可以。由于Set有这个制约,所以在使用Set集合时,要注意两点:1, 为Set集合中的元素实现类提供一个有效的equals(Object o)方法;2, 传入Set构造函数中的Collection集合中不能含有重复元素。
AbstractSet
public abstract class AbstractSet<E>
extends AbstractCollection<E>
implements Set<E>
This class provides a skeletal implementation of the Set interface to minimize the effort required to implement this interface.
AbstractSet不像AbstractList那样把AbstractCollection中的大部分方法都复写了,AbstractSet只是多加了equals(Object o),hashCode() 和removeAll(Collection<?> c)。
HashSet
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, Serializable
HashSet是Set接口的典型实现,HashSet使用HASH算法来存储集合中的元素,因此具有良好的存取和查找性能。
当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据该HashCode值决定该对象在HashSet中的存储位置。
值得主要的是,HashSet集合判断两个元素相等的标准是两个对象通过equals()方法比较相等,并且两个对象的hashCode()方法的返回值相等。
HashSet 是一个没有重复元素的集合。
它是由HashMap实现的,不保证元素的顺序,而且HashSet允许使用 null 元素。
HashSet是非同步的。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。这通常是通过对自然封装该 set 的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装” set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问:
Set s = Collections.synchronizedSet(new HashSet(...));
HashSet通过iterator()返回的迭代器是fail-fast的。
HashSet的本质是一个"没有重复元素"的集合,它是通过HashMap实现的。HashSet中含有一个"HashMap类型的成员变量"map,HashSet的操作函数,实际上都是通过map实现的。
TreeSet:
public class TreeSet<E>
extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, Serializable
TreeSet 是一个有序的集合,它的作用是提供有序的Set集合。它继承于AbstractSet抽象类,实现了NavigableSet<E>, Cloneable, java.io.Serializable接口。
TreeSet 继承于AbstractSet,所以它是一个Set集合,具有Set的属性和方法。
TreeSet 实现了NavigableSet接口,意味着它支持一系列的导航方法。比如查找与指定目标最匹配项。
TreeSet 实现了Cloneable接口,意味着它能被克隆。
TreeSet 实现了java.io.Serializable接口,意味着它支持序列化。
TreeSet是基于TreeMap实现的。TreeSet中的元素支持2种排序方式:自然排序 或者 根据创建TreeSet 时提供的 Comparator 进行排序。这取决于使用的构造方法。
TreeSet为基本操作(add、remove 和 contains)提供受保证的 log(n) 时间开销。
另外,TreeSet是非同步的。 它的iterator 方法返回的迭代器是fail-fast的。
和NavigableSet一样,TreeSet的导航方法大致可以区分为两类,一类时提供元素项的导航方法,返回某个元素;另一类时提供集合的导航方法,返回某个集合。
lower、floor、ceiling 和 higher 分别返回小于、小于等于、大于等于、大于给定元素的元素,如果不存在这样的元素,则返回 null。
总结:
(01) TreeSet实际上是TreeMap实现的。当我们构造TreeSet时;若使用不带参数的构造函数,则TreeSet的使用自然比较器;若用户需要使用自定义的比较器,则需要使用带比较器的参数。
(02) TreeSet是非线程安全的。
(03) TreeSet实现java.io.Serializable的方式。当写入到输出流时,依次写入“比较器、容量、全部元素”;当读出输入流时,再依次读取。
TreeSet不支持快速随机遍历,只能通过迭代器进行遍历!
Map:
Map用于保存键值对,key和value都可以使任何饮用类型的数据。Map的key不允许重复,一个key映射至少一个value。
Map接口提供了三个collections,分别是key set,value collections还有key-value mapping set. Map的顺序就是迭代器迭代出来的顺序。
AbstractMap:
public abstract class AbstractMap<K,V>
extends Object
implements Map<K,V>
This class provides a skeletal implementation of the Map interface, to minimize the effort required to implement this interface.
HashMap:
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
HashMap是一个散列表,存储的内容是键值对。
HashMap的实现不是同步的,所以它不是线程安全的。它的key/value都可以是null。此外,HashMap中的映射不是有序的。
HashMap的实例有两个参数影响其性能:初始容量和加载因子。容量是哈希表中桶的数量,初始容量是哈希表在创建时的容量。加载引资时哈希表在其容量自动增加之前可以达到多满的百分比。当哈希表中的数目超过加载因子与当前容量的乘积时,就要对该哈希表进行rehash操作,只有就会重建内部数据结构,重建之后哈希表就会有大约两倍的桶数。
通常,默认加载因子是0.75.加载因子如果过高,空间开销会减少,但是增加了查询成本(因为虽然key不同,但是计算出的Hash值相同,为了高加载,就会放在其他位置,这样找起来就不方便了)。在设置初始容量时应该考虑到映射中所需条目数量以及加载因子,以便最大限度减少rehash操作。如果初始容量大于最大数目除以加载因子,就不会发生rehash的情况。
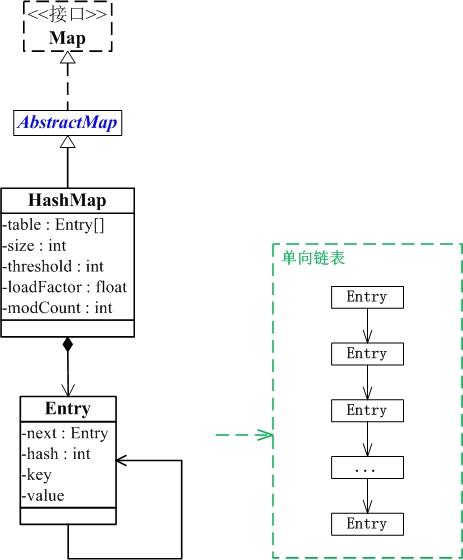
在Java8 中Entry 变为了Node<K, V> 类型。
HashMap是通过拉链法实现的哈希表。HashMap数据存储实际上是一个Node<K,V>[] table。而Node本身就是一个单向链表。拉链法参考:http://www.cnblogs.com/IvySue/p/7463932.html。
若要添加到HashMap中的键值对对应的key已经存在HashMap中,则找到该键值对;然后新的value取代旧的value,并退出!
若要添加到HashMap中的键值对对应的key不在HashMap中,则将其添加到该哈希值对应的链表中,并调用addEntry()。
Hashtable:
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, Serializable
和HashMap一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射。
也是通过拉链法实现的哈希表来存储数据。
Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。
Hashtable的api描述是:从jdk 1.2版本开始,该类被修正为实现List接口,并成为Java Collection集合框架的一员,区别于其他一些新的集合实现类,Hashtable是线程安全的。如果是一个线程安全的实现,推荐使用HashMap代替Hashtable。如果是高并发的线程安全的实现,推荐使用ConcurrentHashMap代替Hashtable。
被淘汰原因与Vector类似,效率低且并不安全。
Difference between HashMap and HashTable / HashMap vs HashTable
1. Synchronization or Thread Safe : This is the most important difference between two . HashMap is non synchronized and not thread safe.On the other hand, HashTable is thread safe and synchronized.
When to use HashMap ? answer is if your application do not require any multi-threading task, in other words hashmap is better for non-threading applications. HashTable should be used in multithreading applications.
2. Null keys and null values : Hashmap allows one null key and any number of null values, while Hashtable do not allow null keys and null values in the HashTable object.
3. Iterating the values: Hashmap object values are iterated by using iterator .HashTable is the only class other than vector which uses enumerator to iterate the values of HashTable objecte.
4. Fail-fast iterator : The iterator in Hashmap is fail-fast iterator while the enumerator for Hashtable is not.
According to Oracle Docs, if the Hashtable is structurally modified at any time after the iterator is created in any way except the iterator\'s own remove method , then the iterator will throw ConcurrentModification Exception.
Structural modification means adding or removing elements from the Collection object (here hashmap or hashtable) . Thus the enumerations returned by the Hashtable keys and elements methods are not fail fast.We have already explained the difference between iterator and enumeration.
5. Performance : Hashmap is much faster and uses less memory than Hashtable as former is unsynchronized . Unsynchronized objects are often much better in performance in compare to synchronized object like Hashtable in single threaded environment.
6. Superclass and Legacy : Hashtable is a subclass of Dictionary class which is now obsolete in Jdk 1.7 ,so ,it is not used anymore. It is better off externally synchronizing a HashMap or using a ConcurrentMap implementation (e.g ConcurrentHashMap).HashMap is the subclass of the AbstractMap class. Although Hashtable and HashMap has different superclasses but they both are implementations of the "Map" abstract data type.
Similarities Between HashMap and Hashtable
1. Insertion Order : Both HashMap and Hashtable does not guarantee that the order of the map will remain constant over time. Instead use LinkedHashMap, as the order remains constant over time.
2. Map interface : Both HashMap and Hashtable implements Map interface .
3. Put and get method : Both HashMap and Hashtable provides constant time performance for put and get methods assuming that the objects are distributed uniformly across the bucket.
4. Internal working : Both HashMap and Hashtable works on the Principle of Hashing . We have already discussed how hashmap works in java .
| HashMap | Hashtable | |
|---|---|---|
| Synchronized | No | Yes |
| Thread-Safe | No | Yes |
| Null Keys and Null values | One null key ,Any null values | Not permit null keys and values |
| Iterator type | Fail fast iterator | Fail safe iterator |
| Performance | Fast | Slow in comparison |
| Superclass and Legacy | AbstractMap , No | Dictionary , Yes |
SortedMap
public interface SortedMap<K,V>
extends Map<K,V>
根据key的自然顺序或者在创建sortedMap时指定的comparator来排序。当遍历Map的entrySet, keySet和values的时候顺序就体现出来了。
SortedMap是一个继承于Map接口的接口。它是一个有序的SortedMap键值映射。
SortedMap的排序方式有两种:自然排序 或者 用户指定比较器。 插入有序 SortedMap 的所有元素都必须实现 Comparable 接口(或者被指定的比较器所接受)。
另外,所有SortedMap 实现类都应该提供 4 个“标准”构造方法:
(01) void(无参数)构造方法,它创建一个空的有序映射,按照键的自然顺序进行排序。
(02) 带有一个 Comparator 类型参数的构造方法,它创建一个空的有序映射,根据指定的比较器进行排序。
(03) 带有一个 Map 类型参数的构造方法,它创建一个新的有序映射,其键-值映射关系与参数相同,按照键的自然顺序进行排序。
(04) 带有一个 SortedMap 类型参数的构造方法,它创建一个新的有序映射,其键-值映射关系和排序方法与输入的有序映射相同。无法保证强制实施此建议,因为接口不能包含构造方法。
NavigableMap:
public interface NavigableMap<K,V>
extends SortedMap<K,V>
NavigableMap除了继承SortedMap的特性外,它的提供的功能可以分为4类:
第1类,提供操作键-值对的方法。
lowerEntry、floorEntry、ceilingEntry 和 higherEntry 方法,它们分别返回与小于、小于等于、大于等于、大于给定键的键关联的 Map.Entry 对象。
firstEntry、pollFirstEntry、lastEntry 和 pollLastEntry 方法,它们返回和/或移除最小和最大的映射关系(如果存在),否则返回 null。
第2类,提供操作键的方法。这个和第1类比较类似
lowerKey、floorKey、ceilingKey 和 higherKey 方法,它们分别返回与小于、小于等于、大于等于、大于给定键的键。
第3类,获取键集。
navigableKeySet、descendingKeySet分别获取正序/反序的键集。
第4类,获取键-值对的子集。
TreeMap:
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, Serializable
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
TreeMap的本质是R-B Tree(红黑树),它包含几个重要的成员变量: root, size, comparator。
root 是红黑数的根节点。它是Entry类型,Entry是红黑数的节点,它包含了红黑数的6个基本组成成分:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)。Entry节点根据key进行排序,Entry节点包含的内容为value。
红黑数排序时,根据Entry中的key进行排序;Entry中的key比较大小是根据比较器comparator来进行判断的。
size是红黑数中节点的个数。
WeakHashMap:
public class WeakHashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>
WeakHashMap 继承于AbstractMap,实现了Map接口。
和HashMap一样,WeakHashMap 也是一个散列表,它存储的内容也是键值对(key-value)映射,而且键和值都可以是null。
不过WeakHashMap的键是“弱键”。在 WeakHashMap 中,当某个键不再正常使用时,会被从WeakHashMap中被自动移除。更精确地说,对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。某个键被终止时,它对应的键值对也就从映射中有效地移除了。
这个“弱键”的原理呢?大致上就是,通过WeakReference和ReferenceQueue实现的。 WeakHashMap的key是“弱键”,即是WeakReference类型的;ReferenceQueue是一个队列,它会保存被GC回收的“弱键”。实现步骤是:
(01) 新建WeakHashMap,将“键值对”添加到WeakHashMap中。
实际上,WeakHashMap是通过数组table保存Entry(键值对);每一个Entry实际上是一个单向链表,即Entry是键值对链表。
(02) 当某“弱键”不再被其它对象引用,并被GC回收时。在GC回收该“弱键”时,这个“弱键”也同时会被添加到ReferenceQueue(queue)队列中。
(03) 当下一次我们需要操作WeakHashMap时,会先同步table和queue。table中保存了全部的键值对,而queue中保存被GC回收的键值对;同步它们,就是删除table中被GC回收的键值对。
这就是“弱键”如何被自动从WeakHashMap中删除的步骤了。
和HashMap一样,WeakHashMap是不同步的。可以使用 Collections.synchronizedMap 方法来构造同步的 WeakHashMap。
以上是关于Java的数据结构相关的类实现的主要内容,如果未能解决你的问题,请参考以下文章