java 集合类
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java 集合类相关的知识,希望对你有一定的参考价值。
1. Java集合架构图
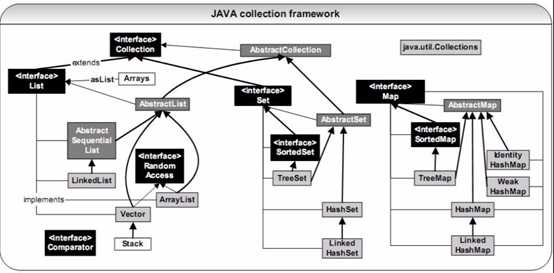
上图所示:Java有两类集合,线性表(Collection子类)和键值对(Map子类)
2. Java集合架构图-2
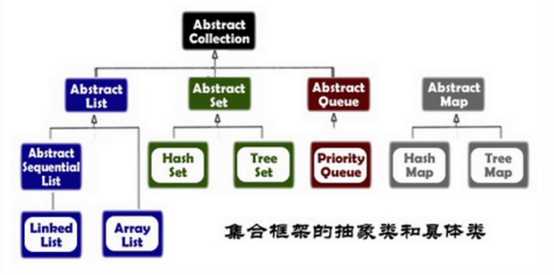
3. 线性表
ArrayList、Vector的引入
l 数组在使用上有局限性:创建后无法改变存储大小。
代码示意:int[] iAry=new int[3]; iAry[0]=0;iAry[3];//err
l 此时可用动态数组类ArrayList或Vector:
ArrayList<Integer> ary=new ArrayList<Integer> ();
ary.add(0);…ary.add(3);
ary空间无限制,当空间无法容纳时会重新开辟更大空间。
l ArrayList和Vector的异同:
相同点:
都是基于数组来实现的;都可从指定位置取得元素,从容器的末尾
增加和删除元素都非常的有效,能在一个常数级的时间(O(1))内完成。但是
从一个其他的位置增加和删除一个元素颇费时,需要的时间为O(n-i),这里
的n代表元素个数,i代表要增加和删除的元素所在的位置。
差别:
1、Vector法都是同步的,即线程安全,而ArrayList不考虑线程安全,ArrayList的性能比Vector好;
2、 当添加元素超容量时,Vector容量翻倍,而ArrayList增加50%(更节约内存空间)。 所以,在单线程里,尽量用ArrayList。
l ArrayList的优缺点
以数组实现。节约空间,但数组有容量限制。超出限制时会增加50%容量,用System.arraycopy()复制到新的数组,因此最好能给出数组大小的预估值。默认第一次插入元素时创建大小为10的数组。
按数组下标访问元素--get(i)/set(i,e) 的性能很高,这是数组的基本优势。
直接在数组末尾加入元素--add(e)的性能也高,但如果按下标插入、删除元素--add(i,e), remove(i), remove(e),则要用System.arraycopy()来移动部分受影响的元素,性能就变差了,这是基本劣势。
l LinkedList的结构
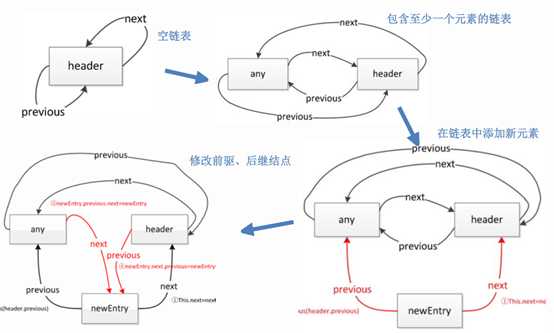
l LinkedList的优缺点
以双向链表实现。链表无容量限制,但双向链表本身使用了更多空间,也需要额外的链表指针操作。
按下标访问元素--get(i)/set(i,e) 要悲剧的遍历链表将指针移动到位(如果i>数组大小的一半,会从末尾移起)。
插入、删除元素时修改前后节点的指针即可,但还是要遍历部分链表的指针才能移动到下标所指的位置,只有在链表两头的操作--add(), addFirst(),removeLast()或用iterator()上的remove()能省掉指针的移动。
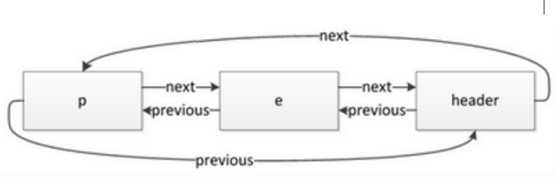
l ArrayList与LinkedList的比较
ArrayList基于数组:便于索引,但不便于插入删除(需要移动元素);
LinkedList基于链表:插入和删除只需修改指针,但不能随机存取(需从head找起)
代码理解:
List<String> shenXiao = new LinkedList<String>(); shenXiao.add("子(zǐ)");
shenXiao.add("丑(chǒu)");
shenXiao.add("卯(mǎo)"); shenXiao.add("辰(chén)");
shenXiao.add("巳(sì)"); shenXiao.add("午(wǔ)");
shenXiao.add("未(wèi)"); shenXiao.add("申(shēn)");
shenXiao.add("酉(yǒu)"); shenXiao.add("戌(xū)");
shenXiao.add("亥(hài)"); shenXiao.add(2, "寅(yín)");
System.out.println(shenXiao);//自动遍历[..寅(yín)..亥(hài)]
l Set
作为Collection接口的重要子接口,Set接口是一个不包含重复元素,且元素排列无序的集合,并且最多包含一个 null 元素,也被称为集。
Set接口的方法和Collection接口的方法大体相同,但在遍历时只能通过Iterator()方法获取迭代器进行迭代。
Set中的add方法不同于Collection接口,有一个boolean类型的返回值,当集合中含有与某个元素equals相等的元素时返回false,无法添加,否
则返回true。
Set中的Iterator方法返回的返回的元素没有特定的顺序(除非此 set 是某个提供顺序保证的类的实例)。
l HashSet
HashSet类是Set接口的重要实现类,由哈希表(实际上是一个 HashMap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。
Set接口是通过equals方法来比较两元素是否相同的,但是如果有1000个元素,那么再添加一个元素,就要比较1000次,效率严重降低。所以HashSet类底层采用了HashMap来存储元素,而HashMap采用了哈希表的原理。
因此HashSet类按照哈希算法来存取对象,当向集合中加入一个新对象时,会调用对象的HashCode()方法得到对象的哈希码,然后根据这个码计算出对象在集合中存储的位置。 HashCode()方法实际上是返回的对象存储的物理地址。
所以总的来说,HashSet是通过两元素的HashCode()方法和equals()方法来判断两元素是否相等的。
所以当我们使用HashSet添加元素时一定要重写该元素的HashCode方法和equals方法。并且,参与计算两个方法返回值的关键属性应该相同。 代码示例:HashSetDemo.java
l TreeSet
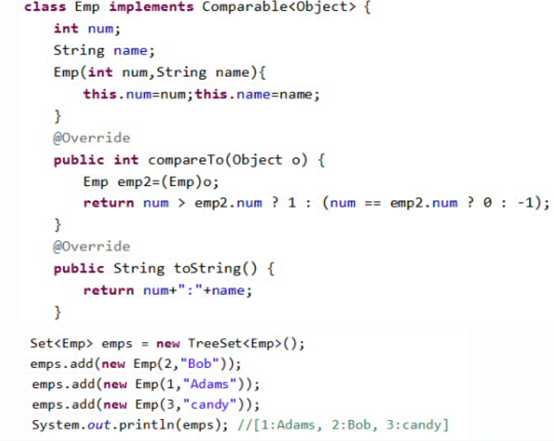
TreeSet是一个有序集合,TreeSet中的元素将按照升序排列,缺省是按照自然排序进行排列,意味着TreeSet中的元素要实现Comparable接口。
在类上implement Comparable重写compareTo()方法,在方法内定义比较算法, 根据大小关系, 返回正数负数或零,在使用TreeSet存储对象的时候, add()方法内部就会自动调用compareTo()方法进行比较。
代码:自定义类做元素
必须实现Comparable,否则TreeSet无法add()
l HashMap
对于 HashMap 及其子类而言,它们采用 Hash 算法来决定集合中元素的存储位置。
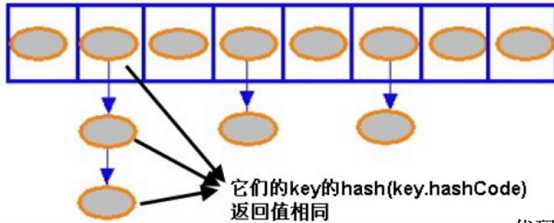
当系统开始初始化 HashMap 时,系统会创建一个Entry 数组,这个数组里可以存储元素的位置被称为“桶(bucket)”,每个 bucket 都有其指定索引,系统可以根据其索引快速访问该 bucket 里存储的元素。
无论何时,HashMap 的每个“桶”只存储一个元素(也就是一个 Entry),由于Entry 对象可以包含一个引用变量(就是 Entry 构造器的的最后一个参数)用于指向下一个 Entry,因此可能出现的情况是:HashMap 的 bucket 中只有一个Entry,但这个 Entry 指向另一个 Entry ——这就形成了一个 Entry 链。如图所示:
l TreeMap和HashMap的差别
HashMap通过hashcode对其内容进行快速查找;而TreeMap基于红黑树实现的,其所有的元素都保持着某种固定的顺序,如自然顺序或自定义顺序。
在Map中插入、删除和定位元素,HashMap是最好的选择。但如果要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
注:
1.同样的对比有TreeSet和HashSet,因为TreeSet基于TreeMap, HashSet基于HashMap
2.使用HashMap要求添加的键类需明确实现hashCode()、 equals()。

l 键值对-Hash算法
Hash表引入原因:数组寻址容易,插入和删除困难; 而链表寻址困难,插入和删除容易。哈希表可综合两者的优点,即,寻址容易,插入删除也容易的数据结构。
Hash(散列)算法,把任意长度的输入,用算法函数变换成固定长度的输出 (散列值)。不同的输入可能会散列成相同散列值。
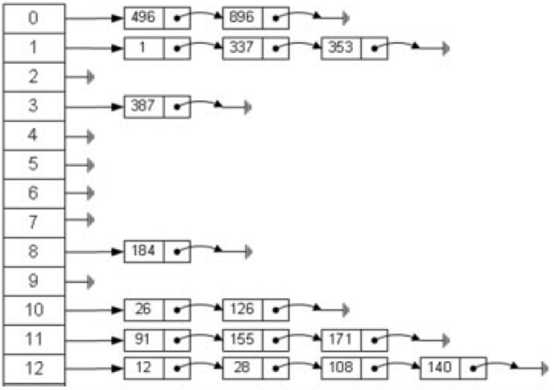
Hash表有多种实现,以拉链法(链表的数组)解释: ? 左边数组,数组每个元素中 包括一个指针,指向一个链表的头。根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
散列法:元素特征转变为数组下标的方法就是散列法,上图使用除法散列法:index = value % 13
键值对-Hash算法 HashCode的理解
Hashcode(散列码):每个对象都会有一个int型的hashcode,代表它在内存中的位置。
Object中的equals方法是指比较两个对象是不是指向同一个引用。hashcode方法返回hashCode的值;Object规范里规定:如果两个对象根据equals(Object)方式是相等的,那么这两个对象的hashCode一定要相等,所以记住:重写equals方法后,请重写hashCode方法。
l 键值对
HashMap和Hashtable
Hashtable继承自Dictionary类,而HashMap是Map接口的一个实现。
代码:(HashMap改为Hashtable,练习)

主要差别:
1 HashMap允许null key和null value,而hashtable不允许;
2 HashMap是Hashtable的轻量级实现(非线程安全的实现),效率高;
3 空间:加载因子默认都为0.75;初始容量Hashtable为11,而HashMap为16。 增加方式Hashtable为 oldSize*2+1,HashMap为oldSize *2。
l 枚举器访问集合对象
Iterator模式是用于遍历集合类的标准访问方法。它可以把访问逻辑从不同类型的集合类中抽象出来,从而避免向客户端暴露集合的内部结构。
例如,如果没有使用Iterator,遍历一个数组的方法是使用索引:
for(int i=0; i<array.size(); i++) { ... get(i) ... } 而访问一个链表(LinkedList)又必须使用while循环:while((e=e.next())!=null) { ... e.data() ... } 以上两种方法客户端都必须事先知道集合的内部结构,访问代码和集合本身是紧耦合。无法将访问逻辑从集合类和客户端代码中分离出来,每一种集合对应一种遍历方法,客户端代码无法复用。更恐怖的是,如果以后需要把ArrayList更换为LinkedList,则原来的客户端代码必须全部重写。
为解决以上问题,Iterator模式总是用同一种逻辑来遍历集合:
for(Iterator it = c.iterater(); it.hasNext(); ) { ... } 这样一来客户端自身不维护遍历集合的"指针",所有的内部状态(如当前元素位置,是否有下一个元素)都由Iterator来维护,而这个Iterator由集合类通过工厂方法生成,因此,它知道如何遍历整个集合。
客户端从不直接和集合类打交道,它总是控制Iterator,向它发送"向前","向后","取
通过枚举器访问线性集合
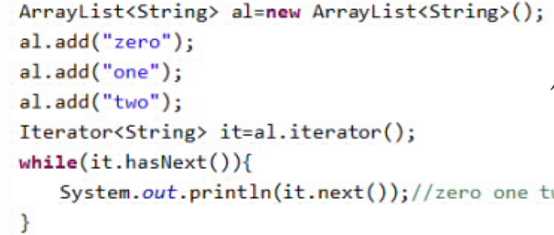
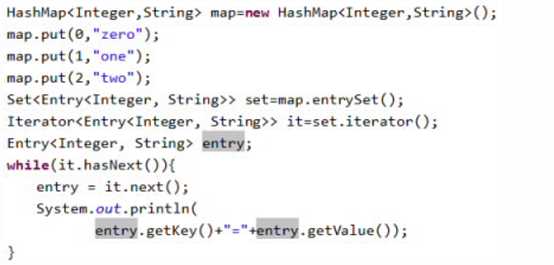
通过枚举器访问HashMap
泛型
泛型:即参数化类型,所操作的数据类型被指定为一个参数。 ?
这种参数类型可以用在类、接口和方法的创建中(即,泛型类、泛型接口、
泛型方法)。
泛型好处:编译时可检测类型错误;避免了强制类型转换(自动和隐式 ?
的),提高代码的重用性。
例:

以上的List就是泛型接口、ArrayList就是泛型类、 add()和get()是泛型方法
注:集合框架,都已经成为泛型化了。
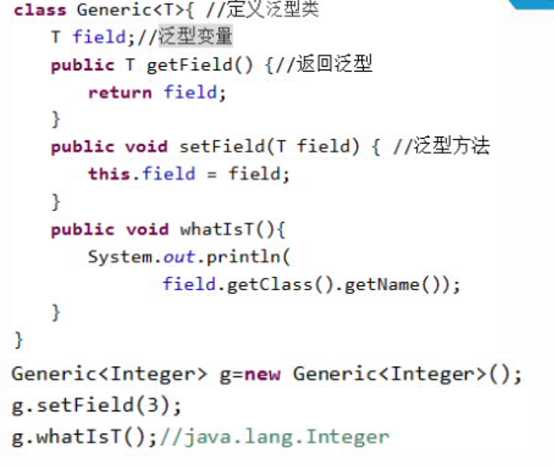
泛型的规则

泛型定义代码举例
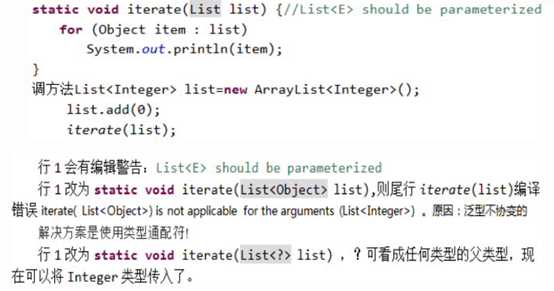
类型通配符?引入原因:
泛型的继承,代码说明:

l 浅拷贝与Clone
有时我们需要复制对象:
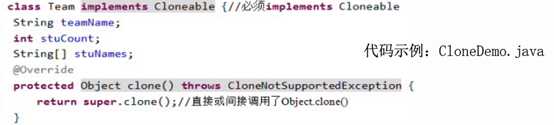
测试:

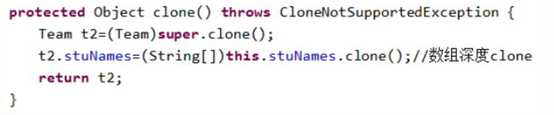
l 浅拷贝与Clone(续)
分析,从上面代码运行结果看:
成员变量为基本类型(外加String类型—内容不变性),只要super.clone()就可
拷贝。但数组或复杂类型(引用类型)时,就必须实现深度clone。
l 深度clone(本例):
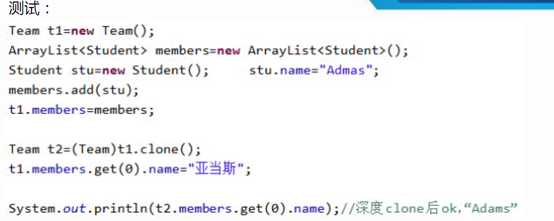
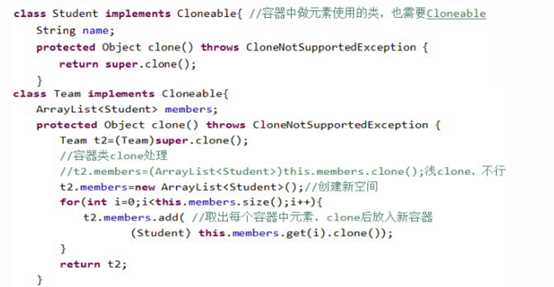
l 深度clone()
容器类成员,需逐个元素复制,以ArrayList为例
以上是关于java 集合类的主要内容,如果未能解决你的问题,请参考以下文章