python2 能使用requests吗
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python2 能使用requests吗相关的知识,希望对你有一定的参考价值。
参考技术A由于公司要用到模拟用户登录,于是用学校图书馆读者登录来进行练习。
工具是python2 + requests第三方库+火狐浏览器的firebug进行http抓包
目标 用python成功登录学校图书馆
接下来几篇会利用urllib和urllib2标准库进行登录
以下为具体步骤:
1 打开学校图书馆网址,以下为登录界面

2 在firebug上可以看到登录的http请求,发现有302和200两个状态码,一个是登录post,返回302,说明有重定向;之后请求重定向url,得到正确的登录。而requests库对重定向可以正确解决。

3 看一下post请求和响应的头部信息,使得python代码模拟浏览器,可以在响应头部看到服务器发了cookie。在post参数中textBox1、2对应着读者号和密码。有了这两个信息,我们就可以写python代码了
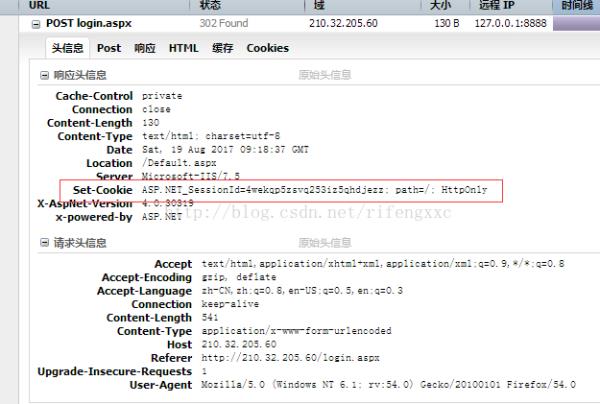
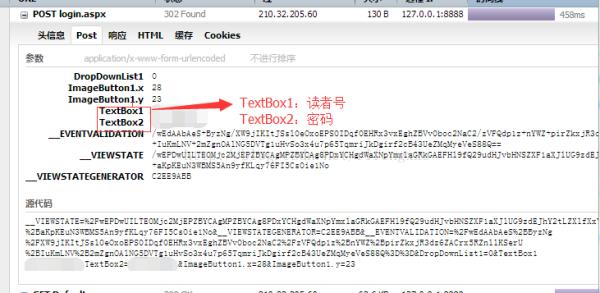
4 在GET请求中,浏览器会发送302响应的cookie
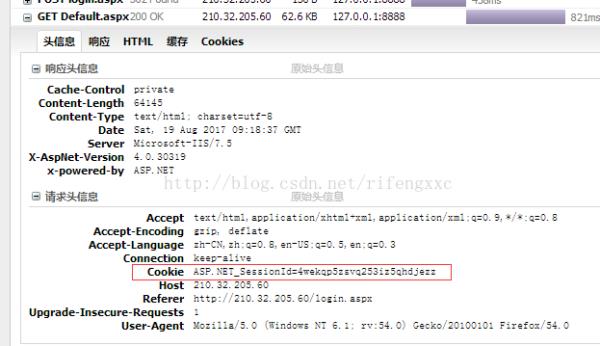
综合以上分析,利用requests库进行模拟用户登录。这里的post参数采用了之前图片的源码形式,使得参数顺序匹配
import requests
url = "http://210.32.205.60/login.aspx"
# 学校图书馆登录url
header = "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Connection":"keep-alive",
"Content-Type":"application/x-www-form-urlencoded",
"Host":"210.32.205.60",
"Referer": "http://210.32.205.60/login.aspx",
"Upgrade-Insecure-Requests":"1",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; rv:54.0) Gecko/20100101 Firefox/54.0"
body = b'__VIEWSTATE=%2FwEPDwUILTE0Mjc2MjEPZBYCAgMPZBYCAg8PDxYCHgdWaXNpYmxlaGRkGAEFHl9fQ29udHJvbHNSZXF1aXJlUG9zdEJhY2tLZXlfXxYCBQxJbWFnZUJ1dHRvbjEFDEltYWdlQnV0dG9uMtIIHXEj%2BaKpKEuN3WBMS5An9yfKLqy76FI5Cs0ie1No&__VIEWSTATEGENERATOR=C2EE9ABB&__EVENTVALIDATION=%2FwEdAAbAeS%2BByzNg%2FXW9jIKItJSsl0eOxoEPS0IDqf0EHRx3vxEghZBVv0boc2NaC2%2FzVFQdp1z%2BnYWZ%2BpirZkxjR3dz6ZACrx5RZnllKSerU%2BIuKmLNV%2B2mZgnOAlNG5DVTg1uHvSo3x4u7p65TqmriJkDgirf2cB43UeZMqMyeVeS88Q%3D%3D&DropDownList1=0&TextBox1=读者号&TextBox2=密码&ImageButton1.x=44&ImageButton1.y=12'
r = requests.post(url, data=body, headers=header)
print r.text
以上为一次提交,没有进行重定向截取。
如果想用reque库截取重定向,在这个图书馆登录中则需要进行两次操作,这里相当于只做了post请求,头部,post参数都不变,只不过在requests.post()内设置了参数
r = requests.post(url, data=body, headers=header, allow_redirects=False)
# 设置 allow_redirects=False 使得禁止重定向
aspid = r.headers["Set-Cookie"] # 返回页面的头部的cookie
print r.status_code # 输出302
如果再想登陆图书馆页面,那么需要将cookie重新加入新的url上,进行get请求的提交,此时url为/Default.aspx.
url ="http://210.32.205.60/Default.aspx"
header =
"Accept": "image/jpeg, application/x-ms-application, image/gif, application/xaml+xml, image/pjpeg, application/x-ms-xbap, */*",
"Referer": "http://210.32.205.60/login.aspx",
"Accept-Language": "zh-CN",
"User-Agent": "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0)",
"Accept-Encoding": "gzip, deflate",
"Host": "210.32.205.60",
"Connection": "Keep-Alive",
"Pragma": "no-cache",
"Cookie": aspid
r = requests.get(url=url,headers=header)
print r.status_code
print r.text
接下来的几篇是利用python2的urllib2和urllib进行相同的模拟用户登录。
ps 由于urllib2处理重定向的时候不会将cookie带上,会导致页面不能正确爬取,所以要处理重定向。解决urllib重定向文章在此,分别介绍了urllib2自动处理重定向(带上cookie),和urllib2阻止重定向,返回cookie。
利用urllib2进行自动处理重定向,模拟浏览器提交post一次,就可以登录图书馆的文章在这。
利用urllib2处理重定向,使得重定向截断,获取cookie,根据cookie用代码实现重定向,登录图书馆的文章在此。
本回答被提问者采纳以上是关于python2 能使用requests吗的主要内容,如果未能解决你的问题,请参考以下文章