JavaWeb学习笔记四 request&response
Posted 冰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaWeb学习笔记四 request&response相关的知识,希望对你有一定的参考价值。
HttpServletResponse
我们在创建Servlet时会覆盖service()方法,或doGet()/doPost(),这些方法都有两个参数,一个为代表请求的request和代表响应response。service方法中的response的类型是ServletResponse,而doGet/doPost方法的response的类型是HttpServletResponse,HttpServletResponse是ServletResponse的子接口,功能和方法更加强大。
response的运行流程
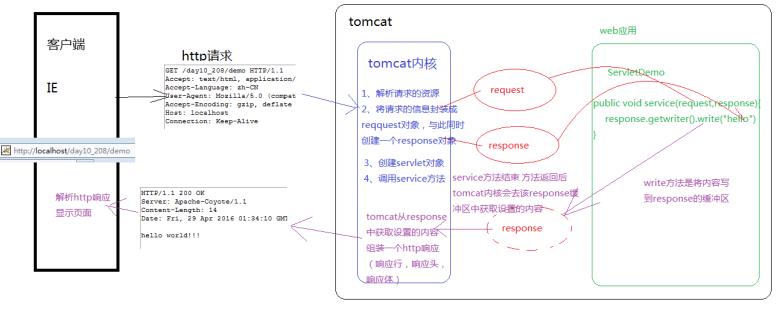
通过抓包工具抓取Http响应
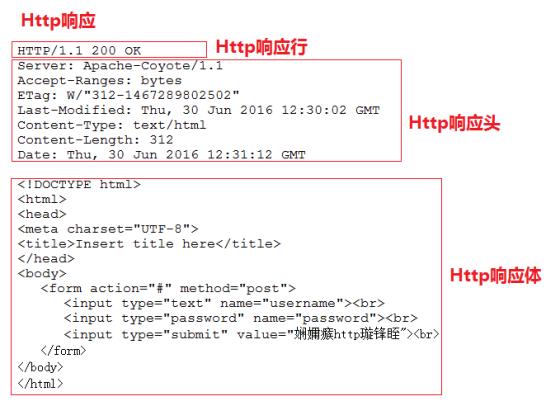
因为response代表响应,所以我们可以通过该对象分别设置Http响应的响应行,响应头和响应体
通过response设置响应行
设置响应行的状态码 setStatus(int sc)
//手动设置http响应行中的状态码 response.setStatus(404);
通过response设置响应头,其中,add表示添加,而set表示设置
addHeader(String name, String value) addIntHeader(String name, int value) addDateHeader(String name, long date) setHeader(String name, String value) setDateHeader(String name, long date) setIntHeader(String name, int value)
比如:
Date date = new Date(); //设置响应头 response.addHeader("name", "zhangsan"); response.addIntHeader("age", 28); response.addDateHeader("birthday", date.getTime()); response.addHeader("name", "lisi"); response.setHeader("age", "28"); response.setHeader("age", "50");
//设置定时刷新的头 response.setHeader("refresh", "5;url=http://www.baidu.com"); //----------重定向-------------------------- //没有响应 告知客户端去重定向到servlet2 //1、设置状态码302 //response.setStatus(302); //2、设置响应头Location //response.setHeader("Location", "/WEB14/servlet2"); //封装成一个重定向的方法sendRedirect(url) response.sendRedirect("/WEB14/servlet2");
通过response设置响应体
响应体设置文本 PrintWriter getWriter()
response.getWriter().write("hello");
获得字符流,通过字符流的write(String s)方法可以将字符串设置到response 缓冲区中,随后Tomcat会将response缓冲区中的内容组装成Http响应返回给浏览器端。
关于设置中文的乱码问题
原因:response缓冲区的默认编码是iso8859-1,此码表中没有中文,可以通过 response的setCharacterEncoding(String charset) 设置response的编码。
但发现客户端还是不能正常显示文字,原因是我们将response缓冲区的编码设置成UTF-8,但浏览器的默认编码是本地系统的编码,因为我们都是中文系统,所以客户端浏览器的默认编码是GBK,我们可以手动修改浏览器的编码是UTF-8。
还可以在代码中指定浏览器解析页面的编码方式,通过response的setContentType(String type)方法指定页面解析时的编码是UTF-8, response.setContentType("text/html;charset=UTF-8");
上面的代码不仅可以指定浏览器解析页面时的编码,同时也内含 setCharacterEncoding的功能,所以在实际开发中只要编写 response.setContentType("text/html;charset=UTF-8");就可以解决页面输出中文乱码问题。
//设置response查询的码表 //resp.setCharacterEncoding("UTF-8"); //通过一个头 Content-Type 告知客户端使用何种码表 //resp.setHeader("Content-Type", "text/html;charset=UTF-8");
resp.setContentType("text/html;charset=UTF-8"); PrintWriter writer = resp.getWriter(); writer.write("你好");
响应头设置字节
ServletOutputStream getOutputStream():获得字节流,通过该字节流的write(byte[] bytes)可以向response缓冲区中写入字节,在由Tomcat服务器将字节内容组成Http响应返回给浏览器。
案例1:下载服务器上的图片
//使用response获得字节输出流 ServletOutputStream out = resp.getOutputStream(); //获得服务器上的图片 String realPath = this.getServletContext().getRealPath("a.jpg"); InputStream in = new FileInputStream(realPath); int len = 0; byte[] buffer = new byte[1024]; while((len=in.read(buffer))>0){ out.write(buffer, 0, len); } in.close(); out.close();
案例2:使用字节流输出中文
//1 获得输出字节流 OutputStream os = resp.getOutputStream(); //2 输出中文 os.write("你好 世界!".getBytes("UTF-8")); //3告诉浏览器使用GBK解码 ==> 乱码 resp.setHeader("Content-Type", "text/html;charset=utf-8");
案例3:完成文件下载
文件下载的实质就是文件拷贝,将文件从服务器端拷贝到浏览器端。所以文件下载需 要IO技术将服务器端的文件使用InputStream读取到,在使用 ServletOutputStream写到response缓冲区中
代码如下:
package response; import javax.servlet.ServletException; import javax.servlet.ServletOutputStream; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import java.io.*; /** * Created by yang on 2017/7/23. */ public class Demo01 extends HttpServlet { @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { doPost(req, resp); } @Override protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { //要下载的文件的名称 String filename = "a.flv"; //要下载的这个文件的类型-----客户端通过文件的MIME类型去区分类型 resp.setContentType(this.getServletContext().getMimeType(filename)); //告诉客户端该文件不是直接解析 而是以附件形式打开(下载) resp.setHeader("Content-Disposition", "attachment;filename="+filename); //获取文件的绝对路径 String path = this.getServletContext().getRealPath("download/"+filename); //获得该文件的输入流 InputStream in = new FileInputStream(path); //获得输出流---通过response获得的输出流 用于向客户端写内容 ServletOutputStream out = resp.getOutputStream(); //文件拷贝的模板代码 int len = 0; byte[] buffer = new byte[1024]; while((len=in.read(buffer))>0){ out.write(buffer, 0, len); } } }
如果下载中文文件,页面在下载时会出现中文乱码或不能显示文件名的情况, 原因是不同的浏览器默认对下载文件的编码方式不同,ie是UTF-8编码方式,而火狐 浏览器是Base64编码方式。所里这里需要解决浏览器兼容性问题,解决浏览器兼容性问题的首要任务是要辨别访问者是ie还是火狐(其他),通过Http请求体中的一个属性可以辨别。
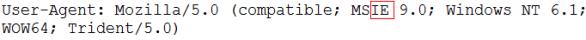

//解决乱码方法如下(了解): if (agent.contains("MSIE")) { // IE浏览器 filename = URLEncoder.encode(filename, "utf-8"); filename = filename.replace("+", " "); } else if (agent.contains("Firefox")) { // 火狐浏览器 BASE64Encoder base64Encoder = new BASE64Encoder(); filename = "=?utf-8?B?" + base64Encoder.encode(filename.getBytes("utf-8")) + "?="; } else { // 其它浏览器 filename = URLEncoder.encode(filename, "utf-8"); } //其中agent就是请求头User-Agent的值
完整代码如下:


package response; import sun.misc.BASE64Encoder; import javax.servlet.ServletException; import javax.servlet.ServletOutputStream; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import java.io.*; import java.net.URLEncoder; /** * Created by yang on 2017/7/23. */ public class Demo01 extends HttpServlet { @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { doPost(req, resp); } @Override protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { //要下载的文件的名称 String filename1 = "美女.jpg"; //获得要下载的文件的名称 //解决获得中文参数的乱码----下节课讲 String filename = new String(filename1.getBytes("ISO8859-1"),"UTF-8"); //获得请求头中的User-Agent String agent = req.getHeader("User-Agent"); //根据不同浏览器进行不同的编码 String filenameEncoder = ""; if (agent.contains("MSIE")) { // IE浏览器 filenameEncoder = URLEncoder.encode(filename, "utf-8"); filenameEncoder = filenameEncoder.replace("+", " "); } else if (agent.contains("Firefox")) { // 火狐浏览器 BASE64Encoder base64Encoder = new BASE64Encoder(); filenameEncoder = "=?utf-8?B?" + base64Encoder.encode(filename.getBytes("utf-8")) + "?="; } else { // 其它浏览器 filenameEncoder = URLEncoder.encode(filename, "utf-8"); } //要下载的这个文件的类型-----客户端通过文件的MIME类型去区分类型 resp.setContentType(this.getServletContext().getMimeType(filename)); //告诉客户端该文件不是直接解析 而是以附件形式打开(下载) resp.setHeader("Content-Disposition", "attachment;filename="+filename); //获取文件的绝对路径 String path = this.getServletContext().getRealPath("download/"+filename1); //获得该文件的输入流 InputStream in = new FileInputStream(path); //获得输出流---通过response获得的输出流 用于向客户端写内容 ServletOutputStream out = resp.getOutputStream(); //文件拷贝的模板代码 int len = 0; byte[] buffer = new byte[1024]; while((len=in.read(buffer))>0){ out.write(buffer, 0, len); } } }
HttpServletRequest
我们在创建Servlet时会覆盖service()方法,或doGet()/doPost(),这些方法都有两个参数,一个为代表请求的request和代表响应response。
service方法中的request的类型是ServletRequest,而doGet/doPost方法的request的类型是HttpServletRequest,HttpServletRequest是ServletRequest的子接口,功能和方法更加强大,今天我们学习HttpServletRequest。
request的运行流程
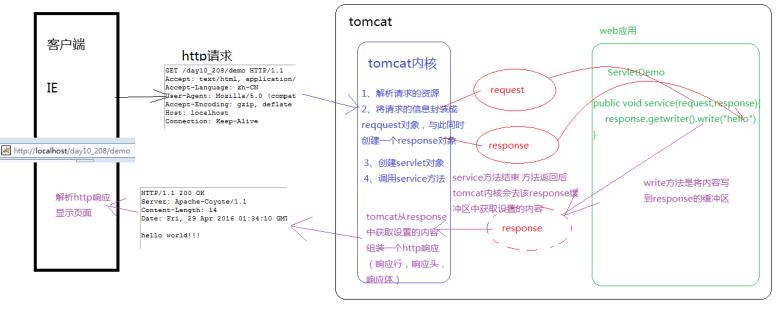
通过抓包工具抓取Http请求

因为request代表请求,所以我们可以通过该对象分别获得Http请求的请求行,请 求头和请求体
通过request获得请求行
1、获得客户端的请求方式: String getMethod()
//1、获得请求方式 String method = req.getMethod(); System.out.println("method:"+method);//method:GET
2、获得请求的资源:
String getRequestURI() StringBuffer getRequestURL() String getContextPath() ---web应用的名称 String getQueryString() ---- get提交url地址后的参数字符串username=zhangsan&password=123
比如:
//2、获得请求的资源相关的内容 String requestURI = req.getRequestURI(); StringBuffer requestURL = req.getRequestURL(); System.out.println("uri:"+requestURI);//uri:/Demo01 System.out.println("url:"+requestURL);//url:http://localhost:8080/Demo01 //获得web应用的名称 String contextPath = req.getContextPath(); System.out.println("web应用:"+contextPath);//web应用: //地址后的参数的字符串 String queryString = req.getQueryString(); System.out.println(queryString);//name=yyb&pwd=123 //3、获得客户机的信息---获得访问者IP地址 String remoteAddr = req.getRemoteAddr(); System.out.println("IP:"+remoteAddr);//IP:0:0:0:0:0:0:0:1
request.getContextPath()方法:
在开发Web项目时,经常用到的方法,其作用是获取当前的系统路径。当使用Tomcat作为Web服务器,项目一般部署在Tomcat下的webapps的目录下。
具体来说主要用两种部署的路径:
- 一是将web项目中的webRoot下的文件直接拷贝到webapps/ROOT下(删除ROOT下的原有文件);
- 另一中方法在Tomcat下的webapps中创建以项目名称命名(当然也可以用其他的名称)的文件夹,并将webRoot下的文件直接拷贝到该文件夹下。
对于第一部署方法,request.getContextPath()的返回值为空(即:"",中间无空格,注意区分null)。 对于第二部署方法,其返回值为:/创建的文件夹的名称。具体参考这里。
3、request获得客户机(客户端)的一些信息: request.getRemoteAddr() --- 获得访问的客户端IP地址
4、通过request获得请求头。
long getDateHeader(String name) String getHeader(String name) Enumeration getHeaderNames() Enumeration getHeaders(String name) int getIntHeader(String name)
比如:
//1、获得指定的头 String header = request.getHeader("User-Agent"); //Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240 System.out.println(header); //2、获得所有的头的名称 Enumeration<String> headerNames = request.getHeaderNames(); while (headerNames.hasMoreElements()) { String headerName = headerNames.nextElement(); String headerValue = request.getHeader(headerName); System.out.println(headerName + ":" + headerValue); } //accept:text/html, application/xhtml+xml, image/jxr, */* //accept-language:zh-CN //user-agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240 //accept-encoding:gzip, deflate //host:localhost:8080 //connection:Keep-Alive //cookie:JSESSIONID=ABC9B9C2FFC81561CA377311BD3BD409
5、referer头的作用:执行该此访问的的来源,可以做防盗链。
//对该新闻的来源的进行判断 String header = request.getHeader("referer"); if(header!=null&&header.startsWith("http://localhost")){ //是从我自己的网站跳转过来的 可以看新闻 response.setContentType("text/html;charset=UTF-8"); response.getWriter().write("中国确实已经拿到100块金牌...."); }else{ response.getWriter().write("你是盗链者,可耻!!"); }
6.通过request获得请求体。
请求体中的内容是通过post提交的请求参数,格式是:username=zhangsan&password=123&hobby=football&hobby=basketball
key --------value username [zhangsan] password [123] hobby [football,basketball]
以上面参数为例,通过以下方法获得请求参数:
String getParameter(String name)
String[] getParameterValues(String name)
Enumeration getParameterNames()
Map<String,String[]> getParameterMap()
注意:get请求方式的请求参数, 上述的方法一样可以获得。
//1、获得单个表单值 String username = request.getParameter("username"); System.out.println(username); String password = request.getParameter("password"); System.out.println(password);
//2、获得多个表单的值 String[] hobbys = request.getParameterValues("hobby"); for(String hobby:hobbys){ System.out.println(hobby); }
//3、获得所有的请求参数的名称 Enumeration<String> parameterNames = request.getParameterNames(); while(parameterNames.hasMoreElements()){ System.out.println(parameterNames.nextElement()); } System.out.println("------------------");
//4、获得所有的参数 参数封装到一个Map<String,String[]> Map<String, String[]> parameterMap = request.getParameterMap(); for(Map.Entry<String, String[]> entry:parameterMap.entrySet()){ System.out.println(entry.getKey()); for(String str:entry.getValue()){ System.out.println(str); } System.out.println("---------------------------"); }
参数乱码解决
解决post提交方式的乱码:request.setCharacterEncoding("UTF-8");
解决get提交的方式的乱码:parameter = new String(parameter.getbytes("iso8859-1"),"utf-8");
//设置request的编码---只适合post方式 request.setCharacterEncoding("UTF-8"); //get方式乱码解决 String username = request.getParameter("username");//乱码 //先用iso8859-1编码, 在使用utf-8解码 //username = new String(username.getBytes("iso8859-1"),"UTF-8");
request的其他功能
request是一个域对象,request对象也是一个存储数据的区域对象,在将来开发中。使用请求转发时,servlet处理完数据, 处理结果要交给jsp显示。 可以使用request域将处理结果由servlet带给jsp显示。所以也具有如下方法:
setAttribute(String name, Object o)
getAttribute(String name)
removeAttribute(String name)
注意:request域的作用范围为一次请求中。系统当前有多少个request就有多少request域。
request完成请求转发
一个Servlet处理完毕交给下面的servlet(JSP)继续处理,在现实开发中,没有servlet转发给servlet的情况。都是由servlet转发给JSP.这样可以达到分工的作用:
- servlet: 比较适合处理业务。
- JSP: 比较适合显示功能。
//获得请求转发器----path是转发的地址 RequestDispatcher getRequestDispatcher(String path) //通过转发器对象转发 requestDispathcer.forward(ServletRequest request, ServletResponse response)
比如:
//向request域中存储数据 request.setAttribute("name", "tom"); //servlet1 将请求转发给servlet2 RequestDispatcher dispatcher = request.getRequestDispatcher("/servlet2"); //执行转发的方法 dispatcher.forward(request, response);
包含
两个servlet(jsp)共同向浏览器输出内容。作用是在现实开发中,多个页面含有相同的内容,把相同的内容抽取到一个jsp中,在需要显示这个段内容的jsp中,包含抽取的jsp.可以达到统一管理相同的内容。
response.setContentType("text/html;charset=utf-8");
response.getWriter().print("这是正文部分<hr>");
request.getRequestDispatcher("/GServlet").include(request, response);
ServletContext域与Request域的生命周期比较
ServletContext:
- 创建:服务器启动
- 销毁:服务器关闭
- 域的作用范围:整个web应用
request:
- 创建:访问时创建request
- 销毁:响应结束request销毁
- 域的作用范围:一次请求中
转发与重定向的区别
1、重定向两次请求,转发一次请求
2、重定向地址栏的地址变化,转发地址不变
3、重新定向可以访问外部网站,转发只能访问内部资源
4、转发的性能要优于重定向
路径总结
路径分为两种情况:
1.客户端路径,即给浏览器用的路径
<form action="/Day08-request/AServlet" > <a href="/Day08-request/AServlet" > <img src="/Day08-request/AServlet" > response.sendRedirect("/Day08-request/AServlet") Refresh:3;url=/Day08-request/AServlet
路径写法:
带"/" : "/" 表示相对于主机。例如:表单所在页面路径为 http://localhost:8080/Day08-request/login.jsp,则 "/" 代表http://localhost:8080/
不带"/":代表从当前目录找。(开发中一定不要出现不带"/"的情况)。例如:表单所在页面路径为 http://localhost:8080/Day08-request/info/login.jsp,则代表 http://localhost:8080/Day08-request/info/
2.服务器端路径
<url-pattern> 中配置为 /AServlet ,则代表 http://localhost:8080/Day08-request/AServlet
request.getRequestDispatcher("/AServlet") 代表 http://localhost:8080/Day08-request/AServlet
路径写法:"/"相对于项目。比如 "/" 可表示 http://localhost:8080/Day08-request/
以上是关于JavaWeb学习笔记四 request&response的主要内容,如果未能解决你的问题,请参考以下文章