python里的爬虫如何使用xpath 提取script里的元素?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python里的爬虫如何使用xpath 提取script里的元素?相关的知识,希望对你有一定的参考价值。
如图所示:我需要提取script里的clarityUrl:[]里的所有元素如何提取,用了很多方法都没有提取出来:我使用的是"//script[@id='_page_data']//@clarityUrl"谢谢各位路过的大侠伸出援助之手
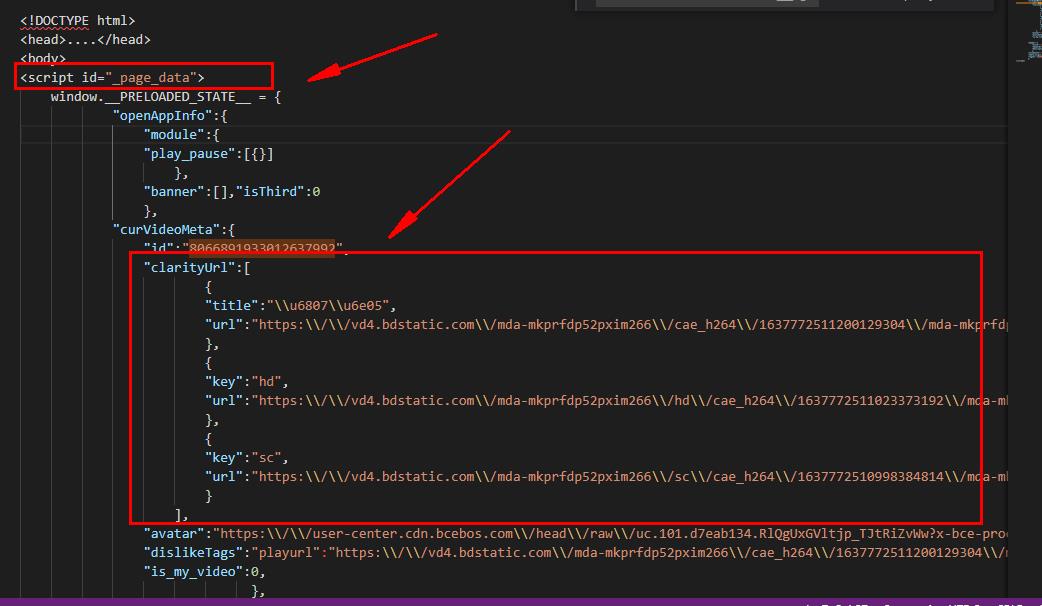
建议你先把content保存到本地文件,看看需要的内容有没有下载下来。
你这个属于script内容,看看直接正则能获得吗? 参考技术A
xpath是对文档节点进行操作,如果要提取里面的内容可以尝试以下操作
获取整个script标签内的内容,然后转成json,然后提取数据.
通过正则 re.findall() 进行提取。
对照着网上的程序和自己以前写的抓图的程序进行了重写,发现了很多问题。总结和归纳和提高学习效果的有效手段,因此对于这些问题做个归纳和总结,一方面总结学习成果,使之成为自己的东西,另一方面希望能够给其他初学爬虫的人一些启发。
爬虫程序核心是对网页进行解析,从中提取出自己想要的信息数据。这些数据可能是网址(url、href)、图片(image)、文字(text)、语音(MP3)、视频(mp4、avi……),它们隐藏在网页的html数据中,在各级等级分明的element里面,通常是有迹可循的,否则就没有爬取的必要了。提取的手段主要有三种:xpath、BeautifulSoup、正则表达式(Re)。下面分别进行介绍:
一)BeautifulSoup
从本心来说,我更喜欢用BeautifulSoup。因为它更符合直观语义特性,find()和find_all()函数已经基本上足够提取出任何的信息,对于身份证号、QQ号等特征特别明显的数据,顶多再加上一个正则表达式就完全OK了。
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
以上是关于python里的爬虫如何使用xpath 提取script里的元素?的主要内容,如果未能解决你的问题,请参考以下文章