Java高级特征
Posted 鹏达君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java高级特征相关的知识,希望对你有一定的参考价值。
1.static关键字
1)static用法总结
对于静态方法引用其他的静态方法和变量,在同个类中,直接调用,在不同类中,是用来类名加方法名或者类名加变量名,引用其他的非静态变量和方法,不管是否同一个类,都需要调用对象来使用。
对于非静态的方法引用其他的静态和不静态的变量和方法,在同一个类中,直接用,在不同类中,静态方法和成员需要应用类名,而非静态方法和变量则需要调用对象来用。
2)对于static方法和static变量的注意事项
static方法注意事项:
①.在静态方法中不能访问非静态成员方法和非静态成员变量,只能通过调用对象来用,但是在非静态成员方法中是可以访问静态成员方法/变量的。
②.即使没有显示地声明为static,类的构造器实际上也是静态方法。
③. static方法一般称作静态方法,由于静态方法不依赖于任何对象就可以进行访问,因此对于静态方法来说,是没有this的,因为它不依附于任何对象,既然都没有对象,就谈不上this了。
static变量注意事项:
①.static变量只能是成员变量。
②.static变量也称作静态变量,静态变量和非静态变量的区别是:静态变量被所有的对象所共享,在内存中只有一个副本,它当且仅当在类初次加载时会被初始化。
而非静态变量是对象所拥有的,在创建对象的时候被初始化,存在多个副本,各个对象拥有的副本互不影响。
③.static成员变量的初始化顺序按照定义的顺序进行初始化(多个static的成员变量的时候)。
常量(final):就是定义了一个量,其是不会变化的了,不管你在后面有没有改它,都不会变了。
3)static代码块
a.形式:eg: static{
startDate = Date.valueOf("1946");
endDate = Date.valueOf("1964");
}
b.用法说明:
①可以放在一个类中的任何地方;
②初次被加载,就是说如果再创建的话static代码块就不执行了,因为已经被收回了,只会执行一次;
③多个static块,按照static块的顺序去执行;
c.为什么说static块可以用来优化程序性能:因为只会在类加载的时候执行一次
d.何时使用:只需要进行一次的初始化操作基本都放在static代码块中进行
4)static关键字的误区
① static关键字不会改变类中成员的访问权限,其只是改变了在静态方法中不可以直接使用非静态方法和变量
②虽然对于静态方法来说没有this,但在非静态方法中能够通过this访问静态成员变量
③static是不允许用来修饰局部变量。
5)常见的笔试面试题
①
public class Test extends Base{
static{
System.out.println("test static");
}
public Test(){
System.out.println("test constructor");
}
public static void main(String[] args) {
new Test();
}
}
class Base{
static{
System.out.println("base static");
}
public Base(){
System.out.println("base constructor");
}
}
结果:
base static
test static
base constructor
test constructor
结果说明:先来想一下这段代码具体的执行过程,在执行开始,先要寻找到main方法,因为main方法是程序的入口,但是在执行main方法之前,必须先加载Test类,而在加载Test类的时候发现Test类继承自Base类,
因此会转去先加载Base类,在加载Base类的时候,发现有static块,便执行了static块。在Base类加载完成之后,便继续加载Test类,然后发现Test类中也有static块,便执行static块。在加载完所需的类之后,
便开始执行main方法。在main方法中执行new Test()的时候会先调用父类的构造器,然后再调用自身的构造器。因此,便出现了上面的输出结果。
(从main方法那个类开始加载,如果有该类有父类,先加载父类,之后执行main方法(注意:如果再main方法中又出来一个类没有加载还是要加载),如果有父类还是先父类开始)
②
.public class Test {
Person person = new Person("Test");
static{
System.out.println("test static");
}
public Test() {
System.out.println("test constructor");
}
public static void main(String[] args) {
new MyClass();
}
}
class Person{
static{
System.out.println("person static");
}
public Person(String str) {
System.out.println("person "+str);
}
}
class MyClass extends Test {
Person person = new Person("MyClass");
static{
System.out.println("myclass static");
}
public MyClass() {
System.out.println("myclass constructor");
}
}
结果:test static
myclass static
person static
person Test
test construstor
person MyClass
myclass constructor
结果说明:
首先加载Test类(其里面有main方法),因此会执行Test类中的static块。接着main方法执行new MyClass(),而MyClass类还没有被加载,因此需要加载MyClass类。
在加载MyClass类的时候,发现MyClass类继承自Test类,但是由于Test类已经被加载了,所以只需要加载MyClass类,那么就会执行MyClass类的中的static块。
在加载完之后,就通过构造器来生成对象。而在生成对象的时候,必须先初始化父类的成员变量,因此会执行Test中的Person person = new Person(),
而Person类还没有被加载过,因此会先加载Person类并执行Person类中的static块,接着执行父类的构造器,完成了父类的初始化,然后就来初始化自身了,
因此会接着执行MyClass中的Person person = new Person(),最后执行MyClass的构造器。
(先加载有main方法的类(有父类先加载父类),之后执行main方法(有类继续加载)(有父类的话先执行父类的方法),加载完后就通过构造器来生成对象(也还是从有main方法的
类开始执行但(如果有父类的话,先执行父类的构造器)),如果再生成的对象中有新的类出现,继续加载,且执行完这个类的构造方法(有父类的继续加载),之后按照顺序执行完代码。)
③.
public class Test {
static{
System.out.println("test static 1");
}
public static void main(String[] args) {
}
static{
System.out.println("test static 2");
}
}
结果:
test static 1
test static 2
结果说明:虽然在main方法中没有任何语句,但是还是会输出,原因上面已经讲述过了。另外,static块可以出现类中的任何地方(只要不是方法内部,记住,任何方法内部都不行),
并且执行是按照static块的顺序执行的
2.final关键字
1)可以修饰类,函数,变量;
2)被fianl修饰的类不可以被继承(如果使用这个关键词修饰类是为了避免被继承被子类复写功能);
3)被final修饰的方法不可以被复写;
4)被final修饰的变量是一个常量,只能赋值一次,既可以修饰成员变量,又可以修饰局部变量(当在描述事物时,一些数据的出现值是固定的,那么这时为了增强阅读性,都给这些值起个名字,方便于阅读,而这个值不需要改变,所以
加上final修饰,作为常量,常量的书写规范所有字母都大写,如果由多个单词组成,单词间通过_连接);
5)内部类定义在类中的局部位置上时,只能访问该局部被final修饰的局部变量。
3.抽象类
1)抽象类的特点:
①抽象方法一定在抽象类中(但抽象类中不一定有抽象方法)
②抽象方法和抽象类都必须被abstract关键字修饰(但不代表方法都为抽象类,可为其他)
③抽象类不可以用new创建对象,因为调用抽象方法没意义
④抽象类中的抽象方法要被使用,必须由子类复写其所有的抽象方法后建立子类对象调用,如果子类只覆盖了部分抽象方法,那么该子类还是抽象类。
⑤抽象类中可以定义抽象方法,但是一般类不行
2)例子
abstract class student{
abstract void study();//这里的方法体不用写
abstract void study1();
}
class basestudent extends student{
void study(){}
void study1(){}//如果这个没复写该类也还是抽象类
}
4.接口
1)接口与抽象类
①接口中的所有方法都是抽象的,而抽象类可以定义带有方法体的不同方法;
②一个类可以实现多个接口,但只能继承一个抽象父类;
③接口与实现它的类不构成类的继承体系,即接口不是类体系的一部分,因此,不相关的类也可以实现相同的接口,而抽象类是属于一个类的继承体系,并且一般位于类体系的顶层。
2)接口的定义
①理解:使用interface来定义一个接口。接口定义同类的定义类似,也是分为接口的声明和接口体,其中接口体由常量定义和方法定义两部分组成。
②例子:
public interface CalInterface
{
final float PI=3.14159f;//定义用于表示圆周率的常量PI
float getArea(float r);//定义一个用于计算面积的方法getArea()
float getCircumference(float r);//定义一个用于计算周长的方法getCircumference()
}
注意:为什么只能定义常量值?
因为接口中的方法都是抽象方法,只有方法的声明,而没有方法体。如果在一个类中定义了一个变量的话,就没有办法对该变量进行赋值操作,而变量就没有了其存在的价值。
3)实现接口
①.基本格式如下:
[修饰符] class <类名> [extends 父类名] [implements 接口列表]{
................
}
注意:当接口列表中存在多个接口名时,各个接口名之间使用逗号分隔。
②例子
public class Cire implements CalInterface
{
public float getArea(float r)
{
float area=PI*r*r;//计算圆面积并赋值给变量area
return area;//返回计算后的圆面积
}
public float getCircumference(float r)
{
float circumference=2*PI*r; //计算圆周长并赋值给变量circumference
return circumference; //返回计算后的圆周长
}
public static void main(String[] args)
{
Cire c = new Cire();
float f = c.getArea(2.0f);
System.out.println(Float.toString(f));
}
}
注意:
a.在类中实现接口时,方法的名字、返回值类型、参数的个数及类型必须与接口中的完全一致,并且必须实现接口中的所有方法。
b.因为可以进行多个接口实现, 这时就可能出现(多个接口中的)常量或方法名冲突的情况,解决该问题时,如果常量冲突,则需要明确指定常量的接口,这可以通过“接口名.常量”实现。
如果出现方法冲突时,则只要实现一个方法就可以了。
4)多重继承
理解:就是通过接口来完成多重继承。格式为先继承再实现,接口可多个,用","隔开。
通过继承扩展接口
举例说明
interface Shape{
void draw();}}
//需要加多一个功能
interface A extends Shape{
void b();}
//完成了扩展
5.包
1)包的概念:包(package)是Java提供的一种区别类的名字空间的机制,是类的组织方式,是一组相关类和接口的集合,它提供了访问权限和命名的管理机制。
2).Java中提供的包主要有以下3种用途:
① 将功能相近的类放在同一个包中,可以方便查找与使用。
② 由于在不同包中可以存在同名类,所以使用包在一定程度上可以避免命名冲突。
③ 在Java中,某次访问权限是以包为单位的。
3)创建包
a:创建包package语句的语法格式如下:
package 包名;
b说明: 1.其用于指定包的名称,包的名称要为合法的 Java标识符。
2.当包中还有包时,可以使用“包1.包2.…….包n”进行指定,其中,包1为最外层的包,而包n则为最内层的包。
3.package 语句通常位于类或接口源文件的第一行。
c.例如,定义一个类Circ,将其放入com.wgh包中的代码如下:
package com.wgh;
public class Circ {
final float PI=3.14159f; //定义一个用于表示圆周率的常量PI
// 定义一个绘图的方法
public void draw(){
System.out.println("画一个圆形!");
}
}
4)使用包中的类
a.我们可以使用包中的什么类:类可以访问其所在包中的所有类,还可以使用其他包中的所有public类。
b.下面为使用其他包中的public类的方法:
①使用长名引用包中的类 :在每个类名前面加上完整的包名即可。
例如,创建Circ类(保存在com.wgh包中)的对象并实例化该对象的代码如下:
com.wgh.Circ circ=new com.wgh.Circ();
② 使用import语句引入包中的类
import语句的基本语法格式为:import 包名1[.包名2.……].类名|*;
当存在多个包名时,各个包名之间使用“.”分隔,同时包名与类名之间也使用“.”分隔,而类名可以换成*:其表示表示包中所有的类。
例如,引入com.wgh包中的Circ类的代码如下:
import com.wgh.Circ;
如果 com.wgh包中包含多个类,也可以使用以下语句引入该包下的全部类。
import com.wgh.*;
5)关于java的static import
a.静态导入的作用:1.对一些工具性的,常用的静态方法进行直接引用。
2.对常数变量进行直接引用。
(直接应用就是说不用引用类名,直接使用方法名就可以了,目的就是为了方便)
b.语法: 跟import差不多,只不过import改为 import static。
c.注意事项:
①静态导入不可出现二义性
②过多的static import也许可能影响程序的可读。
6)包名与包成员的存储位置
package com.wgh;
public class Circ {
final float PI=3.14159f; //定义一个用于表示圆周率的常量PI
// 定义一个绘图的方法
public void draw(){
System.out.println("画一个圆形!");
}
}
上面代码中的
Circ类的路径为:C:\\com \\wgh\\Circ.java.(如果保存到C盘根目录下)
该包的路径为:C:\\com \\wgh(如果保存到C盘根目录下)
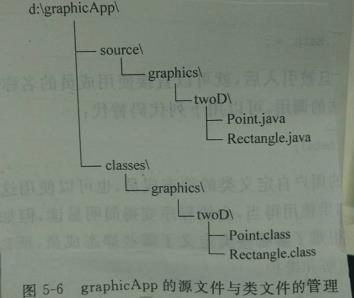
7)java源文件与类文件的管理

6.泛型与集合类
泛型
1)为什么需要泛型?
因为往集合里面加对象的时候,集合是不会记住此对象的类型的,当再次从集合中取出此对象时,该对象的类型会变成object类型(所以如果不用泛型,直接用集合,需要人为的强制转换为具体的目标类型),而如果使用了泛型,其在编译之后就会变成其定义的形式类型。而如果本身类型和目标类型不同,就会产生"java.lang.ClassCastException"异常。所以如果没有定义泛型,该问题产生在运行时才会发现,而使用了泛型,因为拥有了它,我们就可以在编译时就可以把这种问题暴露进而修改。
2)泛型的定义:泛型即“参数化类型”
比如 :List<String> list = new ArrayList<String>();其定义了这个集合只能加String类的对象。
3)泛型应用种类
(1)泛型类
class Utils<QQ>
{
private QQ q;
public void setObject(QQ q)
{
this.q=q;
}
public QQ getObject()
{
return q;
}
}
class GenericDemo3
{
public static void main(String[] args)
{
Util<Worker> u=new Util<Worker>();
u.setObject(new Student()):
Worker w=u.getObject();
}
}
分析:为什么需要泛型类?
①可以限定里面的对象是什么类型
②可以随时创建另一个数据类型对象
注意:
泛型类型在逻辑上看以看成是多个不同的类型,实际上都是相同的基本类型。(简单点说就是 传入不同泛型实参的泛型类在内存上只有一个,但是数据还是会有变化的);
解释说明:在编译过程中,对于正确检验泛型结果后,会将泛型的相关信息擦出,也就是说,成功编译过后的class文件中是不包含任何泛型信息的。泛型信息不会进入到运行时阶段。
(2)泛型方法
class Demo
{
public <T> void show(T t)
{
System.out.println("show:"+t);
}
public <Q> void print(Q q)
{
System.out.println("print:"+q);
}
}
class GenericDemo4
{
public static void main(String[] args)
{
Demo d=new Demo();
d.show("hahah");
d.show(new Integer(4));
d.print("heihei");
}
}
//正常运行。输出hahah,4,heihei。
分析:
a:为什么要使用泛型方法呢?
因为泛型类要在实例化的时候就指明类型,如果想换一种类型,不得不重新new一次,可能不够灵活;而泛型方法可以在调用的时候指明类型,更加灵活。
b:结论:
①泛型还可以用在方法上面且定义泛型方法时;
②在返回值前边加一个<T>,是用来声明这是一个泛型方法(没有其他的意义);
③泛型方法,是在调用方法的时候指明泛型的具体类型。
(3)泛型类与泛型方法的结合(常见)
class Demo<T>
{
public <T> void show(T t)
{
System.out.println("show:"+t);
}
public <Q> void print(Q q)
{
System.out.println("print:"+q);
}
/* public static void method(T t)
{
System.out.println("method"+t);
}
特殊之处;静态方法不可以访问类上定义的泛型。
如果静态方法操作的应用数据类型不确定,可以将泛型定义在方法上。下面为改动后的方法
*/
public static <T> void method(W t)
{
System.out.println("method;"+t);
}
}
class GenericDemo4
{
public static void main(String[] args)
{
Demo <String> d=new Demo<String>();
d.show("hahah");
//d.show(new Integer(4));加入这句编译失败,泛型类。
d.print("heihei");
d.print(5);//不会编译失败,因为其应用泛型方法
d.method("hahahha");
}
}
总结:泛型类和泛型方法很常连在一起用,且静态方法不可以访问类定义的泛型。
(4)泛型接口
interface Inter<T>
{
void show(T t);
}
class InterImpl<T> implements Inter<T>
{
public void show(T t)
{
System.out.println("show;"+t);
}
}
class GenericDemo5
{
public static void main(String[] args)
{
InterImpl<Integer> i=new InterImpl<Integer>();
i.show(4);
}
}
分析:
a.:为什么需要泛型接口::因为拥有泛型接口可以使我们使用泛型类有更好的扩展性。
b:结论:其实现泛型结构的类也要泛型。
注意:在集合中实现接口创造比较器哪里实现泛型接口的类不用泛型
(5)集合(其本质是用前面的类型做为基础而形成的)
class GenerichDemo
{
public static void main(String[] args)
{
ArrayList<String> a1=new ArrayList<String>();
a1.add("abc01");
a1.add("abc0991");
a1.add("abc014");
Iterator<String> it=al.iterator();
while(it.hasNext()){
String s=it.next();
System.out.println(s+";"+s.length());
}
}
}//如果往a1加其他数据类型会在编译时报出错误
结论:使用时放在类名和Iterator后面。
4)通配符(即"?")
a.为什么需要通配符?
因为需要传入不同的泛型类型,如果只确定一个泛型类型,这样在代码上的效率很低,为了提高效率于是加了通配符。从功能上可知其是任何类型的父类。
b.对通配符的理解:
①其虽然效果像形参,但其不是形参,而是代替了实参,包括下面所说的上限,下线也一样;
②通常只放在方法中的参数,用于集合取出时满足我们需要的数据。
c.简单通配符的使用:
class GenericDemo6
{
public static void main(String[] args)
{
ArrayList<String> a1=new ArrayList<String>();
a1.add("abcd1");
a1.add("abcd2");
a1.add(abcd3");
ArrayList<Integer> al1=new ArrayList<Integer>();
al1.add(4);
al1.add(5);
al1.add(6);
printColl(al);
printColl(al1);
}
public static void printColl(ArrayList<?> al)
{
Iterator<?> it=al.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
}
}
}
d.通配符上限
①为什么需要通配符上限?
如果只是用了?这个的话,其是所有类型的父类,如果我想要特殊的对象才能够执行的话,我就要设立一个条件,而通配符上限就是其中的一种,其代表只有是某个类的子类才可以编译通过。
注意: 通常只用在方法中的参数,用于防止从集合取出时的数据不满足我们的要求。
②例子:
import java.util.*;
class GenericDemo6
{
public static void main(String[] args)
{
ArrayList<Person> al=new ArrayList<Person>();
al.add(new Person("abc1"));
a1.add(new Person("abc2"));
al.add(new Person("abc3"));
ArrayList<Student> al1=new ArrayList<Student>();
al1.add(new Student("abc--1"));
al1.add(new Student("abc--2"));
al1.add(new Student("abc--3"));
printColl(al1);
}
public static void printColl(ArrayList<? extends Person> al)
{
Iterator<? extends Person> it=al.iterator();
while(it.hasNext())
{
System.out.println(it.next().getName());
}
}
}
class Person
{
private String name;
Person(String name)
{
this.name=name;
}
public String getName()
{
return name;
}
}
class Student extends Person
{
Student(String name)
{
super(name);
}
}
e.通配符下限
①为什么需要通配符下限:同样的道理,设立一个条件,要传进去的对象要是其下限的父类或是其父类的父类等才行,表示方法是 “? super 一个类”。
注意:通常只用在方法中的参数,用于防止从集合取出时的数据不满足我们的要求。
②例子:
import java.util.*;
class GenericDemo6
{
public static void main(String[] args)
{
ArrayList<Person> al=new ArrayList<Person>();
al.add(new Person("abc1"));
a1.add(new Person("abc2"));
al.add(new Person("abc3"));
ArrayList<Student> al1=new ArrayList<Student>();
al1.add(new Student("abc--1"));
al1.add(new Student("abc--2"));
al1.add(new Student("abc--3"));
printColl(al);
}
public static void printColl(ArrayList<? super Student> al)
{
Iterator<? extends Person> it=al.iterator();
while(it.hasNext())
{
System.out.println(it.next().getName());
}
}
}
class Person
{
private String name;
Person(String name)
{
this.name=name;
}
public String getName()
{
return name;
}
}
class Student extends Person
{
Student(String name)
{
super(name);
}
}
5)泛型格式书写总结
①集合 a b<>=new a<>;
②由集合引申出来的迭代器; Iterator<? extends Person> it=al.iterator();
③方法 public <T> void show(T t)
public static <T> void show(T t)
④类 class Utils<QQ>
⑤接口 interface Inter<T>
{
void show(T t);
}
class 类名(可有泛型,也可以没有) implements Inter<T>
{
public void show(T t)
{
System.out.println("show;"+t);
}
} (两种)
集合
1)为什么会出现集合类?
面向对象语言事物的体现是以对象的形式,所以为了方便对多个对象的操作,就对对象进行存储,集合就是存储对象最常用的一种方式。
2)数组和集合类同是容器,有什么不同?
a.数组虽然也可以存储对象,但长度是固定的,集合长度是可变的。
b.数组中可以存储基本数据类型,但集合只能存储对象。
3)集合类的特点
a.集合只用于存储对象
b.集合长度可变
c.集合可以存储不同类型的对象
4)集合框架

常用类总结:
Collection包括List,Set,Queue,list的三个实用类包括ArrayList,LinkedList,Vector。JDK提供了Set三个使用类包括HashSet,TreeSet,LinkedHashSet。
注意:为什么会出现那么多的容器?
因为每一个容器对数据的存储的逻辑方式都是不同。这个存储方式叫做数据结构。
5)对集合框架的简单理解:





6)集合常用方法
添加 add():注意:返回的对象是Object
删除 remove()
清空集合 clear()
判断集合时候有某元素 contains(某元素)
判断集合是否为空 isEmpty()
获取集合的个数(长度) size()
7)集合中对象的取出方法(迭代器)
使用方法:a:
ArrayList al=new ArrayList();
al.add("java1");
al.add("java2");
Iterator it=al.iterator();//获取迭代器,用于取出集合中的元素,下面为取出方法
while(it.hasNext()){
Sop(it.next());
}
b(简化版):
ArrayList al=new ArrayList();
al.add("java1");
al.add("java2");
for(Iterator it=al.iterator();it.hasNext();){
Sop(it.next()
}
8)List集合
a.特点:元素是有序的,元素可以重复。因为该集合体系有索引。
b.List的特有方法(凡事可以操作角标的方法都是该体系特有的方法)
增 add(index,element)
addAll(index,Collection)
删 remove(index)
改 set(index,element)
查 get(index);
subList(from,to)包头不包尾
ListIterator()
c.List拥有特有的迭代器。
c1:为什么会有特有的迭代器:因为Iterator方法是有限的,只能对元素进行判断,取出,删除的操作,如果想对其他的操作如添加,修改等,就需要使用其子接口ListIterator
c2:怎么获得该迭代器:
ListIterator li=al.ListIterator();
while(li.hasNext()){
Object obj=li.next();
if(obj.equals("java2"))
li.set("java6");
}
d:List集合判断元素是否相同的依据的是equals方法,比如说contains,remove根本方法就是equals方法
但两者有不同,contains会全部比较一遍,而remove会确定要删除的对象去跟集合的全部元素比较。
注意:equals方法系统自动调用。
9)List集合的子集合
①LinkedList
a:该集合的特点:底层使用的链表数据结构,特点是增删速度很快,查询稍慢。
b:LinkedList特有的方法:
addFirst();
addLast();
getFirst();
getLast();
removeFirst();
removeLast();
注意:getFirst();
getLast();
这两种方法是获取对象但是不删除对象(元素),如果集合中没有元素会出现NosuchElementException
removeFirst();
removeLast();
这两种方法是获取对象且删除对象(元素),如果集合中没有元素会出现NosuchElementException
在JDK1.6版本之后,这四种方法被已下取代
peekFirst();
peekLast();
不删除
pollFirst();
pollLast();
删除
②Vector
a.该集合特点:底层是数组数据结构,线程同步,后被ArrayList替代了
b:枚举:枚举就是Vector特有的取出方法,跟迭代器很像。
c:后来被取代的原因是:因为枚举的名称以及方法的名称都太长了,不方便,所以被取代了。
d:枚举的使用方法
Vector c=new Vector();
c.add("java1");
c.add("java2");
Enumeration en=c.elements();
while(en.hasMoreElements()){
SOP(en.nextElement())}
③ArrayList
a:该集合的特点:底层的数据结构使用的是数据结构,特点是查询速度很快,但是增删稍慢,线程不同步。
b:去除ArrayList集合中的重复元素
10)Set的子集合
①HashSet
a:set集合特点:元素是无序的,元素不可以重复
b:HashSet的底层数据结构:哈希表(存了一堆哈希值的表)
c:HashSet是如何保证元素的唯一性的:通过元素的两种方法,hashcode和equals方法,首先比较哈希表的值是不是相等,才会使用equals方法看返回值是不是为true(即说明hashcode值不同不使用equals方法
,这两种方法都是系统自动调用,但是在自定义类的时候需要复写。
②TreeSet
a:重要功能:可以对Set集合中的元素进行排序,且可以自己设定该规则,有两种排序方式。
(比较器一般放在创建该集合的()里面,或者
b:底层数据结构:二叉树
注意:二叉树规律:b1:以加入第一个的为参照物开始,比其小的左边,比其大的右边,且如果往右走或者左走还有元素的话,使用上述的规律继续比较,直到下面没有元素为止。
b2:由左边往上走,其数变大,由右往下走,其数变大。
b3:输出是小的先出
c:保证元素唯一性的依据是:compareTo方法
d:排序的两种方式:
d1:让元素自身具备比较性,元素需要实现Comparable接口,覆盖comparaTo方法
d2:当元素自身不具备比较性或者具备的比较性不是我们想要的,这时我们就要自己设定一个比较器,将比较器对象作为参数传递给TreeSet集合的构造函数。//这个方法为主
11)Map集合
a.该集合特点:该集合存储键值对,一对一对往里存,而且要保证键的唯一性。
b.该集合的常用方法:
1.添加
put(K key,V value)
putAll(Map<? extends K,? extends V> m)
2.删除
clear()
remove(Object key)
3.判断
containsValue(Object value)
containsKey(Object key)
isEmpty()
4.获取
get(Object key)
size()
value()
entrySet()
keySet()
c.Map集合分出的三个集合。
c1.Hashtable:底层是哈希表数据结构,不可以存入null键null值,该集合是线程同步。
c2.HashMap:底层是哈希表数据结构,允许使用null值和null键,该集合是不同步。
c3.TreeMap:底层是二叉树数据结构,线程不同步,可以用于给map集合中的键进行排序。
注意:Set底层就是使用了Map集合。
d.Map集合的两种取出方式:
d1:Set<keySet> entryset:将map集合转化Set集合,在Set集合存储了map的键值,利用迭代器,根据get方法。获取每一个键对应的值。
d2:Set<Map.Entry<K,V>> entrySet:将map集合中的映射关系存入到了Set集合中,而这个关系的数据类型就是:Map.Entry,之后利用
迭代器,利用getKey()和getValue方法获取关系中的键和值。
实例:map练习(TreeMap)
import java.util.*;
class StuNameComparator implements Comparator<Student>
{
public int compare(Student s1,Student s2)
{
int num=s1.getName().compareTo(s2.getName());
if(num==0)
return new Integer(s1.getAge()).compareTo(new Integer(s2.getAge()));
return num;
}
}
class Maptest2
{
public static void main(String[] args)
{
TreeMap<Student,String> tm=new TreeMap<Student,String>(new StuNamecomparator());
tm.put(new Student("alisi2",23),"nanjing");
tm.put(new Student("blist2",25),"beijing");
tm.put(new Student("lisi4",24),"wuhan");
tm.put(new Student("list5",25),"hunan");
Set<Map.Entry<Student,String>> entrySet =tm.entrySet();
Iterator<Map.Entry<Student,String>>it =entrySet.iterator();
while(it.hasNext())
{
Map.Entry<Student,String> me=it.next();
Student stu=me.getKey();
String addr=me.getValue();
System.out.println(stu+":::"+addr);
}
}
}
class Person
{
private String name;
Person(String name)
{ return name;
}
public String toString()
{
return "person;"+name;
}
}
class Student extends Person
{
Student(String name)
{
super(name);
}
}
e.Map.Entry的Entry其实也是一个接口,它是Map接口中的一个内部接口。
interface Map
{
public static interface Entry
{
public abstract Object getKey();
public abstract Object getValue();
}
}
class HashMap implements Map
{
class hash implements Map.Entry
{
public Object getKey(){}
public Object getValue(){}
}
}
12)集合框架工具类——Collections
a.代码实例:
import java.util.*;
class CollectionsDemo
{
public static void main(String[] args)
{
sortDemo();
}
public static void sortDemo()
{
List<String> list=new ArrayList<String>();
list.add("abcd");
list.add("aaa");
list.add("z");
list.add("kkkkkk");
list.add("qq");
sop(list);
Collections.sort(list);//进行自然排序
// Collections.sort(list,new StrLenComparator());进行长度排序
sop(list);
String max=Collections.max(list);
sop("max="+max)//打出自然排序的最右边的值
/* String max=Collections.max(list,new StrLenComparator());
sop("max"+max);//打出长度排序最右边的值
*/
}
public static void sop(Object obj)
{
System.out.println(obj);
}
}
class StrLenComparator implements Comparator<String>
{
public int compare(String s1,String s2)
{
if(s1.length()>s2.length())
return 1;
if(s1.length()<s2.length())
return -1;
return s1.compareTo(s2);
}
}
b.常用Collection方法总结:
1.halfSearch
/*int index=halfSearch(list,"aaaa",new StrLenComparator());
sop("index="+index);该方法就是按照什么排序后找出aaaa在那个
角标,从而打出其号码,如果没有该个元素,则按照这个排序方法排序下去应该
在那个位置插入,得出这个号码a,返回值为-a-1;*/
方法原理:
public static int halfSearch<List<String> list,String key)
{
int max,min,mid;
max=list.size()-1;
min=0;
while(min<=max)
{
mid=(max+min)>>1;
String str=list.get(mid);
int num=str.compareTo(key);
if(num>0)
max=mid+1;
else if(num<0)
min=mid+1;
else
return mid;
}
return -min-1;
}
2.fill()
使用规律;Collections.fill(list,"pp")
作用;将list中的所有元素转化成pp
3replaceAll()
使用法则;Collections.replaceAll(list,"aaa","pp")
作用;将list集合中的aaa元素改成pp。
4reverse()
作用;反转某集合的元素。
5reverseOrder()
部分代码
TreeSet<String> ts=new TreeSet<String>(Collections.reverseOrder());
//该方法是强行逆转ts中自然排练顺序
TreeSet<String> ts=new TreeSet<String>(Collections.revsenew StrLenComparator());
//该方法是强行逆转ts按某种特殊的方式排序的顺序(特定方式代码省略了)
ts.add("abcde");
ts.add("aaa");
ts.add("kkk");
ts.add("ccc");
Iterator it=ts.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
}
6 swap()
使用法则;Collections.swap(list,1,2)
作用;将list中的角标为1和2的元素调换。
7shuffle()
使用法则;Collections.shuffle();
功能;每调用一次就重新洗牌一次。
8.toArray()
功能:集合变数组
代码展示:
import java.util.*;
class CollectionToArray
{
public static void main(String[] args)
{
ArrayList<String> al=new ArrayList<String>();
al.add("abc1");
a1.add("abc2");
al.add("abc1");
/*
1,指定类型的数组到底要定义多长呢?
当指定类型的数组长度小于了集合的size,那么该方法内部会创建一个新的数组,
长度为集合的size。
当指定类型的数组长度大于了集合的size,就不会新创建了数组,而是使用传递
进来的数组。所以创建一个刚刚好的数组最优。al.size();
2,为什么要将集合变数组?
为了限定对元素的操作,不需要进行增删了。
*/
String[] arr=al.toArray(new String(al.size()));
System.out.println(Arrays.toString(arr));
}
}
13)Arrays;用于操作数组的工具类,里面都是静态方法
例子: asList;将数组变成list集合
import java.util.*;
class ArraysDemo
{
public static void main(String[] args)
{
//int[] arr={2,4,5};
//System.out.println(Arrays.toString(arr));
//将arr中的元素打出来
String[] arr=("abc","cc"c"kkkk");
list li=Arrays.asList(arr);
//将arr数组转成集合li
//为什么要转成集合,方便与使用集合中的各种方法而不用自己写
/*注意;将数组变成集合,不可以使用集合的增删方法,因为数组的
长度是固定的,如果增删了,会发生UnsupportedOperationException*/
/*int[] nums={2,4,5};
List<int[]> li=Arrays.asList(nums);
sop(li);
其会打印出num这个数组,而不是2.4,5
因为如果数组中的元素都是对象,那么变成集合时,数组中的元素直接转成集合中的元素
如果数组中的元素都是基本数据类型,那么会将该数组作为集合中的元素存在
所以要想打印出2.4.5
必须改动
integer[] nums={2,4,5};
List li=Arrays.asList(nums);
sop(li);
*/
}
}
7.包装类与自动装箱和拆箱
①String
a.Java中String是一个特殊的包装类数据有两种创建形式:
String s = "abc";
String s = new String("abc");????
第一种:先在栈中创建一个对String类的对象引用变量s,然后去查找"abc"是否被保存在字符串常量池中,如果没有则在栈中创建三个char型的值\'a\'、\'b\'、\'c\',
然后在堆中创建一个String对象object,它的值是刚才在栈中创建的三个char型值组成的数组{\'a\'、\'b\'、\'c\'},接着这个String对象object被存放进字符串常量池,
最后将s指向这个对象的地址,如果"abc"已经被保存在字符串常量池中,则在字符串常量池中找到值为"abc"的对象object,然后将s指向这个对象的地址。
特点:JVM会自动根据栈中数据的实际情况来决定是否有必要创建新对象。
???
第二种:可以分解成两步1、String object = "abc"; 2、String s = new String(object); 第一步参考第一种创建方式,而第二步由于"abc"已经被创建并保存到字符串常量池中
因此jvm只会在堆中新创建一个String对象,它的值共享栈中已有的三个char型值。
特点:一概在堆中创建新对象,而不管其字符串值是否相等,是否有必要创建新对象。
b.String常用的方法
1.获取
int length(); //获取长度
char charAt(int index) ; //获取指定位置的字符
int indexOf(int ch); //返回的是ch在字符串中第一次出现的位置
int indexOf(int ch,int fromIndex); //是fromIndex指定位置开始,获取ch在字符串中出现的位置。
int indexOf(String str); //返回的是str在字符串中第一次出现的位置,没有返回-1.
int indexOf(String str,int fromIndex); //从fromIndex指定位置开始,获取str在字符串中出现的位置。
int lastIndexOf(int ch); //从最右边读起(当你知道某个字符在后边或者可能,可以通过这个方法增加速率或者确认)
2.判断
boolean contains(str); //字符串中是否包含str子串
boolean isEmpty(); //字符串是否是空,原理判断长度是否为0
boolean startsWith(str); //字符串是否以str开头
boolean endsWith(str); //字符串是否以str结尾
boolean equals(str); //判断字符串内容是否相同。复写了Object类中的equals方法
boolean equalsIgnoreCase(); //判断内容是否相同,并忽略大小写。
3.转换
a.将字符数组转成字符串
构造方法:
String(char[] a); //将字符数组转成字符串
String(char[] a,offset,count); //将字符数组中的一部分转成字符串
静态方法:
static String copyValueOf(char[] a);
static String copyValueOf(char[] date,int offset,int count)
static String ValueOf(char[] a);
b.将字符串转成字符数组
char[] toCharArray();
c.将基本数据类型转成字符串
static String valueOf(int a)
static String valueOf(double a)
4.替换
String replace(oldchar,newchar);
5.切割
String[] split(regex);
6.子串,获取字符串中的一部分
String substring(begin);
String substring(begin,end);
7.转换成大写或小写
String toUpperCase();
String toLowerCase();
8.将字符串两端的多个空格去除
string trim();
9.对两个字符串进行自然顺序的比较
int compareTo(string);
//如果相同,返回0,如果字符串小于字符串参数,负数,大于,正数。
②StringBuffer
a.理解:
1.字符串的组成原理就是通过该类实现的。
2.可以对字符串内容进行增删
3.其是一个容器
4.很多方法和String相同,长度可变。
b.特点:
1.长度可变化的
2.可以字节操作多个数据类型,但最终会通过toString方法变成字符串
c.方法:
1.存储:
StringBuffer append(); //将指定数据作为参数添加到已有数据结尾处
StringBuffer insert(index,数据); //可以将数据插入到index位置。
2.删除
StringBuffer delete(start,end); //删除缓冲区中的数据,包含start,不包含end
StringBuffer deleteCharAt(index); //删除指定位置的字符
3.获取
char charAt(int index);
int indexOf(String str);
int lastIndexOf(String str);
int length();
String substring(int start,int end);
4.修改
StringBuffer replace(start,end,String);
void setCharAt(int index,char ch);
5.反转
StringBuffer reverse();
6.void getChars(int srcBegin,int srcEnd,char[] det,int detBegin)
//该方法为将该字符串从srcBeigin到srcEnd个位置放在det数组中,并且是从detbegin这个位置开始放
d.StringBuffer和StringBuilder
StringBuffer是线程同步,开发建议使用这个,升级三个因素 提高效率,简化书写,提高安全性
StringBuilder是线程不同步
③基本数据类型对象包装类
byte Byte
short short
int Integer
long Long
boolean Boolean
float Float
double Double
char Character
a.功能:
基本数据类型对象包装类的最常见作用:就是用于基本数据类型和字符串类型之间做转换。
//静态方法
double b=Double.parseDouble("12.23"); //将字符串转换成double类型
char b=Character.parseCharacter("a"); //将字符串转换成字节类型
//非静态方法
Integer i=new Integer("123");
int num=i.intValue();
b.拆箱装箱原理
class IntegetDemo1
{
public static void main(String[] args)
{
Integer x=4; //自动装箱,将值付给x
x=x+2; //x进行自动拆箱,变成了int类型,和2进行加法运算,之后再进行装箱赋值給x。
}
}
c.十进制转成其他制(都用Interger且为静态)
toBinaryString() //转成二进制
toOctalString() //转成八进制
toHexString() //转成十六进制
d.将其他进制转成十进制
parseInt(String,int);
int x=Integer.parseInt("110",10);
将其转成十进制
以上是关于Java高级特征的主要内容,如果未能解决你的问题,请参考以下文章