Java并发编程深入学习
Posted babyyage
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java并发编程深入学习相关的知识,希望对你有一定的参考价值。
基本概念
在实践中,为了更好的利用资源提高系统整体的吞吐量,会选择并发编程。但由于上下文切换和死锁等问题,并发编程不一定能提高性能,因此如何合理的进行并发编程时本文的重点,接下来介绍关于锁最基本的一些知识(选学)。
- volatile:轻量,保证共享变量的可见性,使得多个线程对共享变量的变更都能及时获取到。其包括两个子过程,将当前处理器缓存行的数据写回到系统内存,之后会使其他CPU里缓存了该内存地址的数据无效。
- synchronized:相对重量,其包含3种形式,针对普通同步方法,锁是当前实例对象;针对静态同步方法,锁是当前类的Class对象;对于同步代码块,锁是Synchonize括号内配置的对象。此外,synchronize用的锁存在ava对象头中,编译后会插入类似
monitorenter, monitorexit的代码。 - 锁状态:包括无锁状态,偏向锁状态,轻量级锁状态,重量级锁状态。Tip,锁可以升级但不能降级。
-
Java实现原子操作:可以通过锁和循环CAS来实现原子操作,不过其也存在3个问题,包括ABA问题,通过版本号解决;循环时间长开销大,通过
pause指令减少自旋带来的开销;只能保证一个共享变量的原子操作,通过AtomicRefence保证引用对象间的原子性,接下来看一个最简单的CAS操作示例。protected void safeCount() { for (;;) { int i = atomicI.get(); if (atomicI.compareAndSet(i, ++i)) break; } }
线程
这部分和之后的锁是基础部分的核心内容,需要好好理解。一般来说,线程都是操作系统最小的调度单元,一个进程中可以包含多个线程,每个线程都拥有自己的计数器、堆栈和局部变量。系统会采用分时的形式调度运行的线程,OS会分出一个个的时间片到线程,此外还可以给线程设置优先级,来保证优先级高的线程获得更多的CPU时间。通过下面的示例代码可以发现,java程序的运行不仅就是main线程,还有清楚Reference的线程、调用对象finalize方法的线程、分发处理发送给JVM信息的线程、Attach Listener线程等。
// 获取管理线程的MXbean
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
ThreadInfo[] threadInfos = threadMXBean.dumpAllThreads(true, true);
// 打印线程信息
for (ThreadInfo threadInfo : threadInfos) {
System.out.println("[" + threadInfo.getThreadId() + "]" + threadInfo.getThreadName());
}-
线程的状态:Java线程的整个生命周期包括6种不同状态,分别是
NEW初始状态,线程被构建但未start;RUNNABLE运行状态,Java线程将OS中的就绪和运行两种状态都称作“运行中”;BLOCKED阻塞状态,表示线程阻塞于锁;WAITING等待状态,表示线程进入等待状态,进入该状态表示当前线程需要等待其他线程做出特定动作(通知或中断);TIME_WAITING超时等待状态,该状态不同于WAITING,其会在指定的时候后返回;TERMINATED终止状态,可以使用interrupt()合理的终止线程,表示当前线程已经执行完毕,之后通过一张Java线程状态图来做个形象的了解。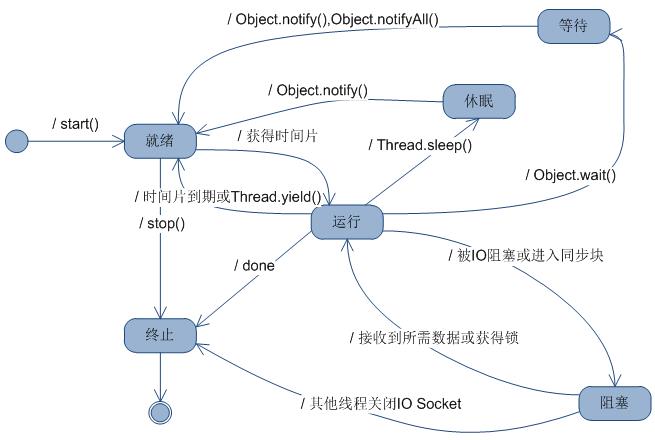
Daemon守护线程概念非常简单,java的虚拟机只有在不存在Daemon线程时才会退出。 -
线程间通信有一个的经典范式,等待/通知机制。一个线程修改了一个对象的值,而另一个线程感知到了变化,然后进行相应的操作,整个过程开始于一个线程,而最终执行的是另一个线程。
//等待方:1.获取对象的锁 2.如果条件不满足,那么调用对象的wait方法,被通知后要检查条件 //3.条件满足则执行对应的逻辑 synchronized(lock){ while(!flag){lock.wait();} } //通知方:1.获取对象的锁 2.改变条件 3.通知所有等待在对象上线程 synchronized(lock){ flag = true; lock.notifyAll(); }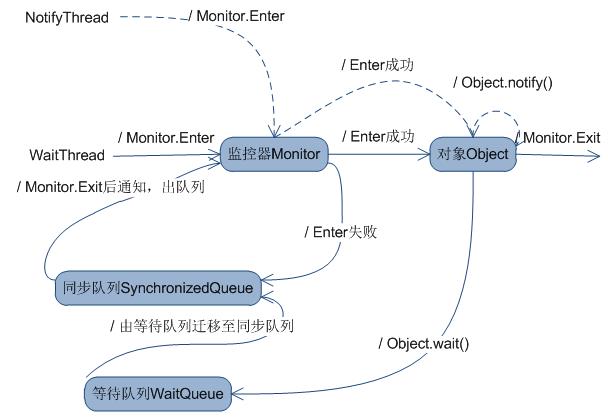
如果线程A执行了Thread.join(),表示当线程A等待的线程终止之后才从thread.join()返回,其还提供了join(long millis)和join(int millis, int nanos)方法,当给点时间内前驱线程未结束则强制返回。ThreadLocal线程变量是以ThreadLocal对象为键,任意对象为值的存储结构。此外,这部分常见的应用实例包括等待超时模式,数据库线程池,基于线程池的简单Web服务器等。
锁
锁是用来控制多个线程访问共享资源的方式,在Lock接口出现前都是通过synchronized来处理线程间同步问题。锁的主要方法包括lock, tryLock, unlock, newCondition获取等待通知组件等方法。其相关的实现包括队列同步器AbstractQueuedSynchronizer、重入锁ReentrantLock、读写锁ReentrantReadWriteLock、LockSupport和Condition接口,这部分的重点讲是可重入锁ReenterLock。
-
重入锁
ReentrantLock表示该锁可以支持一个线程对资源的重复加锁,并支持获取琐时的公平性的选择。默认是非公平锁,其特点是性能要远高于公平锁(严格按照请求时间顺序获取所,FIFO)。ReentrantLock lock = new ReentrantLock(true); lock.lock(); try { // TODO } finally { lock.unlock(); } - 读写锁
ReentrantReadWriteLock同时维护一个读锁和一个写锁,允许多个读线程同时访问共享数据,只会在写线程访问时阻塞,和数据库的锁机制很类似,该方式使得并发性等到很大提升。其除了公平性选择、可重入等特性外,还支持锁降级,遵循获取写锁、获取读锁再释放写锁的次序,写锁能降级为读锁。 - LockSupport提供
park阻塞,unpark唤醒的静态方法。 -
Condition接口:任意的Java对象,都拥有一组监视器方法,包括
wait()、notify()等,这些方法与synchronized关键字配合可以实现等待/通知模式,Condition接口也提供了类似的监视器方法,但功能更加强大。
进阶概念
并发容器和框架
- ConcurrentHashMap VS HashTable:之所以决定好好学学Java并发编程,可以说就是面试时被面试官怼住这个问题。过去只知道ConcurrentHashMap是HashMap的线程安全版本,但其与HashTable的区别却从来没关心过。简答来说,前者通过
Segment对HashEntry进行包装,达到了记录级别的锁粒度,和数据库相关知识类似。HashTable由于只支持[表]级锁,因此性能比较低下。ConcurrentLinkedQueue则是队列的线程安全版本,没有什么特别要说的。 - BlockingQueue阻塞队列是一种支持两个附加操作的队列,一个是支持阻塞插入,即当队列满时,队列会阻塞插入元素的线程,直到队列不满,另一个支持阻塞的移除方法,意思是队列为空时,获取元素的线程会等待队列变为非空。其处理方式包括抛出异常、返回特殊值、一直阻塞和超时退出。Java7提供的阻塞队列包括
ArrayBlockingQueue,LinkedBlockingQueue,DelayQueue等,不是重点。 - Fork/Join框架:Java7中提供的类似Map/Reduce的并行开发框架,Fork可以将任务分解为子任务,而Join则负责汇总结果。其中涉及一个工作窃取
work-stealing算法,可以使得线程可以从其他队列里窃取任务来执行,优点是充分利用线程进行并行计算,减少了线程间的竞争;缺点是在某些情况下存在竞争,比如双端队列里只有一个任务时,该算法会消耗更多的系统资源。
并发工具类
这部分的内容非常重要,之后介绍的一些常见模式可以很好的应用在日常的开发场景中,一定要掌握牢靠。
-
13个原子操作类:比较常见的有
AtomicBoolean和AtomicInteger,AtomicIntegerArray,AutomicReference等,接下来选择一个比较复杂的作为示例。User user = new User("xionger", 30); atomicUserRef.set(user); User updateUser = new User("xiongerda", 32); atomicUserRef.compareAndSet(user, updateUser); System.out.println(atomicUserRef.get().getName()); System.out.println(atomicUserRef.get().getOld()); -
CountDownLatch:类似一个计数器,允许一个或多个线程等待其他线程完成操作,比如主线程需要等待2个子线程完成任务后返回。常见场景,比如我们解析Excel多个Sheet的数据,那么可以由每个线程处理一个,再都完成后再通知系统解析完成。
static CountDownLatch latch = new CountDownLatch(3); public static void main(String[] args) throws InterruptedException { new Thread(new Runnable() { @Override public void run() { latch.countDown(); } }).start(); new Thread(new Runnable() { @Override public void run() { latch.countDown(); } }).start(); latch.await(); } - CyclicBarrier:其让一组线程到达一个屏障,类似跑步的起跑线,直到最后一个线程到达屏障,屏障才会开门,所有被阻塞的线程才能继续执行。以可用于多线程计算数据,最后合并计算数据的场景,例如用一个Excel保存用户所有银行流水,每个Sheet保存一个账户近一年的流水,现在要统计日均流水,那么可以先计算每个Sheet的日均流水,最后汇总。使用上和
CountDownLatch有些相似,不过其特点是可以使用reset方法重置,并通过isBroken()判断线程是否中断。 -
Semaphore信号量用于控制同时访问特定资源的线程数量,常用与流量控制,比如数据库连接的控制,有50个线程需要使用15数据库连接。
private static ExecutorService executorService = Executors.newFixedThreadPool(50); private static Semaphore sema = new Semaphore(15); public static void main(String[] args) { for (int i = 0; i < 50; i++) { executorService.execute(new Runnable() { @Override public void run() { try { sema.acquire(); System.out.println("save data"); sema.release(); } catch (InterruptedException e) { e.printStackTrace(); } } }); } executorService.shutdown(); } -
Exchanger交换者可用于线程间数据交换,它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。Exchange可以用于遗传算法和校对工作等场景,比如需要将纸质流水录入到系统,为了避免错位,使用AB岗两人进行录入,录入到Excel后,系统需要加载这两个Excel并进行校对。
private static final Exchanger<String> exchanger = new Exchanger<>(); private static ExecutorService threadPool = Executors.newFixedThreadPool(2); public static void main(String[] args) { threadPool.execute(new Runnable() { @Override public void run() { String a = "银行流水A"; try { exchanger.exchange(a); } catch (InterruptedException e) { e.printStackTrace(); } } }); threadPool.execute(new Runnable() { @Override public void run() { String b = "银行流水B"; try { String a = exchanger.exchange(b); System.out.println("a和b是否数据一致:" + a.equals(b) + ",a录入的是: " + a + ",b录入的是" + b); } catch (InterruptedException e) { e.printStackTrace(); } } }); }
Executor框架
-
线程池
在介绍Executor框架前,先介绍线程池相关的原理,其是并发编程中最为重要的部分,合理的使用线程池可以降低系统消耗、提高响应速度、提高线程的可管理性,接下来介绍线程池的基础处理流程。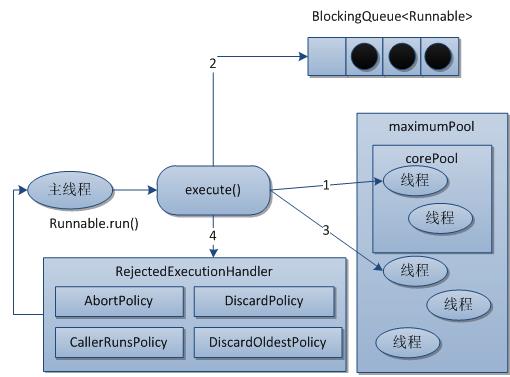
1.如果当前运行的线程少于corePoolSize直接创建新线程来执行任务,需要获取全局锁。
2.如果运行的线程等于或多余corePoolSize则将任务加入BlockingQueue。
3.如果由于队列已满,无法将任务加到BlockingQueue,则创建新的线程来处任务,需要获取全局锁。
4.如果创建新线程将操作maximumPoolSize,任务将被拒绝,并调用RejectedExecutionHandler.rejectedExecution()方法。
ThreadPoolExecutor采用上述步骤,保证了执行execute()时,尽可能的避免了获取全局锁,大部分的可能都会执行步骤2,而无需获取全局锁。
在引入Executor框架前,Java线程既是工作单元,也是执行机制。而在Executor框架中,工作单元和执行机制被分离开来,前者包括Runnable和Callable,而执行机制由Executor框架提供。该框架是一个两级的调度模型,在上层,通过调度器Executor将多个任务映射到固定数量的线程;在底层,操作系统内核将这些线程再映射到处理器上。而我们的应用程序只需通过E该框架控制上层的调度即可。
Tip:
在合理配置线程池时,需要根据具体场景给出对应的解决方案,总体来说,推荐使用有界队列,便于控制。
CPU密集型:配置尽可能少的线程,如cpu数量+1,可以通过Runtime.getRuntime().availableProcessors()获取CPU个数
IO密集型:配置尽可能多的线程,如2*cpu数量,常见场景,等待数据库或服务接口的返回。
优先级:可以通过PriorityBlockingQueue来处理
监控:可以通过taskCount,completedTaskCount,getActiveSize等函数来监控线程池的运行。 - Executor框架结构主要由三部分组成
a.任务,包括任务实现的接口Runnable和Callable
b.任务的执行,包括任务执行机制的核心接口Executor和其子类ExecutorService,相关的实现类包括ThreadPoolExecutor和ScheduledThreadPoolExecutor。
c.异步计算的结果,包括Future和其实现FutureTask。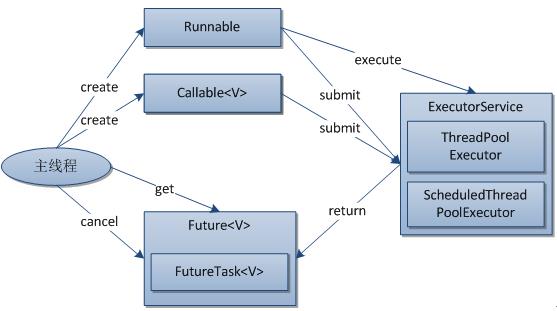
- ThreadPoolExecutor:框架的核心类,由
corePool,maximumPool,BlockingQueue,RejectedExecutionHandler4部分组成,可以由工具类Executors创建。具体老说,工具类可以创建FixedThreadPool固定线程数(最推荐)、SingleThreadExecutor、CachedThreadPool三种类型的ThreadPoolExecutor。 - ScheduledThreadPoolExecutor:比基础的
Timer对象更加全面,其通过DelayQueue来执行周期性或定时的任务。 -
FutureTask基于
AbstractQueuedSynchronizer(AQS),之前介绍的ReentrantLock、CountDownLatch等其实都是基于AQS来实现的。AQS是一个同步框架,提供通用机制来原子性的管理同步状态、阻塞&唤醒线程、维护被阻塞的线程队列。每个基于AQS的实现都会包含两类操作,acquire用于阻塞调用线程,对应futureTask.get(),知道AQS状态允许这个线程才能继续执行;另一个为release,对应futureTask.cancel()&run(),该操作改变AQS状态,改变后的状态允许一个或多个阻塞线程解除阻塞。public static void main(String[] args) throws InterruptedException, ExecutionException { ExecutorService executor = Executors.newSingleThreadExecutor(); Future<BigDecimal> result = executor.submit(new Callable<BigDecimal>() { @Override public BigDecimal call() throws Exception { return getSalaryByService(); } }); System.out.println(result.get()); } -
生产者消费者模式:该模式可以解决大部分的并发问题,其通过阻塞队列,平衡生产线程和消费线程的工作能力来提高程序整体处理数据的速度。比如经常会邮件来分享技术知识,就可以通过通过Job到邮箱中获取到文章并放入阻塞队列,之后消费者去获取数据并插入到类似confluence的文档管理工具中,接下来展示一个单个生产者,多个消费者的应用场景实现。
Tip:
线上问题定位:Linux中可以通过top命令查看进程的情况,之后可以使用交互命令1查看CPU性能,H查看每个线程的性能信息。
性能测试:比如使用Jmeter来做压测,可以通过netstat -nat | grep 3306 -c来查看数据的压力情况。
以上是关于Java并发编程深入学习的主要内容,如果未能解决你的问题,请参考以下文章