SpringBatch Sample (固定长格式文件读写)
Posted long77
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SpringBatch Sample (固定长格式文件读写)相关的知识,希望对你有一定的参考价值。
前篇关于Spring Batch的文章,讲述了Spring Batch 对XML文件的读写操作。 本文将通过一个完整的实例,与大家一起讨论运用Spring Batch对固定长格式文件的读写操作。实例延续前面的例子,读取一个含有四个字段的TXT文件(ID,Name,Age,Score),对读取的字段做简单的处理,然后输出到另外一个TXT文件中。
工程结构如下图:
applicationContext.xml和log4j.xml前文已经叙述过,在此不做赘述。
本文核心配置文件batch.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<bean:beans xmlns="http://www.springframework.org/schema/batch"
xmlns:bean="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:aop="http://www.springframework.org/schema/aop" xmlns:context="http://www.springframework.org/schema/context"
xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-3.0.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd
http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.1.xsd
http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util.xsd">
<bean:import resource="applicationContext.xml" />
<!-- Job信息的配置 -->
<job id="fixedLengthJob">
<step id="fixedLengthStep">
<tasklet>
<chunk reader="fixedLengthReader" writer="fixedLengthWriter"
processor="fixedLengthProcessor" commit-interval="10">
</chunk>
</tasklet>
</step>
</job>
<!-- 固定长文件的读信息的配置 -->
<bean:bean id="fixedLengthReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step">
<bean:property name="resource"
value="file:#{jobParameters[\'inputFilePath\']}" />
<bean:property name="lineMapper">
<bean:bean
class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<bean:property name="lineTokenizer" ref="lineTokenizer" />
<bean:property name="fieldSetMapper">
<bean:bean
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper">
<bean:property name="prototypeBeanName" value="studentBean"/>
</bean:bean>
</bean:property>
</bean:bean>
</bean:property>
</bean:bean>
<bean:bean id="studentBean"
class="com.wanggc.springbatch.sample.fixedlength.StudentPojo" scope="prototype" />
<bean:bean id="lineTokenizer"
class="org.springframework.batch.item.file.transform.FixedLengthTokenizer">
<bean:property name="columns" value="1-6,7-15,16-18,19-" />
<bean:property name="names" value="ID,name,age,score" />
</bean:bean>
<!-- 固定长格式文件的写 -->
<bean:bean id="fixedLengthWriter"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step">
<bean:property name="resource"
value="file:#{jobParameters[\'outputFilePath\']}" />
<bean:property name="lineAggregator">
<bean:bean
class="org.springframework.batch.item.file.transform.FormatterLineAggregator">
<bean:property name="fieldExtractor">
<bean:bean
class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor">
<bean:property name="names" value="ID,name,age,score" />
</bean:bean>
</bean:property>
<bean:property name="format" value="%-9s%-20s%3d%-2.0f" />
</bean:bean>
</bean:property>
</bean:bean>
</bean:beans>
22-30行配置了Job的基本信息。此Job包含一个Step,Step中包含了基本的读(fixedLengthReader),处理(fixedLengthProcessor),写(fixedLengthWriter)以及commit件数(commit-interval)。
33-49行配置了读处理的详细信息。固定长格式和csv格式都属于flat文件格式,所以读取固定长格式文件也是需要使用Spring Batch提供的核心类FlatFileItemReader。对此类的配置在《Spring Batch 之 Sample(CSV文件操作)(四) 》中已经做过详细说明。但要注意lineTokenizer的配置,在读取CSV文件的时候,使用的是DelimitedLineTokenizer类,但是读取固定长格式的文件,需要使用FixedLengthTokenizer,如52-56行所示。其columns是如何分割一条记录信息,也就是说指定哪几列属于一个项目的信息(注意:列数的总长度与文件记录长度不一样的时候,会报错。注意限定范围)。属性names指定每个项目的名字。其名字与44行prototypeBeanName属性指定的Pojo属性名相同。
59-76行配置了写处理的详细信息。写固定长格式的文件,与写CSV格式的文件一样,也是使用Spring Batch提供的核心类FlatFileItemWriter。在此也不再赘述。但要注意lineAggregator属性使用的是FormatterLineAggregator类,此类的format属性可以指定每个项目所占的长度和格式。
batch.xml文件配置了对固定长文件的和写。在读之后,写之前的处理,是通过自定的FixedLengthProcessor 类处理的。详细代码如下:

package com.wanggc.springbatch.sample.fixedlength;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.stereotype.Component;
/**
* 业务处理类。
*
* @author Wanggc
*/
@Component("fixedLengthProcessor")
public class FixedLengthProcessor implements
ItemProcessor<StudentPojo, StudentPojo> {
/**
* 对取到的数据进行简单的处理。
*
* @param student
* 处理前的数据。
* @return 处理后的数据。
* @exception Exception
* 处理是发生的任何异常。
*/
public StudentPojo process(StudentPojo student) throws Exception {
/* 合并ID和名字 */
student.setName(student.getID() + "--" + student.getName());
/* 年龄加2 */
student.setAge(student.getAge() + 2);
/* 分数加10 */
student.setScore(student.getScore() + 10);
/* 将处理后的结果传递给writer */
return student;
}
}
至此,对固定长格式文件的读、处理、写操作已经介绍完毕。下面是一些辅助文件的信息。
Pojo类StudentPojo的详细代码如下:
package com.wanggc.springbatch.sample.fixedlength;
/** Pojo类_Student */
public class StudentPojo {
/** ID */
private String ID = "";
/** 名字 */
private String name = "";
/** 年龄 */
private int age = 0;
/** 分数 */
private float score = 0;
/* 为节省篇幅,getter 和 setter 已经删除 */
}
Job启动类Launch的详细代码如下:
package com.wanggc.springbatch.sample.fixedlength;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Launch {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext(
"batch.xml");
JobLauncher launcher = (JobLauncher) context.getBean("jobLauncher");
Job job = (Job) context.getBean("fixedLengthJob");
try {
// JOB实行
JobExecution result = launcher.run(
job,
new JobParametersBuilder()
.addString("inputFilePath",
"C:\\\\testData\\\\fixedLengthInputFile.txt")
.addString("outputFilePath",
"C:\\\\testData\\\\fixedLengthOutputFile.txt")
.toJobParameters());
// 运行结果输出
System.out.println(result.toString());
} catch (Exception e) {
e.printStackTrace();
}
}
}
input文件内容如下:
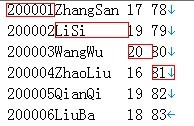
处理结果如下:

下次,将和大家一起讨论关于Spring Batch 对复合格式文件的读写问题。
如果您对本文有意见或者建议,欢迎留言,哪怕是拍砖(^_^)!
欢迎转载,请注明出处!
感谢您的阅读,请关注后续博客!
以上是关于SpringBatch Sample (固定长格式文件读写)的主要内容,如果未能解决你的问题,请参考以下文章