Java IO
Posted 翎野
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java IO相关的知识,希望对你有一定的参考价值。
IO框架图:
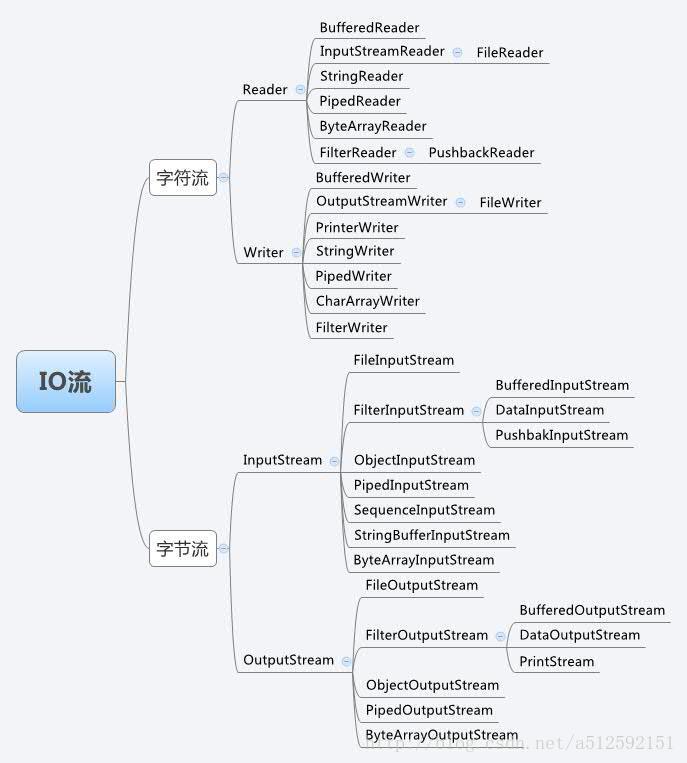
Java 的 I/O 操作类在包 java.io 下,大概有将近 80 个类,但是这些类大概可以分成四组,分别是:
基于字节操作的 I/O 接口:InputStream 和 OutputStream
基于字符操作的 I/O 接口:Writer 和 Reader
基于磁盘操作的 I/O 接口:File
基于网络操作的 I/O 接口:Socket
前两组主要是根据传输数据的数据格式,后两组主要是根据传输数据的方式,虽然 Socket 类并不在 java.io 包下,但是我仍然把它们划分在一起,因为我个人认为 I/O 的核心问题要么是数据格式影响 I/O 操作,要么是传输方式影响 I/O 操作,也就是将什么样的数据写到什么地方的问题,I/O 只是人与机器或者机器与机器交互的手段,除了在它们能够完成这个交互功能外,我们关注的就是如何提高它的运行效率了,而数据格式和传输方式是影响效率最关键的因素了。我们后面的分析也是基于这两个因素来展开的。
不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符,所以 I/O 操作的都是字节而不是字符,但是为啥有操作字符的 I/O 接口呢?这是因为我们的程序中通常操作的数据都是以字符形式,为了操作方便当然要提供一个直接写字符的 I/O 接口,如此而已。我们知道字符到字节必须要经过编码转换,而这个编码又非常耗时,而且还会经常出现乱码问题,所以 I/O 的编码问题经常是让人头疼的问题。
1.流的概念
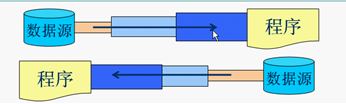
流(stream)的概念源于UNIX中管道(pipe)的概念。在UNIX中,管道是一条不间断的字节流,用来实现程序或进程间的通信,或读写外围设备、外部文件等。
一个流,必有源端和目的端,它们可以是计算机内存的某些区域,也可以是磁盘文件,甚至可以是Internet上的某个URL。
流的方向是重要的,根据流的方向,流可分为两类:输入流和输出流。用户可以从输入流中读取信息,但不能写它。相反,对输出流,只能往输入流写,而不能读它。
实际上,流的源端和目的端可简单地看成是字节的生产者和消费者,对输入流,可不必关心它的源端是什么,只要简单地从流中读数据,而对输出流,也可不知道它的目的端,只是简单地往流中写数据。
2.流的分类
字节流:一次读入或读出是8位二进制。
字符流:一次读入或读出是16位二进制。
字节流和字符流的原理是相同的,只不过处理的单位不同而已。后缀是Stream是字节流,而后缀是Reader,Writer是字符流。
节点流:直接与数据源相连,读入或读出。

直接使用节点流,读写不方便,为了更快的读写文件,才有了处理流。
处理流:与节点流一块使用,在节点流的基础上,再套接一层,套接在节点流上的就是处理流。
Jdk提供的流继承了四大类:
InputStream(字节输入流),OutputStream(字节输出流): 主要用来表示 二进制文件(图片、视频、音频、文本文件)
Reader(字符输入流),Writer(字符输出流):表示文本文件(Windows 自带的记事本软件打开能看懂内容的文件)
Java的常用输入、输出流
java.io包中的stream类根据它们操作对象的类型是字符还是字节可分为两大类: 字符流和字节流。
字节流 字符流
输入流 InputStream Reader
输出流 OutputStream Writer
实例1:向文件中写入数据


package cn.czbk.no9; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; public class FileOutTest { public static void main(String[] args) throws Exception { /** * 使用字节输入流的步骤 * 1.打开文件(创建字节输出流对象) * 2.写出数据 * 3.关闭文件(释放资源) */ FileOutputStream fos=new FileOutputStream("src/test.txt", true); for(int i=0;i<9;i++){ fos.write(("this is for test about fileoutstream i= "+i+"\\r\\n").getBytes()); } fos.close(); } }

实例2:从文件中读取数据
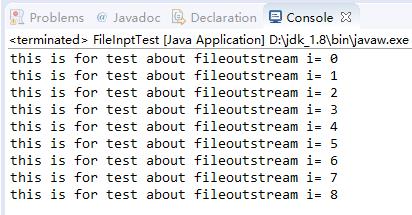
package cn.czbk.no9; import java.io.FileInputStream; import java.io.FileNotFoundException; public class FileInptTest { public static void main(String[] args) throws Exception { /** * 使用字节输入流的步骤 * 1.打开文件(创建字节输入流对象) * 2.读取数据 * 2.1建立一个byte数组 * 2.2将文件中的内容读取到byte数组中来,然后对其进行处理 * 3.关闭文件(释放资源) */ FileInputStream fis=new FileInputStream("src/test.txt"); byte[] b=new byte[1000]; int len=0; while((len=fis.read(b))!=-1){ System.out.println(new String(b,0,len)); } fis.close(); } }
实例3:拷贝文件
package cn.czbk.no9; import java.io.FileInputStream; import java.io.FileOutputStream; public class FileCopy { public static void main(String[] args) throws Exception{ /** * 拷贝:先读在写 */ /** FileInputStream fis=new FileInputStream("src/test.txt"); byte[] buffer=new byte[10000]; int length; //read方法一次读完但是如果内容字节数大于定义的数组的长度的话就分多次读 while((length=fis.read(buffer))!=-1){ System.out.println(length); System.out.println("读取成功准备写入新文件。。。"); } //在最后一次循环的时候读完文件后返回的length是-1所以你在取得时候只能按照buffer的长度去取 for(int i=0;i<length;i++){ System.out.println(length); System.out.println(buffer[i]); } fis.close(); FileOutputStream fos=new FileOutputStream("copyfrombu.txt", true); fos.write(buffer, 0, buffer.length); System.out.println("写入成功"); fos.close(); */ /** * 优化 */ FileInputStream fis=new FileInputStream("src/bu.txt"); FileOutputStream fos=new FileOutputStream("bububu.txt",true); byte[] buffer=new byte[1000]; int k; while((k=fis.read())!=-1){ fos.write(k); } fis.close(); fos.close(); } }

实例4:字节缓冲输入输出流(处理流、过滤流)
package cn.czbk.no9; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStream; public class BufferOutPutTest { public static void main(String[] args) throws Exception{ BufferedOutputStream bos=new BufferedOutputStream(new FileOutputStream("src/bufferout.txt")); for(int i=0;i<5;i++){ bos.write(("abcd"+i+"\\r\\n").getBytes()); } bos.close(); BufferedInputStream bis=new BufferedInputStream(new FileInputStream("src/bufferout.txt")); byte[] buf=new byte[1000]; int length=0; while((length=bis.read(buf))!=-1){ System.out.println(new String(buf, 0, length)); } bis.close(); } }

实例5:字符串编码问题
解码: 把看不懂的数据解析成 能看懂的数据
例如:字节数组转换成 String 的操作
API: public String(byte[] bytes) 使用平台的默认字符集解码指定的 byte 数组
默认字符集: GBK
编码: 把能看懂的转换成看不懂的
例如:String 转换成字节数组的操作
API: public byte[] getBytes()使用平台的默认字符集将此 String 编码为 byte
序列,并将结果存储到一个新的 byte 数组中。
默认字符集: GBK
public byte[] getBytes(Charset charset)使用给定的 charset 将此 String 编
码到 byte 序列,并将结果存储到新的 byte 数组。
注意:我们这里可能会抛出一个 UnsupportedEncodingException 不支持的编码异常
我们常见的码表:
* Unicode:用两个字节表示一个数据 java中就是使用的Unicode编码
* GB2312:简体中文, 一个数据用两个字节(16位)表示国标码
* GBK编码:在GB2312的基础之上对于中文数据进行了升级
* GB18030:简体中文,是在GBK的基础之上又做了升级
* UTF-8:表示Unicode数据的话需要使用1-6个字节来表示,一般情况1-3个字节即可以表示
* 表示一个汉字用3个字节来表示
* 能用1一个字节表示的数据就用1个字节来表示
* 能用2个字节来表示的数据就用2个字节来表示
package cn.czbk.no9; import java.io.UnsupportedEncodingException; import java.util.Arrays; public class StringEncoding { public static void main(String[] args) throws Exception { /** * Unicode:用两个字节表示一个数据 java中就是使用的Unicode编码 * GB2312:简体中文, 一个数据用两个字节(16位)表示国标码 * GBK编码:在GB2312的基础之上对于中文数据进行了升级 * GB18030:简体中文,是在GBK的基础之上又做了升级 * UTF-8:表示Unicode数据的话需要使用1-6个字节来表示,一般情况1-3个字节即可以表示 * 表示一个汉字用3个字节来表示 * 能用1一个字节表示的数据就用1个字节来表示 * 能用2个字节来表示的数据就用2个字节来表示 */ String s="李翎野"; //将字符串转化为字节数组的形式 //java中是Unicode编码 byte[] arr=s.getBytes(); //转码:转码都是已字节为基础进行转码的而不是字符串 //Unicode转为GBK byte[] gbkarr=s.getBytes("GBK"); //Unicode转为UTF-8 byte[] u8arr=s.getBytes("UTF-8"); /** * System.out.println("arr"+arr); * 不可以这样打印,这样打出来的是数组的引用,而不是对应的字节码 */ System.out.println(Arrays.toString(arr)); System.out.println(Arrays.toString(gbkarr)); System.out.println(Arrays.toString(u8arr)); String s1=new String(arr); String s2=new String(gbkarr, "GBK"); String s3=new String(u8arr,"UTF-8"); System.out.println(s1); System.out.println(s2); System.out.println(s3); } }
实例6:转换流
问题:为什么需要转换流?
因为,字节流处理汉字 不方便, 所以出现了 转换流。转换流 = 字节流 + 编码表
常见的转换流(API 介绍):
OutputStreamWriter: 编码 输出流
InputStreamReader: 解码 输入流
package cn.czbk.no9; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStream; import java.io.OutputStreamWriter; public class FileOutEncoding { public static void main(String[] args) throws Exception{ //字符流 OutputStreamWriter osw=new OutputStreamWriter(new FileOutputStream("src/unicodep.txt")); OutputStreamWriter gbk=new OutputStreamWriter(new FileOutputStream("src/gbkp.txt"), "GBK"); OutputStreamWriter u8=new OutputStreamWriter(new FileOutputStream("src/u8p.txt"), "UTF-8"); //字符流直接在流里面写汉字就可以了不需要转化为byte osw.write("中国"); gbk.write("中国"); /** * 用文档打开会出现乱码这是因为 * 当我们向外输出时,用 UTF-8 读进行了编码,而我们的操作系统显示 txt 文档是用 GBK * 解码的,由于编码和解码码表不一致,所以就会出现乱码。 */ u8.write("中国"); osw.close(); gbk.close(); u8.close(); } }
实例7:字符缓冲流
package cn.czbk.no9; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; import java.io.FileReader; import java.io.FileWriter; public class BufferWriter { public static void main(String[] args) throws Exception{ BufferedWriter bw=new BufferedWriter(new FileWriter("src/gbkp.txt")); bw.write("深圳今天下了很多雨"); bw.close(); BufferedReader br=new BufferedReader(new FileReader("src/gbkp.txt")); int ch=0; while((ch=br.read())!=-1){ System.out.print((char)ch); } br.close(); } }
package cn.czbk.no9; import java.io.BufferedReader; import java.io.FileReader; public class BufferReaderTest { public static void main(String[] args) throws Exception{ BufferedReader br=new BufferedReader(new FileReader("src/gbkp.txt")); //直接读字符 int a=0; while((a=br.read())!=-1){ System.out.println((char)a); } br.close(); } }

实例8:Properties集合
Java中有个比较重要的的类Properties(java.util.Properties),是代表一个持久的一套详细属性,
实现集合与 IO 进行交互
特点:
1: 它是一个 Map 集合, 是 Hashtable 的子类
2: 键和值 都是 String 类型
属性可以被保存到一个流或从流中加载的类。以下是关于属性的要点:
-
属性列表中每个键及其对应值是一个字符串。
-
一个属性列表可包含另一个属性列表作为它的“默认”,第二个属性可在列表中搜索,如果没有在原有的属性列表中找到的属性键。
-
这个类是线程安全的;多个线程可以共享一个Properties对象,而不需要外部同步
package cn.czbk.no9; import java.util.Properties; import java.util.Set; public class PropertiesTest { public static void main(String[] args) { Properties p=new Properties(); p.setProperty("1", "小花"); p.setProperty("2", "小明"); p.setProperty("3", "小王"); Set<String> set=p.stringPropertyNames(); for(String key:set){ String va=p.getProperty(key); System.out.println(key+" "+va); } } }
package cn.czbk.no9; import java.io.FileReader; import java.io.FileWriter; import java.util.Properties; import java.util.Set; public class PropertiesFileTest { private void storeFile(Properties p) throws Exception{ p.setProperty("1", "腰疼"); p.setProperty("2", "脖子疼"); p.setProperty("3", "眼睛疼"); p.store(new FileWriter("src/pro.txt"), "This is Test"); } private void loadFile() throws Exception{ Properties p=new Properties(); p.load(new FileReader("src/pro.txt")); Set<String> ss=p.stringPropertyNames(); for(String key:ss){ String va=p.getProperty(key); System.out.println(va+key); } } public static void main(String[] args) throws Exception{ Properties p=new Properties(); PropertiesFileTest pft=new PropertiesFileTest(); pft.storeFile(p); pft.loadFile(); } }

以上是关于Java IO的主要内容,如果未能解决你的问题,请参考以下文章
csharp C#代码片段 - 使类成为Singleton模式。 (C#4.0+)https://heiswayi.github.io/2016/simple-singleton-pattern-us
Android android.view.InflateException Binary XML 文件第 16 行:膨胀类片段时出错