大数据Flink进阶:Apache Flink是什么
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Flink进阶:Apache Flink是什么相关的知识,希望对你有一定的参考价值。

文章目录
Apache Flink是什么
在当前数据量激增的时代,各种业务场景都有大量的业务数据产生,对于这些不断产生的数据应该如何进行有效的处理,成为当下大多数公司所面临的问题。目前比较流行的大数据处理引擎Apache Spark,基本上已经取代了MapReduce成为当前大数据处理的标准。随着数据的不断增长,人们逐渐意识到对实时数据处理的重要性。相对传统数据处理模式,流式数据处理有着更高的处理效率和成本控制要求。Apache Spark 不仅支持批数据计算还支持流式数据计算,但是SparkStreaming在底层架构、数据抽象等方面采用了批量计算的概念,其流计算的本质还是批(微批)计算。
近年来Apache Flink计算框架发展迅速,Flink以流处理为基础,对批数据也有很好的支持,尤其是在流计算领域相比其他大数据分布式计算引擎有着明显优势,能够针对流式数据同时支持高吞吐、低延迟、高性能分布式处理 ,Flink在未来发展上有着令人期待的前景。
一、Flink的定义
Apache Flink 是一个框架和分布式处理引擎,用于在 无边界 和 有边界 数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
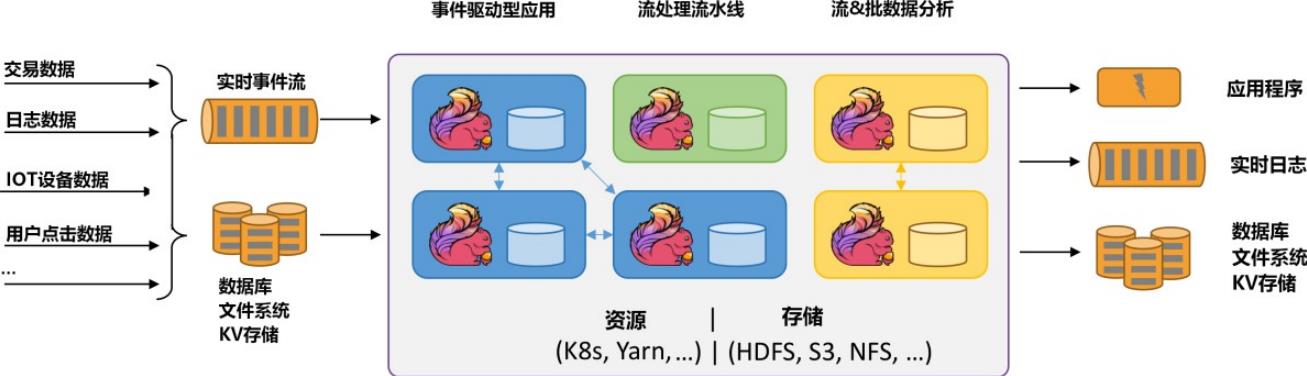
Flink可以处理批数据也可以处理流数据,本质上,流处理是Flink中的基本操作,流数据即无边界数据流,在Flink中处理所有事件都可看成流事件,批数据可以看成是一种特殊的流数据,即有边界数据流,这与Spark计算框架截然相反,在Spark中批处理是最基本操作,流事件可以划分为一小批一小批数据进行微批处理,来达到实时效果,这也是两者区别之一。
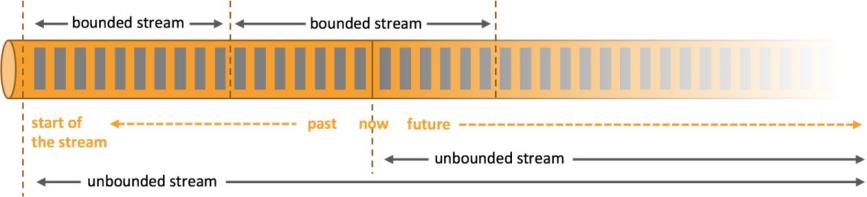
- 无界流
有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
- 有界流
有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
Apache Flink 擅长处理无界和有界数据集,精确的时间控制和状态化使得 Flink 的运行时(runtime) 能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
Flink官网:https://flink.apache.org
二、Flink前身Stratosphere
Flink最早是德国一些大学中的研究项目,并且早期项目名称也不是Flink,在2010~2014年间,由德国柏林工业大学、德国柏林洪堡大学和德国哈索·普拉特纳研究所联合发起名为"Stratosphere: Information Management on the Cloud"研究项目,该项目就是Flink的前身:Stratosphere项目。该项目创建初衷就是构建一个一数据库概念为基础、以大规模并行处理架构为支撑、以MapReduce计算模型为逻辑框架的分布式数据计算引擎,在此构想之上还引入了流处理,为后来的Flink发展打下良好基础。
2014年4月,Stratosphere代码被贡献给Apache软件基金会,成为Apache基金会孵化器项目,项目孵化期间,项目Stratosphere改名为Flink。Flink在德语中意为"敏捷、快速",用来体现流式 数据处理器速度快 和 灵活性强 等特点,同时使用棕红色松鼠图案作为Flink项目的Logo,也是为了突出松鼠灵活快速的特点,由此,Flink正式进入社区开发者的视线。

Flink自从加入Apache后发展十分迅猛,自2014年8月发布0.6版本后,Flink仅用了3个月左右的时间,在2014年11月发布了0.7版本,该版本包含Flink目前为止最重要的 Flink Streaming 特性, 2014年底,Flink顺利从孵化器"毕业"成为Apache顶级项目。随着Flink技术成为Apache顶级项目, Flink受到社区越来越多的关注,Flink逐步增加了很多核心的功能,例如:一致性语义、事件时间和Table API等,其功能和稳定性也不断得到完善。
早期Stratosphere项目的核心成员曾共同创办一家名叫"Data Artisans"的公司,其主要的任务就是致力于Flink技术的发展和商业化,2019年阿里巴巴收购了Data Artisans公司,并将其开发的分支Blink开源,越来越多的公司开始将Flink应用到他们真实的生产环境中,并在技术和商业上共同推动Flink的发展。
Flink逐步被广泛使用不仅仅是因为 Flink支持高吞吐、低延迟和 exactly-once 语义的实时计算,同时Flink还提供 基于流式计算引擎处理批量数据的计算能力 ,在计算框架角度真正实现了批流统一处理。目前,国内很多公司都已经大规模使用Flink作为分布式计算场景的解决方案,如:阿里巴巴、华为、小米等,其中,阿里巴巴已经基于Flink实时计算平台实现了对淘宝、天猫、支付宝等数据业务支持。
三、Flink发展时间线及重大变更
Flink发展非常迅速,目前官网Flink最新版本是1.16版本,下面列举Flink发展过程中重要时间和重要版本发布时间点以及Flink各个版本推出的新特性以帮助大家更好了解Flink。
- 2010~2014:德国柏林工业大学研究性项目Stratosphere,目标是建立下一代大数据分析引擎;
- 2014-04-16:Stratosphere成为Apache 孵化项目,从Stratosphere0.6开始,正式更名为Flink,由Java语言编写;
- 2014-08-26:Flink 0.6发布;
- 2014-11-04:Flink 0.7.0发布,推出最重要的特性:Streaming API;
- 2016-03-08:Flink 1.0.0,流处理基础功能完善,支持Scala;
- 2016-08-08:Flink 1.1.0 版本发布,流处理基础功能完善;
- 2017-02-06:Flink 1.2.0 版本发布,流处理基础功能完善;
- 2017-06-01:Flink 1.3.0 版本发布,流处理基础功能完善;
- 2017-11-29:Flink 1.4.0 版本发布,流处理基础功能完善;
- 2018-05-25:Flink 1.5.0 版本发布,流处理基础功能完善;
- 2018-08-08:Flink 1.6.0 版本发布,流处理基础功能完善,状态TTL支持;增强SQL和Table API;
- 2018-11-30:Flink 1.7.0 版本发布,Scala2.12支持;支持S3文件处理;支持Kafka 2.0 connector;
- 2019-01:阿里巴巴以9000万欧元价格收购Data Artisans公司,并开发内部版本Blink;
- 2019-04-09:Flink 1.8.0 版本发布,支持TTL清除旧状态;不再支持hadoop二进制文件;
- 2019年8月阿里巴巴开源Blink。
- 2019-08-22:Flink 1.9.0 版本发布,主要特性如下:
合并阿里内部Blink;
重构Flink WebUI;
Hive集成;
Python Table API支持;
- 2020-02-11:Flink 1.10.0 版本发布【重要版本】,主要特性如下:
整合Blink全部完成;
集 成 K8S;
PyFlink优化;
内存管理配置优化;
- 2020-07-06:Flink 1.11.0 版本发布【重要版本】,主要特性如下:
从Flink1.11开始,Blink planner是Table API/SQL中的默认设置,仍支持旧的Flink planner;
Flink CDC支持;
支持Hadoop3.x版本,不提供任何更新的flink-shaded-hadoop-x jars,用户需要通过HADOOP_CLASSPATH环境变量(推荐)或 lib/ folder 提供 Hadoop 依赖项。
- 2020-12-08:Flink 1.12.0 版本发布【重要版本】,主要特性如下:
DataStream API 上添加了高效的批执行模式的支持,批处理和流处理实现真正统一的运行时的一个重要里程碑;
实现了基于Kubernetes的高可用性(HA)方案,作为生产环境中,ZooKeeper方案之外的另外一种选择;
扩展了 Kafka SQL connector,使其可以在 upsert 模式下工作,并且支持在 SQL DDL 中处理 connector 的 metadata;
PyFlink 中添加了对于 DataStream API 的支持;
支持FlinkSink,不建议再使用StreamingFileSink;
- 2021-04-30:Flink 1.13.0 版本发布,主要特性如下:
SQL和表接口改进;
改进DataStream API和Table API/SQL之间的互操转换;
Hive查询语法兼容性;
PyFlink的改进;
- 2021-09-29:Flink1.14.0 版本发布
改进批和流的状态管理机制;
优化checkpoint机制;
不再支持Flink on Mesos资源调度;
开始支持资源细粒度管理;
- 2022-05-05:Flink1.15.0 版本发布,主要特性如下:
Per-job任务提交被弃用,未来版本会丢弃,改用Application Mode。
Flink依赖包不使用Scala的话可以排除Scala依赖项,依赖包不再包含后缀;
持续改进Checkpoint和两阶段提交优化;
对于Table / SQL用户,新的模块flink-table-planner-loader取代了flink-Table- planner_xx,并且避免了Scala后缀的需要;
添加对opting-out Scala的支持,DataSet/DataStream api独立于Scala,不再传递地依赖于它。
flink-table-runtime不再有Scala后缀了;
支持JDK11,后续对JDK8的支持将会移除;
不再支持Scala2.11,支持Scala2.12;
Table API & SQL优化,移除FlinkSQL upsert into支持; 支持最低的Hadoop版本为2.8.5;
不再支持zookeeper3.4 HA ,zookeeper HA 版本需要升级到3.5/3.6;
Kafka Connector默认使用Kafka客户端2.8.1;
- 2022-10-28:Flink1.16.0 版本发布,主要特性如下:
弃用jobmanager.sh脚本中的host/web-ui-port参数,支持动态配置;
删除字符串表达式DSL;
不再支持Hive1.x、2.1.x、2.2.x版本;
弃用StreamingFileSink,建议使用FileSink。
优化checkpoint机制;
PyFlink1.16将python3.6版本标记为弃用,PyFlink1.16版本将成为使用python3.6版本最后一个版本;
Hadoop支持3.3.2版本;
Kafka支持3.1.1版本;
Hive支持2.3.9版本;
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于大数据Flink进阶:Apache Flink是什么的主要内容,如果未能解决你的问题,请参考以下文章