正则表达式高阶技巧之环视(使用python实现)
Posted 温柔且上进c
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式高阶技巧之环视(使用python实现)相关的知识,希望对你有一定的参考价值。
正则之环视
介绍
正则单词边界匹配(\\b)就是类似于这样的:一边必须是单词字符,另一边不能是单词字符。从环视的角度考虑,它是这样进行判断的:在某个位置向左/右看,必须出现或不能出现某类字符
用法
- 比如:我们用
<[^/>][^>]*>来匹配html中的open tag,它保证了<之后不会出现/,这样就排除了<\\img>这类的close tag,但是它可以匹配到self-closing tag,比如<br/> - 如果将上述的表达式换成
<[^/>][^>]*[^/]>,又会出现新的问题,就是在 < 与 > 之间的[^/>][^>]*[^/],能匹配的文本至少包含2个字符。这样是无法匹配<u>这类的标签 - 对于上面的问题我们可以使用
<[^/>]([^>]*[^/])?>这个表达式来解决无法匹配<u>这类的标签问题
环视的角度理解
- 对于上述匹配HTML中的open tag标签这个问题,从环视角度考虑:在开始位置先匹配
<,同时要求在这个<之后的字符不能是/;然后匹配中间的文本,除非在标签的属性中出现(也就是"" ‘’ 引号字符串中),否则不能出现>,且长度必须大于1(<>不是合法的tag);最后匹配>,同时要求这个>之前不能是/ - 使用环视的描述是更加准确,且逻辑也更加清晰,可以使用三个子表达式来分别匹配这三个部分。单独来分析,开头的<、中间内容,结尾的>都不难匹配,但必须解决的问题是:在匹配开头时的 < 字符时还必须向后(向右)瞅瞅,确认下一个字符不能是 / ,同时又不能真正的匹配到这个字符,因为 < 与 > 中间的字符是由单独的子表达式进行匹配的;同时,结尾的 > 匹配亦是如此
环视结构
- 针对上述这种要求,正则表达式专门提供了环视(look-around)用来“停在原地,四处张望”,环视就跟上述的单词边界是类似的,**在它的旁边的字符必须满足某种条件,而且本身不能匹配任何字符串
表达式
- 比如正则表达式中的
<(?!/),其中的(?!/)是一个环视结构,(?!..)是这个结构的标识,/才是真正的表达式,整个结构标识的意思是“在当前位置的之后(右侧),不允许出现/能匹配的字符”。 - 这样看起来是与表达式
<[^\\]类似,其实两个是大不相同的:如果<[^\\]能匹配成功的话,正则表达式真正匹配到的文本是 < 与 后面不是 \\ 的这个字符,是由两个字符构成,而<(?!/)完成的匹配只是 < 这个字符,而不包含 < 后面的那个字符,这样就能准确的表示 “匹配< ,同时<之后不能是/” - 再来看表达式
(?<!/)>,其中(?<!/)也是一个环视结构,(?<!..)是这个结构的标识,/才是真正的表达式,整个结构的意思是“在当前位置之前(左侧),不允许出现 / 能匹配的字符串”,(与上述的(?!/)类似,只是多出现 < ,更加形象的指向左侧),这样就可以准确表示“匹配 > ,同时 > 之前不能是 / ” - 至于我们所说的 < 与 > 之间的文本,可用
('[^']*'|"[^"]*"|[^'">])+ - 将上述的三部分结合起来,得到完整正则表达式
<(?!/)('[^']*'|"[^"]*"|[^'">])+(?<!/)>,它可以准确的匹配open tag,而且不会错误匹配self-close tag,如下图所示:
python测试
- 使用环视结构,准确匹配open tag
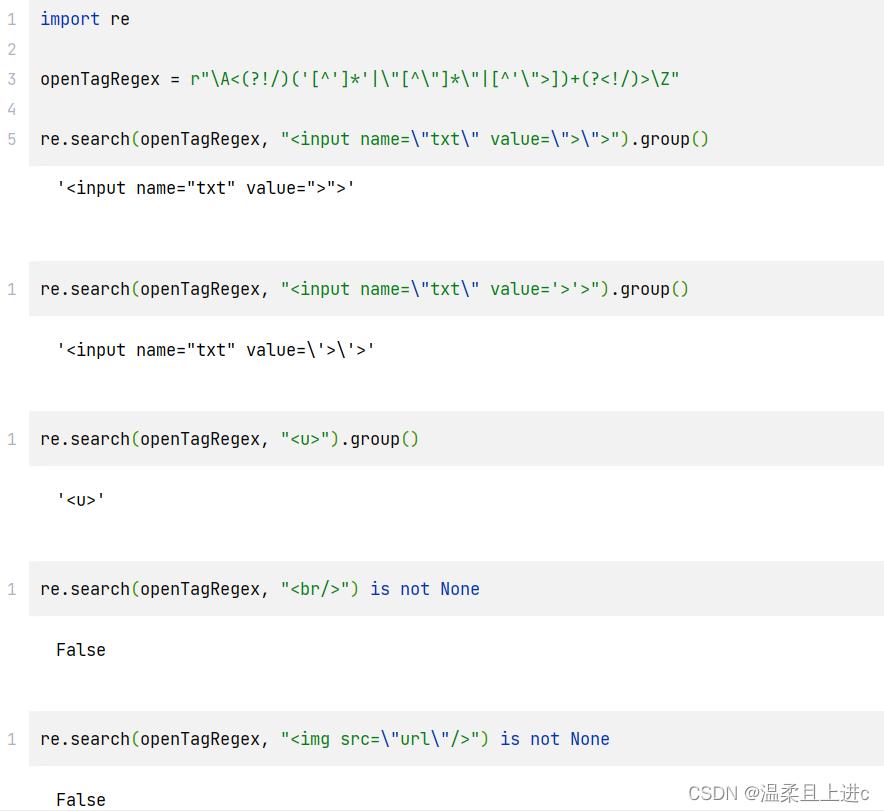
import re
openTagRegex = r"\\A<(?!/)('[^']*'|\\"[^\\"]*\\"|[^'\\">])+(?<!/)>\\Z"
re.search(openTagRegex, "<input name=\\"txt\\" value=\\">\\">").group()
re.search(openTagRegex, "<input name=\\"txt\\" value='>'>").group()
re.search(openTagRegex, "<u>").group()
re.search(openTagRegex, "<br/>") is not None
re.search(openTagRegex, "<img src=\\"url\\"/>") is not None
- 结果如下:
环视分类
- 在上述表达式中出现了两种环视:
(?!...)与(?<!...),他们分别是“否定顺序环视”与“否定逆序环视”,否定的意思是:“如果正则表达式匹配成功,则在当前位置匹配失败”,而顺序与逆序则表示 正则表达式需要匹配的文本所在的位置 - 环视一共分为四种:肯定顺序环视(positive-lookahead)、否定顺序环视(negative-lookahead)、肯定逆序环视(positive-lookbehid)、否定逆序环视(negative-lookbehind),如下表格所示:
| 结构名字 | 记法 | 判断方向 | 结构表达式匹配成功后的返回值 |
|---|---|---|---|
| 肯定顺序环视 | (?=…) | 向右 | True |
| 否定顺序环视 | (?!..) | 向右 | False |
| 肯定逆序环视 | (?<=…) | 向左 | True |
| 否定逆序环视 | (?<!..) | 向左 | False |
- 上述四个结构名字容易混淆,不妨这样理解:在当前位置,如果是朝右判断,则是顺序环视(lookahead),如果是朝左判断,则是逆序环视(lookbehind);如果要求子表达式能表达的字符串必须出现,则为肯定环视(positive),如果要求子表达式能匹配的字符串不能出现。则为否定环视(negative)
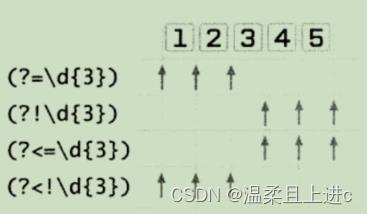
- 如下图说明:对于字符串12345,以
\\d3为表达式的四种环视能匹配的位置分别是:右侧必须出现三个数字字符,右侧不能出现三个数字字符,左侧必须出现三个数字字符,左侧不能出现三个数字字符
应用实例
给数字字符串添加千分位
- 环视的最大特点就是“原地执行”,之前所说的
<(?!/)匹配的其实只有一个字符<,(?<!/)>匹配的也是一个字符,虽然他们都需要测试/的匹配。有时确实需要用到”原地“判断,因为要寻找的确实只是一个位置,而不需要真正匹配任何字符,比如整理数字字符串的格式等等 - 如下举例:英文中的数字习惯用逗号(千分位)分以便阅读,比如12345应该写作12,345。如果使用正则表达式就是:“把逗号添加到右侧的数字长度是3的倍数的位置”,似乎看起来只要使用一个简单的肯定顺序环视就足够了。
- 第一次尝试:
用正则表达式找到这样的位置(?=(\\d3+)),将它替换成逗号(这里的意思其实是塞进去一个逗号),如下展示:
import re
re.sub(r"(?=(\\d3)+)", ',', "123456")

结果却不是我们所想象的那样。因为“右侧数字字符串”严格来说应该是“当前位置右侧,所有的数字字符构成的字符串”;但是(?=(\\d3)+)并不能表示这种意思,比如:第一个字符 1 之前的位置,右侧的数字字符串长度为5,但其中存在长度为3的字符串,所以这个位置也是可以匹配的。同样的2、3之前的位置也是如此
解决这个问题必须配合否定顺序环视,让(?=(\\d3)+)能匹配右侧的整个数字字符串,而不能只匹配其中的一个子串,也就是说,要一直匹配到“右侧不能再有数字字符的位置”为止
- 第二次尝试
将正则表达式改写成(?=(\\d3)+)(?!\\d),如下展示:
re.sub(r"(?=(\\d3)+(?!\\d))", ',', "12345")

从上述的结构来看似乎是没有问题的,但是如果当字符串的长度刚好为3的倍数时,还是会有小问题,如下:
re.sub(r"(?=(\\d3)+(?!\\d))", ',', "123456")

字符串的开头多出了一个错误的逗号,因为这个位置的右侧的数字字符串的长度为6。
- 第三次尝试
更严格的来描述加入逗号的位置:“右侧的数字字符串长度为3的倍数,且左侧也必须是数字字符”。所以还需要加上肯定逆序环视,将正则表达式修改为(?<=\\d)(?=(\\d3)+)(?!\\d),如下:
re.sub(r"(?<=\\d)(?=(\\d3)+(?!\\d))", ',', "123456")

仔细观察上述例子可以发现,表达式中出现了三个环视结构,还使用了嵌套与并列两种组合,下面在举一个例子
去除中英文混排文本中的中文空白字符
我们在日常中会碰到中英文混排的文本,英文文本需要使用空白字符来区分单词,中文文本中则很少出现空白字符,但是进行了某些操作(转贴或格式转换)时,可能会产生一些多余的空白字符:
"但行 好事,莫 问前程 Fortune favors the bold, 有多余 的 空白 字符"
正则表达式中删除空白字符是很容易的,直接使用\\s+即可。但是如果直接删除\\s+能匹配的文本,就会变成如下字符串
import re
spaceWorld = "但行 好事,莫 问前程 Fortune favors the bold, 有多余 的 空白 字符"
spaceRegex = r"\\s+"
re.sub(spaceRegex,'',spaceWorld)

所以在这里,真正要找的其实是这样的\\s+:“从它向左看,不能出现英文字母;从它向右看,也不能出现英文字母”,所有需要在\\s+的两端分别添加否定逆序环视与否定顺序环视,得到(?<![a-zA-Z])\\s+(?![a-zA-Z]),如下展示:
re.sub(r"(?<![a-zA-Z])\\s+(?![a-zA-Z])", '', spaceWorld)

在这里你或许会想,这个表达式是否能修改,比如左侧的否定环视(?<![a-zA-Z])能否修改为肯定环视,指定出现一个非英文字符(?<=[^a-zA-Z]),右侧的否定顺序环视也改为肯定顺序环视(?=[^a-zA-Z])?
乍一看是没有啥问题的,但是这个问题其实涉及的是肯定环视与否定环视的一大根本不同:肯定环视要判断成功,字符串中必须有环视结构中表达式能匹配得字符,而否定环视要判断成功,却是有两种情况:字符串中出现了不能由环视结构中表达式匹配的字符;或者字符串中不再有任何字符,也就是说,这个位置是字符串的起始位置或者结束位置
- 如下展示两种环视的区别:
# 否定环视
re.sub(r"(?<![a-zA-Z])\\s+(?![a-zA-Z])", '', spaceWorld)
# 肯定环视
re.sub(r"(?<=[^a-zA-Z])\\s+(?=[^a-zA-Z])", '', spaceWorld)
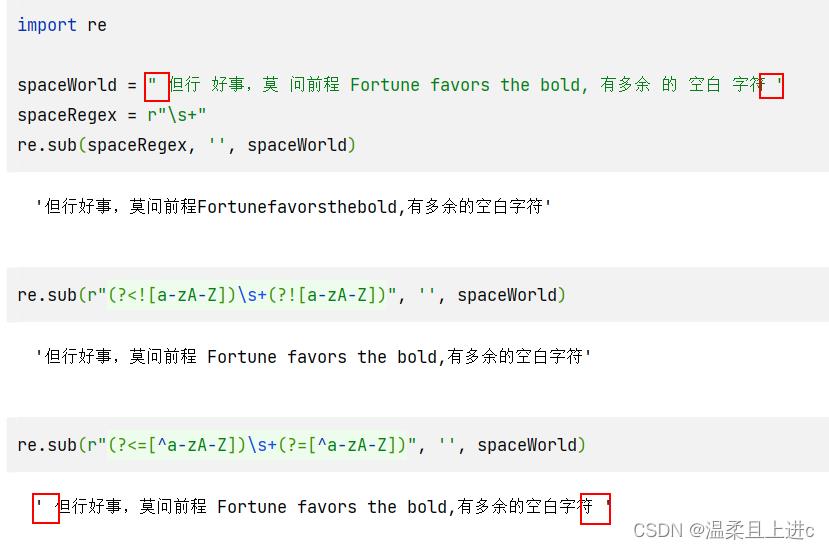
如果使用肯定环视,则无法去掉字符串首尾的空白。因为在字符串的开头,\\s+虽然能匹配空白字符,但其左侧并没有任何字符,所以(?<=[^a-zA-Z])无法匹配成功;字符串末尾(?=[^-zA-Z])也是这样的
以上是关于正则表达式高阶技巧之环视(使用python实现)的主要内容,如果未能解决你的问题,请参考以下文章