Python爬虫之Scrapy框架系列(17)——实战某代码托管平台登录FormRequest类
Posted 孤寒者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫之Scrapy框架系列(17)——实战某代码托管平台登录FormRequest类相关的知识,希望对你有一定的参考价值。
目录:
1. 分析:
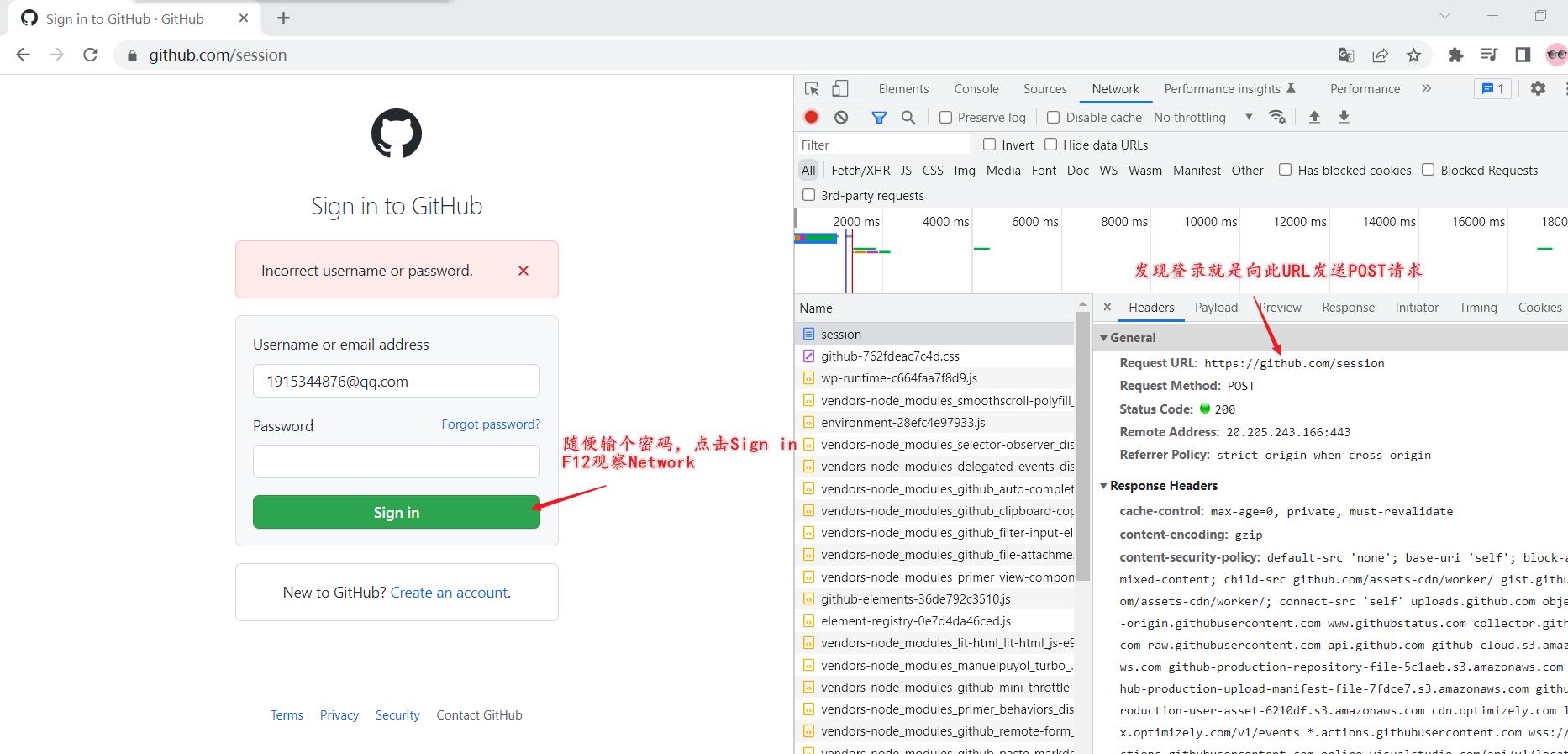
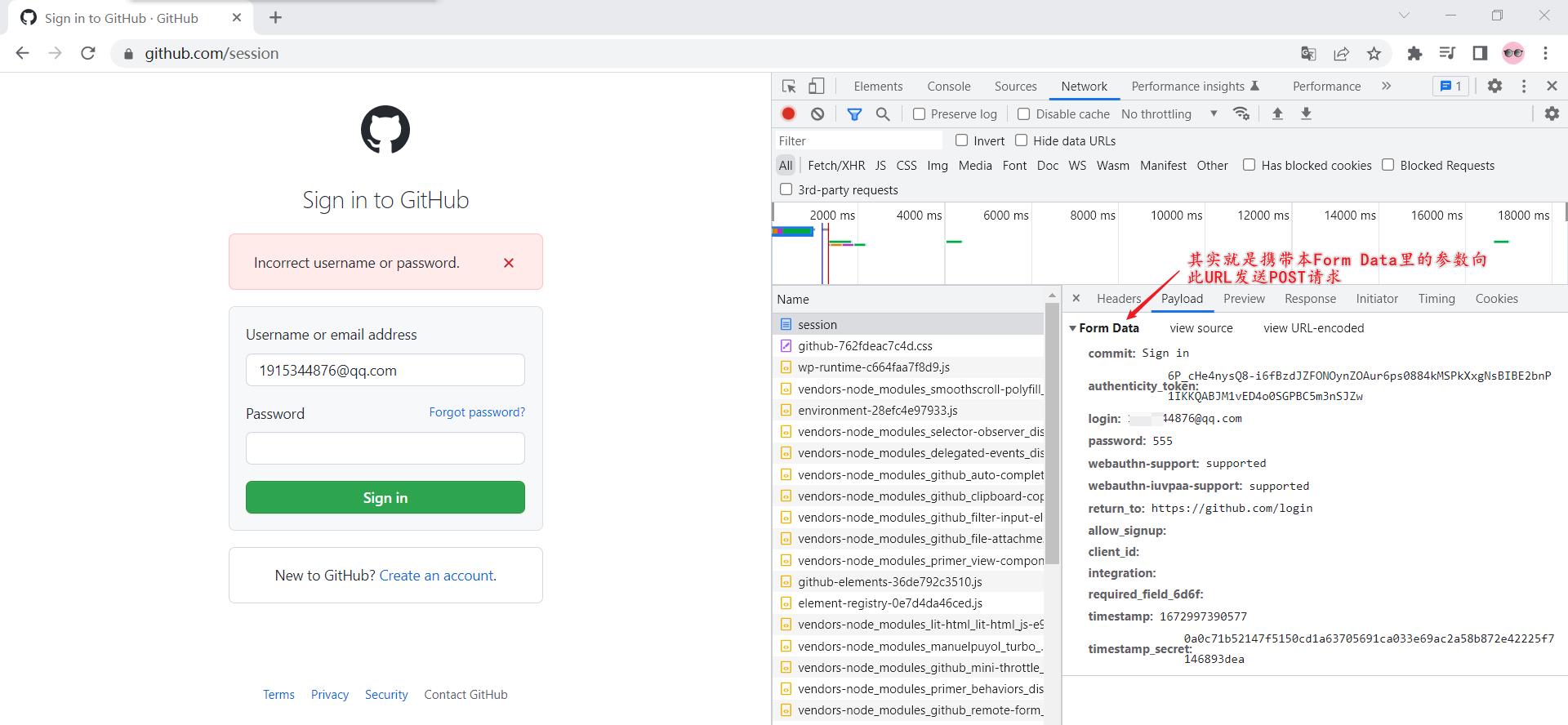
对比分析Form Data里的参数:
commit: Sign in
authenticity_token: 6P_cHe4nysQ8-i6fBzdJZFONOynZOAur6ps0884kMSPkXxgNsBIBE2bnP1IKKQABJM1vED4o0SGPBC5m3nSJZw
login: 1535744876@qq.com
password: 555
webauthn-support: supported
webauthn-iuvpaa-support: supported
return_to: https://github.com/login
allow_signup:
client_id:
integration:
required_field_6d6f:
timestamp: 1672997390577
timestamp_secret: 0a0c71b52147f5150cd1a63705691ca033e69ac2a58b872e42225f7146893dea
commit: Sign in
authenticity_token: 8jLR-7RV6lnl6GeG-pIYqYpLGXkc22imvcSW2jFl5ogm3t_MJQC4UIxWNlrawKGatNocfrvZWAIPTIIESCS5lw
login: 1535744876@qq.com
password: 222
webauthn-support: supported
webauthn-iuvpaa-support: supported
return_to: https://github.com/login
allow_signup:
client_id:
integration:
required_field_5097:
timestamp: 1672998098316
timestamp_secret: 8c45a1eb0ff77f65fb78375e683d9a27dd5e2202fb906f5693595286d578df6c
发现有以下参数是变化的:
- authenticity_token
- required_field_5097
- timestamp
- timestamp_secret
2. 分析上述变化的参数如何得到:
一般获取参数有两种方法:
- 动态拼接,这就需要分析JS(本小型实战不需要);
- 从前几级的页面获取,即请求前几级页面。
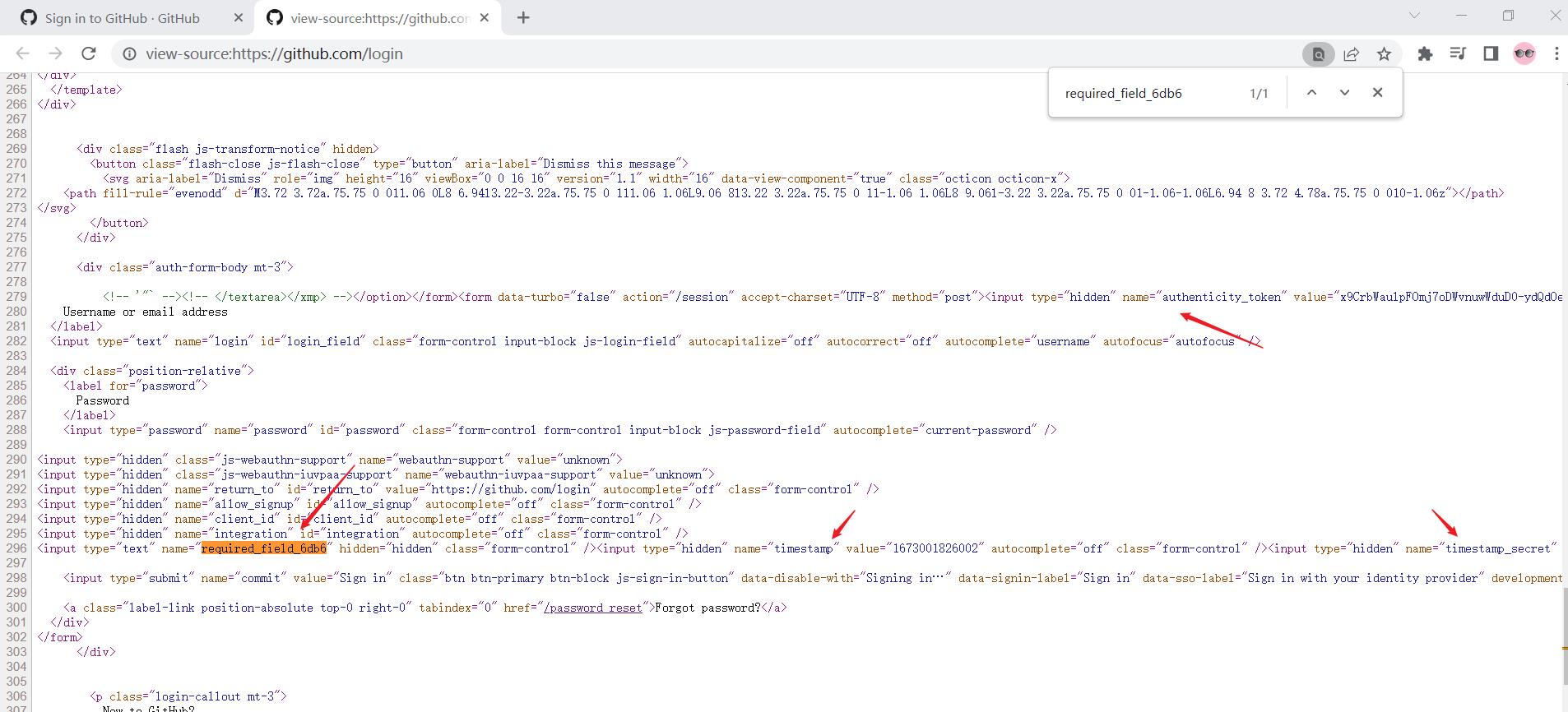
分析后发现上述四个参数在上级页面中都有:
3. scrapy项目编写:
3.1 创建项目及爬虫文件:
# 一、创建scrapy项目:
scrapy startproject LoginGithub
# 二、创建爬虫文件:
scrapy genspider ghlogin github.com/login
- 通过scrapy shell匹配参数value:

①编写爬虫文件:
import scrapy
from .new_dir.pw import P
class GhloginSpider(scrapy.Spider):
name = 'ghlogin'
allowed_domains = ['github.com']
start_urls = ['https://github.com/login']
def parse(self, response):
authenticity_token = response.xpath('//input[@name="authenticity_token"]/@value').extract()[0]
required_field_5097 = ''
timestamp = response.xpath('//input[@name="timestamp"]/@value').extract()[0]
timestamp_secret = response.xpath('//input[@name="timestamp_secret"]/@value').extract()[0]
# 至此完成了参数的提取
form_data =
"commit": "Sign in",
"authenticity_token": authenticity_token,
"login": "1915344876@qq.com",
"password": P,
"webauthn-support": "supported",
"webauthn-iuvpaa-support": "supported",
"return_to": "https://github.com/login",
"allow_signup": "",
"client_id": "",
"integration": "",
"required_field_5097": "",
"timestamp": timestamp,
"timestamp_secret": timestamp_secret,
yield scrapy.FormRequest(url="https://github.com/session", callback=self.verify_login, formdata=form_data)
def verify_login(self, response):
if "Join GitHub Global Campus!" in response.text:
print("github登录成功~")
- 密码在这:
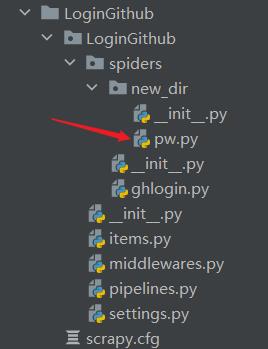
- 别忘了关robots协议,开请求头~
②效果—登陆成功:

Pycharm骚操作拓展:
如何快速给形如下述的多组key: value形式的数据的key和value都加上双引号?
commit: Sign in
authenticity_token: 8jLR-7RV6lnl6GeG-pIYqYpLGXkc22imvcSW2jFl5ogm3t_MJQC4UIxWNlrawKGatNocfrvZWAIPTIIESCS5lw
login: 1915344876@qq.com
password: 222
webauthn-support: supported
webauthn-iuvpaa-support: supported
return_to: https://github.com/login
allow_signup:
client_id:
integration:
required_field_5097:
timestamp: 1672998098316
timestamp_secret: 8c45a1eb0ff77f65fb78375e683d9a27dd5e2202fb906f5693595286d578df6c
- CV到一个空.py文件里,Ctrl+r:
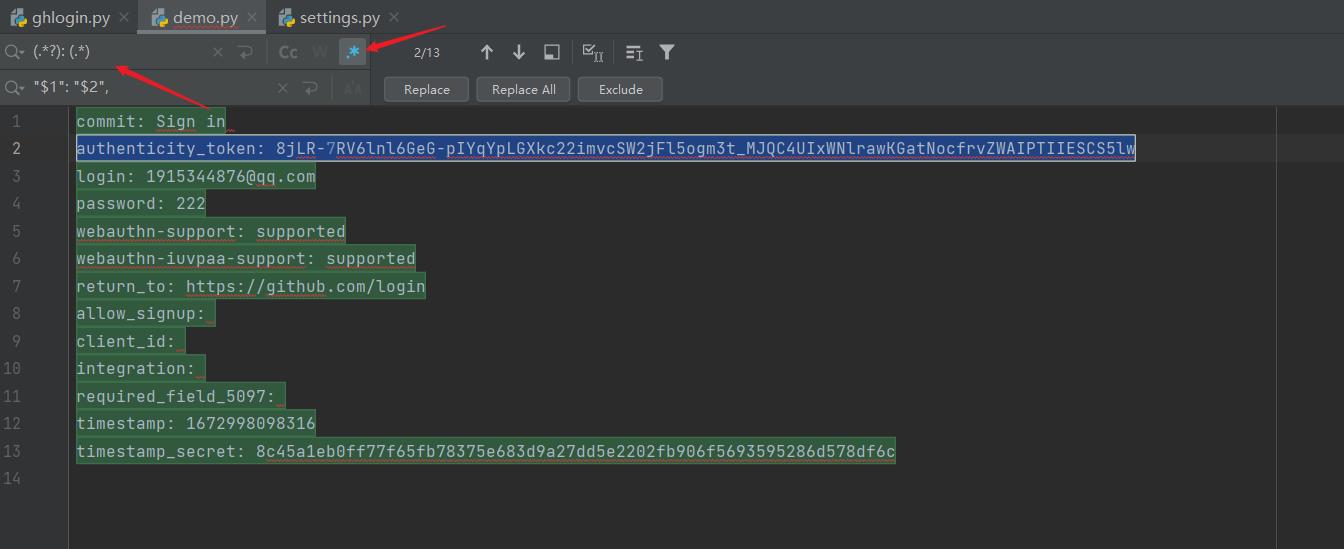 - Replace All即可。效果如下:
- Replace All即可。效果如下:
"commit": "Sign in",
"authenticity_token": "8jLR-7RV6lnl6GeG-pIYqYpLGXkc22imvcSW2jFl5ogm3t_MJQC4UIxWNlrawKGatNocfrvZWAIPTIIESCS5lw",
"login": "1915344876@qq.com",
"password": "222",
"webauthn-support": "supported",
"webauthn-iuvpaa-support": "supported",
"return_to": "https://github.com/login",
"allow_signup": "",
"client_id": "",
"integration": "",
"required_field_5097": "",
"timestamp": "1672998098316",
"timestamp_secret": "8c45a1eb0ff77f65fb78375e683d9a27dd5e2202fb906f5693595286d578df6c",
以上是关于Python爬虫之Scrapy框架系列(17)——实战某代码托管平台登录FormRequest类的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫之Scrapy框架系列(10)——Scrapy选择器selector
Python爬虫之Scrapy框架系列(10)——Scrapy选择器selector
Python爬虫之Scrapy框架系列(16)——深入剖析request和response类
Python爬虫之Scrapy框架系列(16)——深入剖析request和response类