java-2016-10-04
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java-2016-10-04相关的知识,希望对你有一定的参考价值。
1.下列正确的是(A)
A.形式参数可被视为local variable
B.形式参数可被所有的字段修饰符修饰
C.形式参数为方法被调用时,真正被传递的参数。
D.形式参数不可以是对象
注:
2.Which keyword can protect a class in a package from accessibility by the classes outside the package?(D)
A.private
B.protected
C.final
D.don‘t use any keyword at all (make it default) ?
注:
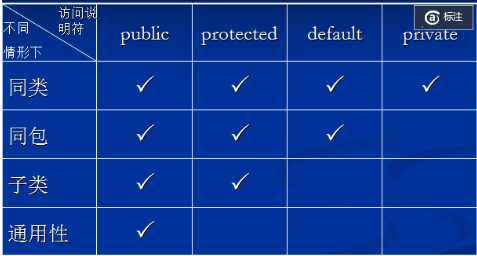
如果一个类声明为protected,它的子类是可以访问它的,如果它和子类不在一个包中,子类仍然可以访问该类,所以这里选择default,即什么都不写
3.
正确答案: C 你的答案: B (错误)
NullPointerException
ClassCastException
FileNotFoundException
IndexOutOfBoundsException

通常,Java的异常(包括Exception和Error)分为 可查的异常(checked exceptions)和不可查的异常(unchecked exceptions) 。
可查异常(编译器要求必须处置的异常): 正确的程序在运行中,很容易出现的、情理可容的异常状况 。 可查异常虽然是异常状况,但在一定程度上它的发生是可以预计 的,而且一旦发生这种异常 状况,就必须采取某种方式进行处理。
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于可查异常。这种异常的特点是Java编译器会检查它,也就是说,当程序中可能出现这类异常,要么 用try-catch语句捕获它,要么用throws子句声明抛出它,否则编译不会通过。
不可查异常(编译器不要求强制处置的异常):包括运行时异常(RuntimeException与其子类)和错误(Error)。
4.
正确答案: A C D 你的答案: C D (错误)
在类方法中可用this来调用本类的类方法
在类方法中调用本类的类方法时可直接调用
在类方法中只能调用本类中的类方法
在类方法中绝对不能调用实例方法
正确答案: C D 你的答案: A B (错误)
每个中文字符占用2个字节,每个英文字符占用1个字节
假设数据库中的字符是以GBK编码的,那么显示数据库数据的网页也必须是GBK编码的。
Java的char类型,以下UTF-16 Big Endian的方式保存一个字符。
实现国际化应用常用的手段是利用ResourceBundle类
注:
UTF-32
UTF-16 以及「代理对」( Surrogate Pairs )的概念
UTF-16要常见得多,它是根据有 16 位固定长度的码元( code units )定义的。UTF-16 本身是一种长度可变的编码。基本多文种平面(BMP)中的每一个码点都直接与一个码元相映射。鉴于 BMP 几乎囊括了所有常见字符,UTF-16 一般只需要 UTF-32 一半的空间。其它平面里很少使用的码点都是用两个 16 位的码元来编码的,这两个合起来表示一个码点的码元就叫做代理对( surrogate pair )。
UTF-8
UTF-8 使用一到四个字节来编码一个码点。从 0 到 127 的这些码点直接映射成 1 个字节(对于只包含这个范围字符的文本来说,这一点使得 UTF-8 和 ASCII 完全相同)。接下来的 1,920 个码点映射成 2 个字节,在 BMP 里所有剩下的码点需要 3 个字节。Unicode 的其他平面里的码点则需要 4 个字节。UTF-8 是基于 8 位的码元的,因此它并不需要关心字节顺序(不过仍有一些程序会在 UTF-8 文件里加上多余的 BOM)。
正确答案: A B C D 你的答案: C (错误)
引导类加载器(bootstrap class loader):它用来加载 Java 的核心库,是用原生代码来实现的
扩展类加载器(extensions class loader):它用来加载 Java 的扩展库。
系统类加载器(system class loader):它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类
tomcat为每个App创建一个Loader,里面保存着此WebApp的ClassLoader。需要加载WebApp下的类时,就取出ClassLoader来使用
注:
bootstrap classloader -引导(也称为原始)类加载器,它负责加载Java的核心类。 extension classloader -扩展类加载器,它负责加载JRE的扩展目录(JAVA_HOME/jre/lib/ext或者由java.ext.dirs系统属性指定的)中JAR的类包。 system classloader -系统(也称为应用)类加载器,它负责在JVM被启动时,加载来自在命令java中的-classpath或者java.class.path系统属性 或者 CLASSPATH*作系统属性所指定的JAR类包和类路径
以上是关于java-2016-10-04的主要内容,如果未能解决你的问题,请参考以下文章