Note1网络,并发/IO,内存,linux/vi命令,正则,Hash,iNode,文件查找与读取,linux启动/构建
Posted 码农编程录
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Note1网络,并发/IO,内存,linux/vi命令,正则,Hash,iNode,文件查找与读取,linux启动/构建相关的知识,希望对你有一定的参考价值。
文章目录
- 1.局域网:CSMA/CD
- 2.互联网:ARP,DHCP,NAT
- 3.TCP协议:telnet,tcpdump,syn/accept队列
- 4.HTTPS协议:摘要(sha、md5、crc)。win对文件进行MD5校验用自带的certutil工具:certutil -hashfile a.tar.gz MD5,linux:md5sum a.tar.gz
- 5.线程/协程/异步:并发对应硬件资源是cpu,线程是操作系统如何利用cpu资源的一种抽象
- 6.并发:cpu,线程
- 7.IO多路复用:硬盘和网卡
- 8.操作系统内存管理与分类:分页,页大小位数=偏移量
- 8.1 内存条/总线/DMA(硬件):CPU和DMA是同级,两者对总线控制是轮换隔离
- 8.2 用户态和内核态:程序运行过程中可能处于内核态,也可能处于用户态,某一时刻处于用户态,下一时刻可能切换到用户态(但必须有触发条件)
- 8.3 分页:为了减少碎片问题
- 8.4 分段:程序内部的内存管理即分段,堆区和栈区就是程序的段
- 8.5 IPC:进程间通讯
- 8.6 free -h:查看内存条:dmidecode |grep -P -A5 "Memory\\s+Device"|grep Size|grep -v Range
- 8.7 brk:用户无法操作硬件如内存条,必须交给内核帮我们操作完了再把结果给我们
- 8.8 mmap:pidstat,缺页缺的是内存还是磁盘
- 9.JVM内存5区:jvm即java二进制字节码的运行环境,好处:一次编写,到处运行。自动内存管理和垃圾回收功能。数组下标越界检查。多态。
- 10.VMware/CentOS/CRT:两个网络适配器是虚拟机的,Linux抄袭unix,Mac os是unix的皮肤
- 11.Linux命令:linux组成:内核(就是操作系统,和硬件打交道,驱动)。shell(和用户打交道,用户指令翻译成机器码给内核)。文件系统(文件组织方式,linux没有盘符,有目录/文件/链接link)。应用程序
- 12.vi命令:三种(命令行[Esc],编辑[i],底行[:wq])模式切换
- 13.正则:\\d,?* +这些是[a-z]m,n这些的简写
- 14.iNode:磁盘中块和扇区
- 15.文件查找与读取命令:C语言中‘\\0’(对应的ASCLL码值为0)表示的空字符
- 16.Linux下开机自动重启脚本:/etc/rc.local,Crontab,Systemd
- 17.Linux系统启动过程:ukr,ubuntu开机引导文件/etc/default/grub
- 18.编译u-boot 2019.10和linux-kernel 5.3.6并用busybox打包根文件系统:在全志H5芯片上启动起来
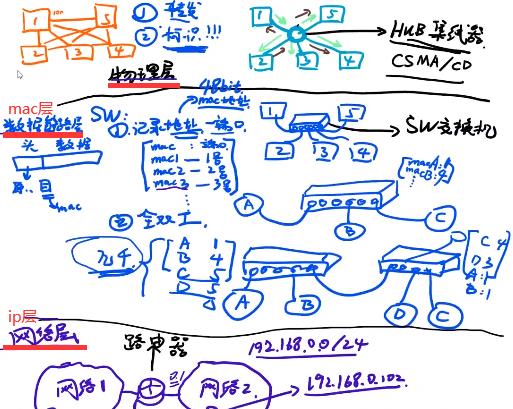
1.局域网:CSMA/CD
1.早期通过双绞线(只能有一台设备进行数据发送),通过10100…高低电平就能表示数据信号。标识:1–>3,3需要表明自己身份是3。
2.通过集线器广播给所有设备,2345自己分辨是我的消费了,不是我的数据包丢弃。如果1,2同时广播,4收到2个消息混合解析不出,导致1,2这两个数据包全没法用。针对上面问题提出CSMA/CD协议:发送前进行载波侦听,检测这链路上有没有其他人正在发送数据,没有的话再进行数据发送防冲突。hub集线器缺点:1.进行数据的广播会导致带宽利用率较低。2.在链路上同时只能有一个设备发送数据,链路利用率低。3.没有标识,只是广播出去,让设备自己判断是不是自己的,工作效率低。

3.如下机器1想发到机器3,通过SW寻址到3号口。SW记录了地址(mac地址)和端口(此处端口不是电脑端口而是交换机端口)的映射关系不用广播(集线器),SW用的是网线,里面有8根线,正常情况至少4根线是在工作的,所以实现全双工。买来交换机里是张空表,怎么建立映射关系?如下机器A插上来后要向B发送数据,发现是空表,确定A是1号口,B找不到就往每个端口发,4号口对B做出了回应,表记录B对应4号口。桥接(如没有映射关系,C和D都对应5,5口转到另一个SW,量大之后不断桥接引起消息洪泛)实现几千条存储,几千条不够至少几十亿。如下mac和端口的映射表不是路由表,局域网(家庭网,校园网等)使用交换机效率高。
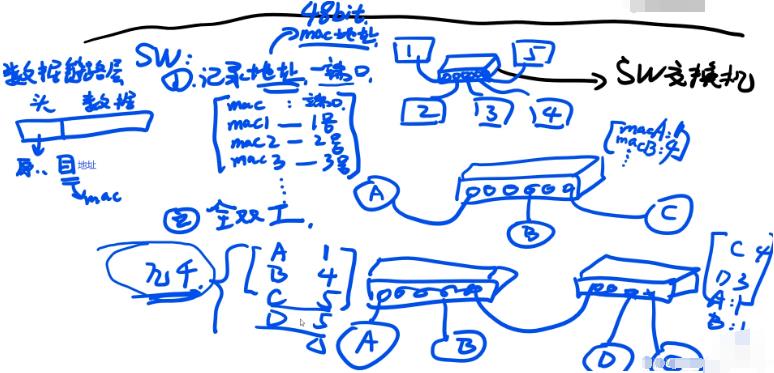
2.互联网:ARP,DHCP,NAT
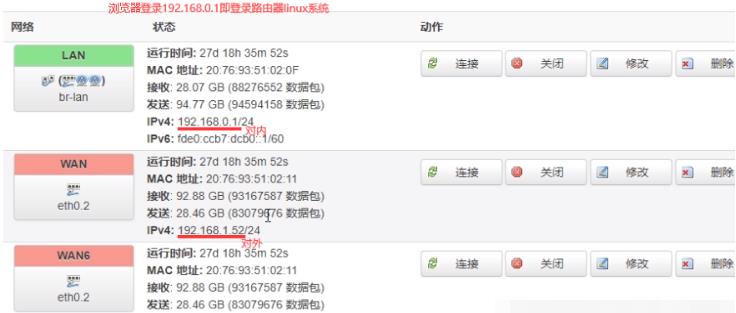
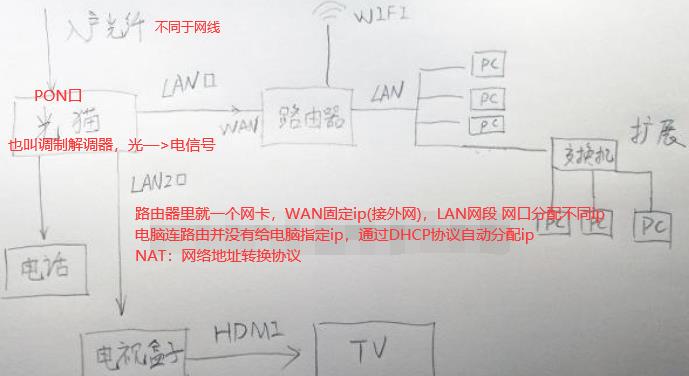
SW交换机的映射表只能实现几千存储,如果表中记录满了,新的来会把旧的替代,所以跨网用路由器(也称网关)。如下家庭网是整个网络2,每台机器都有自己的路由表如ubuntu有路由表,路由器也是linux系统也有路由表。本台电脑的路由表会写默认网关是192.168.0.1(这个点在路由器上),本台电脑就会把数据包发到路由器上,这个路由器自己也有路由表路由到1.52这个网卡,1.52和1.254和1.1在同一个网段下很容易找到。路由器的路由表比SW交换机的映射表复杂用到了很多路由算法。
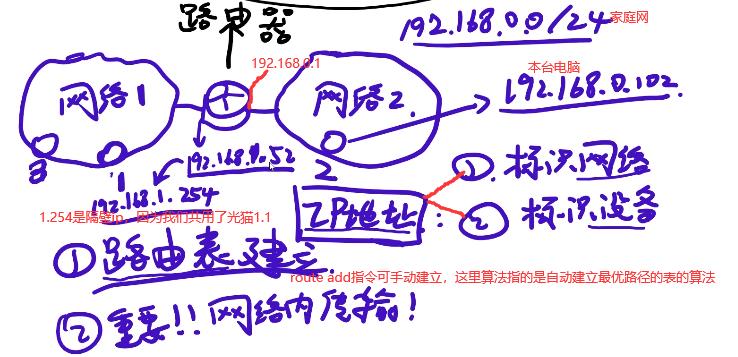
ping 192.168.1.254可通,那么网络内传输如1.52—>1.254即网络内怎么传数据的呢?同一网段一找就找到这样的说法是错的,若是这样为什么有了IP地址还要mac地址呢?ip地址(抽象地址)不能直接通信,只能用mac地址(真实地址)通信,ARP协议广播询问谁的ip是1.254,1.254收到这询问就会回复一下,说我的地址是1.254,我的mac地址是。。。1.52知道了1.254对应的mac地址就会在mac层进行传输。

ip的数据包就是mac的数据部分,越往上层(往里)ip层包着还有tcp层,ip数据包里数据部分还会有tcp的头,再往上层(往里)还可能有http的头,最后的数据才是我们要传的数据。
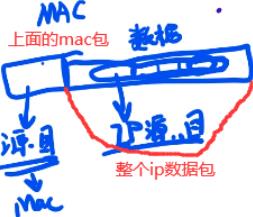
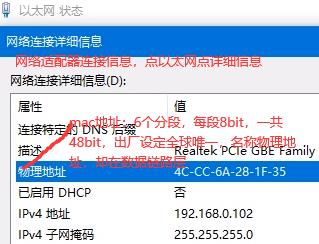
获取mac地址都是通过ARP协议(cat /proc/net/arp),如下ip的源目地址是不变的,一直为0.102和1.254,只有mac地址一直在切换(竖着对比)。有个特例NAT(网络地址转换协议):源地址ip也会进行切换。

ifconfig eth0 hw ether aa:11:22:88:cc:dd #更改mac地址
ifconfig eth0 up
dhclient eth0
# /recipes-plats/network/files/eth1_mac_fixup.sh # Fixup the MAC address for eth0 based on baseboard EEPROM
PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/bin
count=0
while [ $count -lt 3 ]
do
str=$(fruid-util cmm | grep "BMC Base Mac address" | awk -F ":" 'print $2')
str=$(echo $str |sed 's/ //g')
if [ $#str -ne 12 ];then # 获取字符串长度
logger "Loop $count failed to read BMC FRU:$str"
count=$(($count + 1))
sleep 1
continue
fi
mac="$str:0:2:$str:2:2:$str:4:2:$str:6:2:$str:8:2:$str:10:2" #中间有冒号
if [ -n "$mac" -a "$mac/X/" = "$mac" ]; then # mac有值返回true,不用管X
logger "Loop $count success to configure BMC MAC: $mac"
#ip link set dev eth1 address "$mac"
#在/etc/rc.d/rc.local里加上如下三句,reboot后就不怕MAC复原了
/sbin/ifdown eth1
/sbin/ifconfig eth1 hw ether $mac
/sbin/ifup eth1
sleep 1
exit 0
fi
count=$(($count + 1))
sleep 1
done
if [ $count -ge 3 ]; then
echo "Cannot find out the BMC MAC" 1>&2
logger "Error: cannot configure the BMC MAC"
exit -1
fi
# config_mac
. /usr/local/bin/openbmc-utils.sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/bin
prog=$(basename "$0")
usage()
echo "Usage: $prog <mac>"
echo
echo
echo "Examples:"
echo " $prog XX:XX:XX:XX:XX:XX"
echo
exit 1
check_parameter()
mac=$1
strlen=$#mac
if [ $# -ne 1 ] ;then
usage
fi
if [ "$strlen" -ne 17 ] ;then
usage
fi
set_mac()
mac=$(echo "$mac" | sed 's/://g'| tr '[:a-z:]' '[:A-Z:]')
/usr/local/bin/fruid-util base --dump /tmp/base_fru.bin
/usr/local/bin/fruid-util base --modify --PCD2 "$mac" /tmp/base_fru.bin > /dev/null 2>&1
set_mac_eeprom_wp
/usr/local/bin/fruid-util base --write /tmp/base_fru.bin > /dev/null 2>&1
reset_mac_eeprom_wp
check_mac()
fru_mac=$(/usr/local/bin/fruid-util base |grep "Product Custom Data 2" | awk -F ': ' 'print $2')
if [ "$mac" != "$fru_mac" ] ;then
echo "Set mac fail"
fi
check_parameter "$@"
set_mac
check_mac
root@bmc:~# fruid-util base
Product Custom Data 2 : 78D4F15F171D
root@bmc:~# ./config_mac 78:D4:F1:5F:17:1a
root@bmc:~# fruid-util base
Product Custom Data 2 : 78D4F15F171A
vi /etc/sysconfig/network-scripts/ifcfg-eth0 。MACADDR=00:11:22:33:44:55 。改好执行/etc/init.d/network stop ,/etc/init.d/network start。
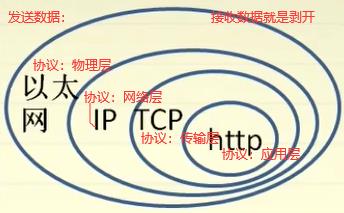
如下图物理层—>mac层—>ip层,物理层和mac层统称为链路层。
如下TCP/IP架构:以太网协议mac:把cpu想要发送的数据封装为以太网协议(网卡完成这功能)。ip协议:实现路径的管理,传输过程中根据想要发送的目标地址,帮我们的报文在网络中选择一条传输路径(路由器完成这功能)。ip协议针对目标是机器与机器之间通信,平时利用网络过程中需要进程与进程的通信,所以传输层(tcp/udp协议)这层封装有必要,应用层可以自己去定义。
udp:实验室内部交流终端,发信息时效性要高如语音、视频、直播等,丢个一帧两帧影响不大,数据是不停的过来,在ip协议基础上增加了很少一部分功能同时它不是面向连接的,不需要对方给我一个反馈,减少了传输的成本,相对来说时延也小得多。
tcp:传一些重要内容,如发一个公告或给谁发一个文件,这个过程对时效性没那么强,传文件稍微等一会也没事但要求传输的准确不能出错,TCP复杂面向连接。
如下应用层:POST /xxx.html HTTP/1.1。
如下拆包和粘包,Client和Server间的Packet1被拆包,与Packet2粘包:

如下解决粘包拆包:头/定长/分隔符。

如下是第一种方法,粘包还是会出现,但可以区分开。

如下是第三种方法,自定义分隔符。

交换机 ,二层交换机 ,多接口网桥是一个东西。路由器 ,三层交换机 ,网关是一个东西。

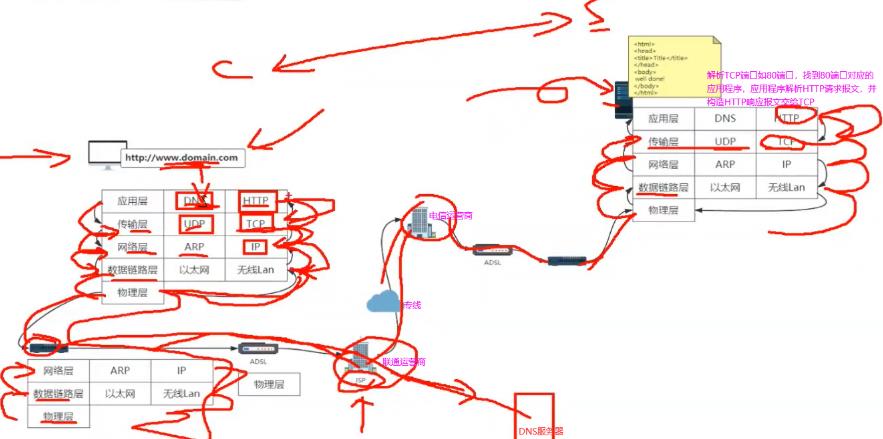
从一个HTTP请求来看网络分层原理:内网里通过网线进行传输,连接到公网的话会通过光纤进行连接。要实现不同介质间信号的转换,还有从光纤到路由器无线脉冲转换,距离远的话还有信号衰减问题。如下把问题分层,不同层间定义标准化接口让它们间可进行数据通信。

1.如下右边一个服务器部署了一个静态页面,通过nginx部署在公网上,看下浏览器里有没有域名对应DNS的缓存,有的话直接拿到服务端的ip地址,没有的话去浏览器本地的host文件看有没有配置,没有配置的话才会发起一个DNS请求用来获取服务器ip地址。
2.DNS也是台服务器也有自己的ip地址通常配在自己的操作系统上,这时应用层会构造一个DNS请求报文,应用层会去调用传输层的接口一个socket的API,DNS默认使用UDP实现数据传输,传输层会在DNS请求报文基础上加一个UDP的请求头。传输层将数据交给网络层,网络层同样在UDP请求报文基础上加IP的请求头,网络层会将IP请求报文交给数据链路层,数据链路层会将自己的mac头加上去并把对应的请求报文交给下一个机器的mac地址也会加上去。下一个机器的mac地址通过网络层ARP协议找到,ARP会发送一些请求看下你对应的ip地址的mac地址是多少,最后通过物理层物理介质传出去,通常传到路由器上。
3.路由器是三层设备(从下向上,物理/数据链路/网络)从物理层开始连接,物理层交给数据链路层,数据链路层看下地址是不是给我的,是给我的进行解析,不是给我的就丢弃,报文再传给上面一层网络层,网络层把数据传到下一个路由器的地址是多少,会通过运营商的网络接口传到运营商的路由器上。
4.运营商有自己的DNS服务器,如果配的是运营商自己的DNS服务器的话会直接在这个DNS服务器里找自己对应的域名拿到对应的ip地址,也就是刚请求DNS报文地址,然后原路返回解析直到应用层拿到刚域名对应得ip地址,这样就可以进行HTTP请求报文的发送。再调用传输层协议是TCP参数,同样每到一层加头。
如下名字里有传输但并没有做传输的事情,HTTP协议数据传输交由TCP协议进行的。无状态:本身不会存储用户信息。可扩展:头部字段可扩展给业务带来灵活性。自描述消息格式:消息类型可以是文本也可以是图片音视频类型,根据消息类型知道对应数据是什么类型。

发起HTTP请求是想从服务器上拿到资源或对资源修改。如果返回是HTML,浏览器会构造一个DOM数据结构,会解析HTML里有没有其他网络请求,有其它网络请求会继续向服务端发送网络请求,拿到报文后会渲染页面。HTTPS会有一个TLS握手。
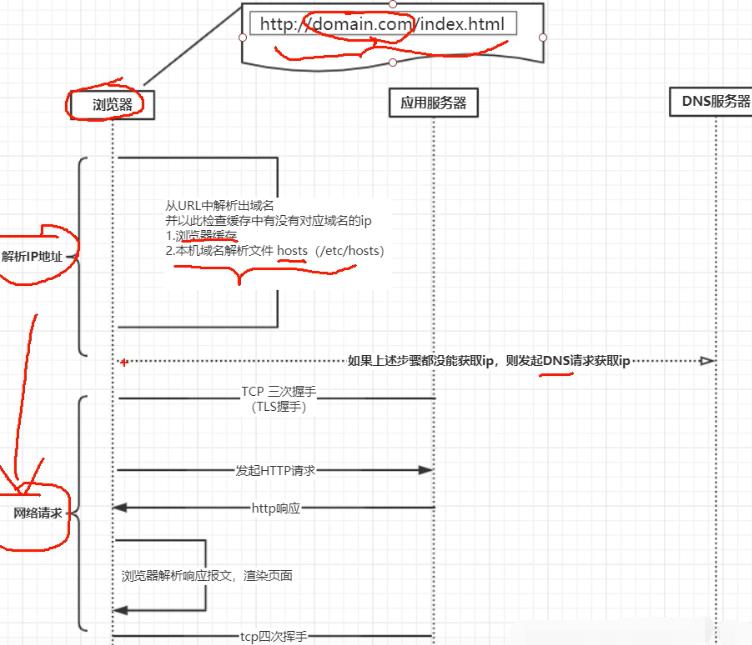
Linux下/etc/hosts文件如下行:主机名(hostname)和域名(domain)的区别在于,主机名通常在局域网内使用,通过hosts文件,主机名就被解析到对应ip。域名通常在internet上使用,但如果本机不想使用internet上的域名解析,这时就可以更改hosts文件,加入自己的域名解析。

3.TCP协议:telnet,tcpdump,syn/accept队列
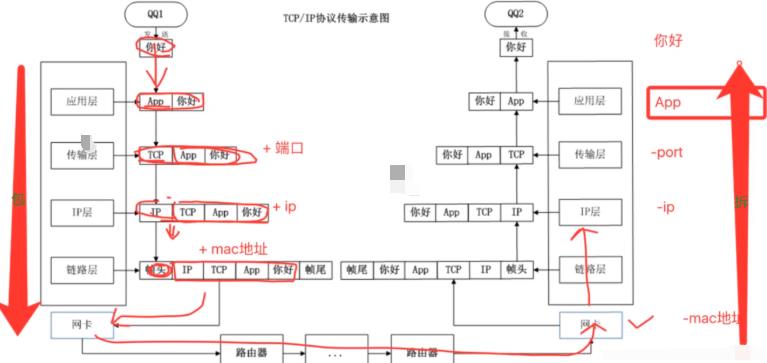
文件大会进行切分成segment片段,将分片排序0,1,2…。传输中间线路路由器多且复杂,012…会乱,所以到达接收端要重排序再传给上层应用层。流量缓冲:三次握手时客户端和服务器双方都会创建一个缓冲区。可靠性传输服务:面向连接,数据发过去了,客户端一定要收到服务端响应,才认为包到达了服务端,没收到响应,客户端需要超时机制完成数据重发。拥塞控制:当网络差时,tcp协议栈还要考虑发送数据报文大小和发送频率。
如下是TCP报文,Source port源端口如果是发送端的话是随机生成的,tcp三次握手之前要知道对方端口目的Dest port,和服务器建立连接web服务一般80端口如nginx。unused保留字段,CWR到FIN是报文标识flag,标识报文什么类型的,如果把syn的bit位设为1的话,当前报文是同步序列号即建立连接的报文,ack的bit为1代表响应报文。Receive window是当前服务器可接受数据大小窗口的值。
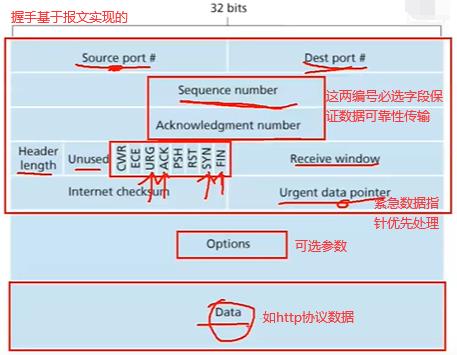
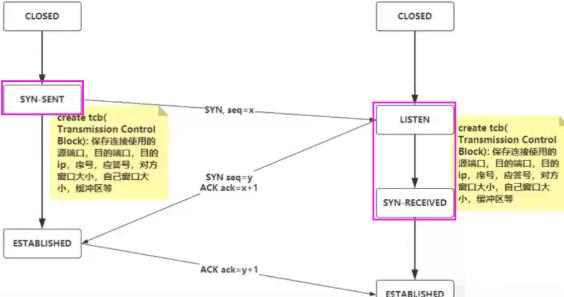
如下加上TCP协议头就是五元组,基于TCP的基础上就是四元组。如下三次握手主要做了a和b两件事。

如下服务端先进入listen状态,如nginx的话会监听某个端口(如web服务就是80端口),客户端发送请求前会创建一个数据结构(下面黄色)用来存储要发送的端口号等,客户端报文一发出去,客户端立马进入syn-sent状态,服务端收到syn(Synchronous number,同步序列号)报文时也会在本地创建一个对应的数据结构。
客户端可以发送很多TCP报文,每个报文都有自己的随机生成算法生成自己的序列号,所以x+1是对x这个报文的响应。建立连接会消耗非常多系统资源(create tcb…),所以不用时要关闭(四次挥手)。中间SYN和ACK可以合在一起节省流量,也可以拆分开。
下面通过实验看三次握手怎么进行的:
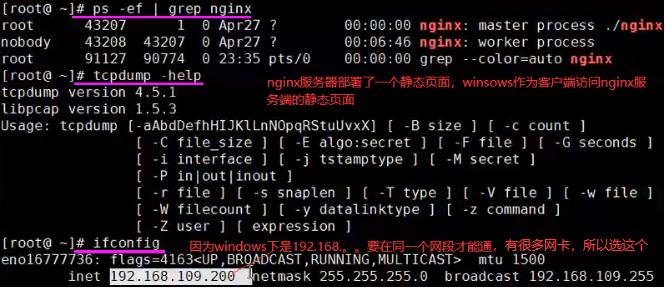
如下nc命令会发一个TCP三次握手请求,输入服务器地址和端口。

如下查看tcp连接状态,-t参数查看当前tcp连接状态,-p显示进程,-n数字型显示ip和端口。如下就是win系统和linux系统建立的连接。

如下是tcp四次挥手,关闭连接(客户端或服务端都可以直接关,全双工),主动方会进入time_wait状态,MSL是最大的报文生成时间,2MSL就是报文一个来回时间。没有2MSL立马关闭会造成第一(服)个问题:ACK j+1这个报文丢失,服务端没收到ACK会不断重发FIN报文,服务端资源没法释放。第二(客)个问题:关闭连接意味着资源被释放了,那么端口号被其他进程使用,报文到来时根据tcp的四元组恰好碰到刚释放掉那个连接,造成混乱。
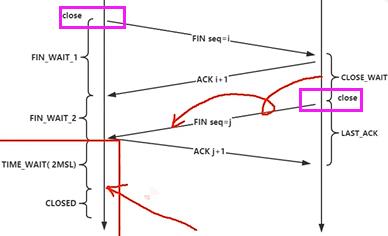
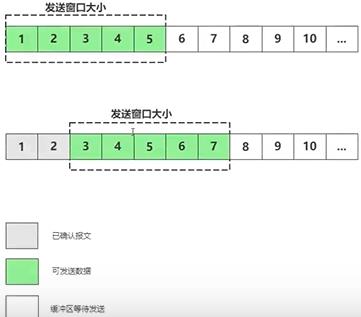
滑动窗口协议与累计确认(延时ack):可延时ack的发送,确认最后一个报文如5就可以。但这样有一个问题如3的报文丢了,这时只能确认1和2连续报文,从3以后的报文全要重传,已确认的报文在缓冲区丢弃掉。
4.HTTPS协议:摘要(sha、md5、crc)。win对文件进行MD5校验用自带的certutil工具:certutil -hashfile a.tar.gz MD5,linux:md5sum a.tar.gz
Hash散列算法(应用于哈希表和摘要密码学),是把任意长度的输入通过特定的算法变换成固定长度的输出,输出的值就是hash值。这个特定的算法就叫hash算法,hash算法并不是一个固定不变的算法。只要是能达到这个目的的算法都可以说hash算法。例如MD5,SHA,String.hashcode()都是hash算法。
不同的输入可能会得出相同的hash值,那么这种现象称为hash碰撞,无论是采用那种hash算法,hash碰撞都是不可避免的,我们只能通过改进hash算法,把出现碰撞的概率降低。hash英语中的意思是剁碎的食物,反应在计算机领域大概就是把任意数据切割打碎,输出固定长度的数据。

先解AES,再用AES解image。
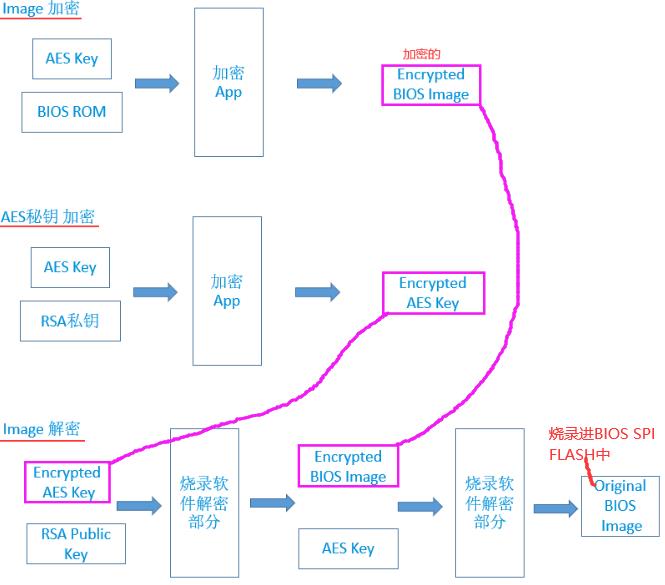

HTTPS利用摘要(也叫hash散列,用于校验信息完整性,确保文件没被修改)和加密(对称【一个密钥】和非对称【2个密钥】)算法完成加密通道。
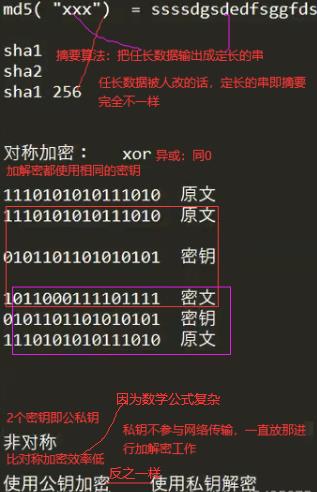
如下用到的公私钥都存在Server端。

5.线程/协程/异步:并发对应硬件资源是cpu,线程是操作系统如何利用cpu资源的一种抽象
线程想提高效率和io密切相关,程序往往都含有io。CPU上下文切换就是先把前一个任务的CPU上下文(也就是CPU寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
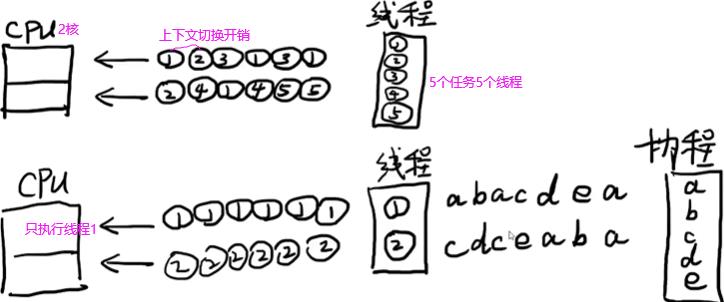
线程(操作系统级别概念)是cpu调度的最小单位,cpu并不在意是哪个进程,cpu就是轮换着线程来运行并不需要知道这个线程是属于哪个进程的。左边单核cpu(不是单线程),3个线程(任务都是读取文件)交叉运行完。
通过以下两点大大提高了cpu利用率,因而线程想提高效率和io密切相关。
1.DMA过程中cpu一段时间不被线程阻塞。
2.DMA进行数据读取时可复用,因为cpu的总线程具有多条线路,所以DMA可充分利用这些线路,实现并行读取这些文件。
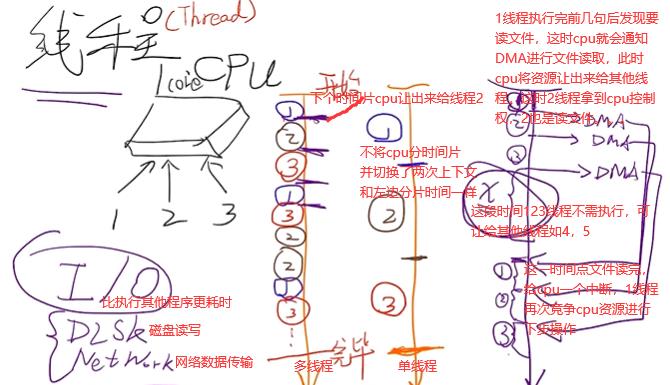
多线程需调用系统底层API才能开辟,在多线程开辟过程中浪费时间,并且在线程运行中上下文切换部分(左边切换多次,右边切换三次)有用户态和内核态转换耗,效率浪费在cpu切换时间点上。所以服务端连接的客户端不活跃多(即io次数少),考虑单线程(io多路复用或nio)或协程。上面的1,2,3线程都有io,所以多线程效率高。
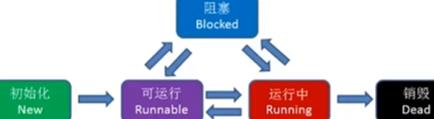
如何利用cpu资源?os给了我们两种抽象即进程和线程。进程是系统资源分配,调度和管理的最小单位,比如去任务管理器查看使用内存时是看的哪个进程或哪个程序使用了多少内存而不是哪个线程,如果是哪个线程根本不知道是哪个程序里的线程,没法管理。一个进程的内存空间是一套完整的虚拟内存地址空间,这个进程中所有线程都共享这一套地址空间。如下线程的5种状态,只有运行中是占用cpu资源的。
线程执行有性能损耗,这些损耗来自线程的创建销毁和切换,线程本质向cpu申请计算资源,用户态转内核态。
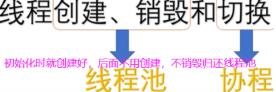
协程是用户自定义线程但与os的线程不同,协程不进入内核态。自己创建一套API,协程利用线程资源。
6.并发:cpu,线程
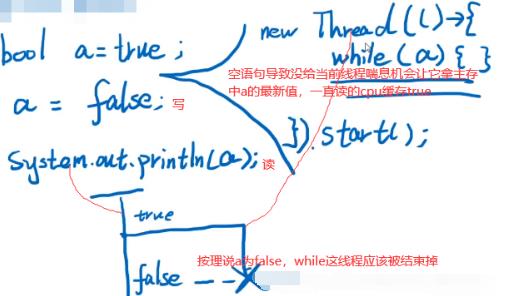
6.1 可见性:volatile
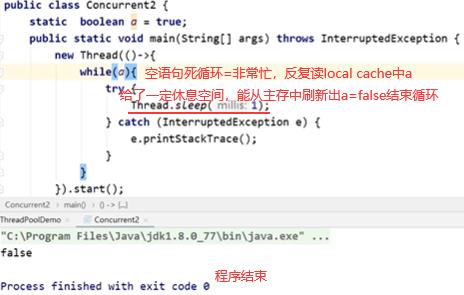
如下程序一直没结束即while(a)这线程没结束:一个线程对a写了false,但是对另一个线程并不可见。
如下第一个core为主线程,第二个core为开辟的线程。
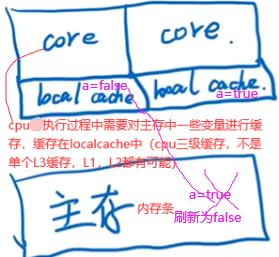
如上线程2不能立即读到线程1写后的最新变量值(线程1写,线程2读),多线程不可见性。如何解决多线程不可见性:加volatile关键字使a在主存和localcache间强制刷新一致。

6.2 原子性(读写原子):AtomicInteger/synchronized
如果线程1和2都进行基于读的变量再对读的变量再进行写,最典型操作i++,T1和T2都进行i++操作。

一开始i=0,经过两个线程两次i++操作结果变成了1,这显然是不对的,并且这种情况下不能用volatile保证这样操作的正确性(两个线程既有读操作,又有基于读操作的写操作,可见性只保证一个线程写另一个线程读是正确的,这里可见性不适用)。
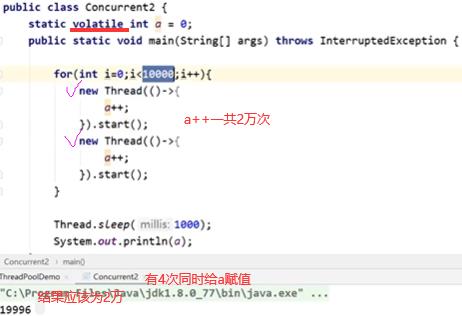
现在想做的是将读操作和写操作合为一步,要么同时发生要么同时不发生(原子性)。在保证原子性同时一定以保证可见性为前提(不是并列关系,AtomicInteger类里本质上就是volatile),本身不可见的话没办法保证原子性。
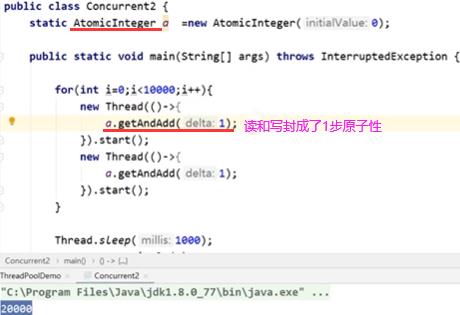
也可用synchronized同步关键字来保证原子性发生,同步关键字同一时间只有一个线程进入代码段。
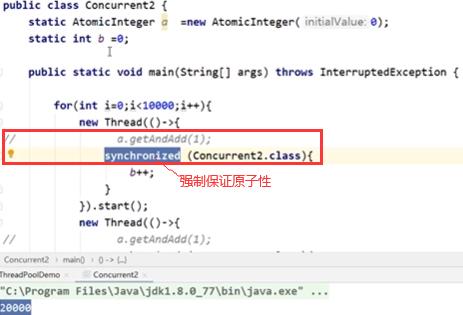
volatile可见性关键字最轻量级(保证一个线程写,一个线程读能读到最新的值),AtomicInteger(保证既有读操作又有写操作如i++这种场景下能保证操作的原子性)基于volatile,synchronized最重量级(能保证整个代码块中所有操作都是原子性的)。多线程情况下需要自增请使用Atomicxxx类来实现。
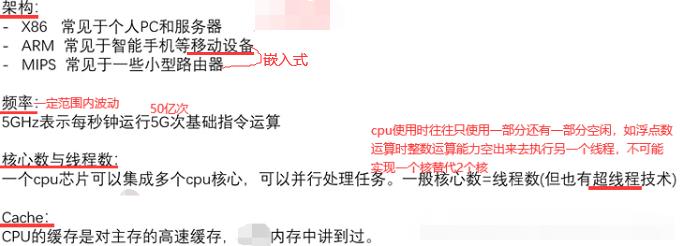
6.3 CPU:由控制器和运算器组成,通过总线与其他设备连接
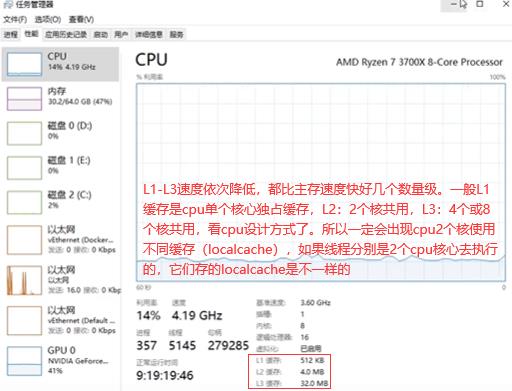
内存,cpu,io是编程中三个最重要的点。南桥(桥就是连接)连接带宽要求低的设备如是一些鼠标键盘硬盘usb设备等。北桥(集成到了cpu内部)负责带宽比较高的设备如pcie显卡,pcie硬盘,内存RAM需高速访问。如下是cpu常见参数,8核16线程(超线程)。
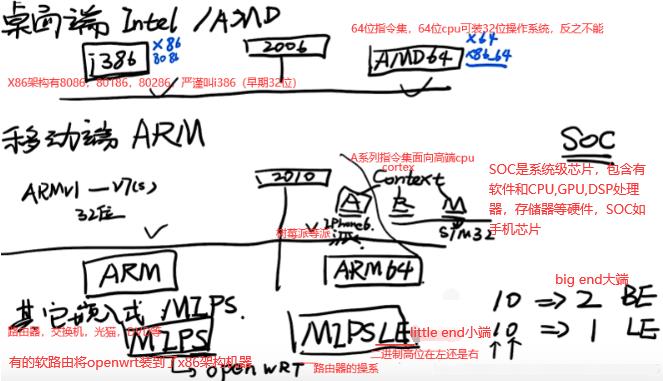
系统架构=处理器指令集,如下常见的6种指令集,X86_64基于X86,ARM不是其他嵌入式类,cortex A系列等。
2个物理cpu,1个物理cpu有38个逻辑核【76个线程/频率/处理单元processor)】。CPU就intel和amd。CPU(S):所有cpu的总逻辑核数。socket:物理cpu数量。top -d 1。

程序一部分在内存中,一部分在SWAP分区(文件系统中,磁盘上)。

6.4 应对并发:cdn
1.动静分离,cdn加速资源。2.水平扩展,nginx集群。3.微服务化,多用多分配资源。4.缓存redis减少io寻找。5.队列,秒杀系统采用。
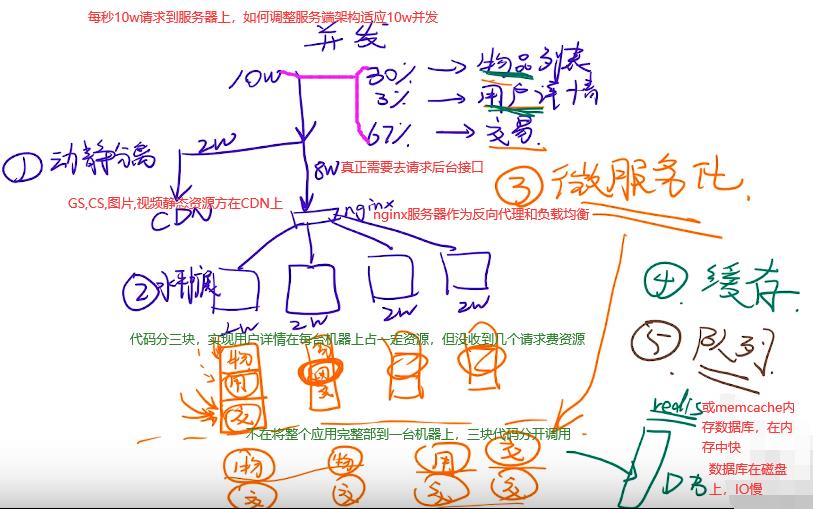
7.IO多路复用:硬盘和网卡
如下A,B。。都是客户端,方框是服务端。首先想到应对并发,写一个多线程程序,每个传上来的请求都是一个线程,现在很多rpc框架用了这种方式,多线程存在弊端:cpu上下文切换,因而多线程不是最好的解决方案,转回单线程。如下while(1)…for…就是单线程。

7.1 select:select是系统调用函数,system是一个C/C++的库函数
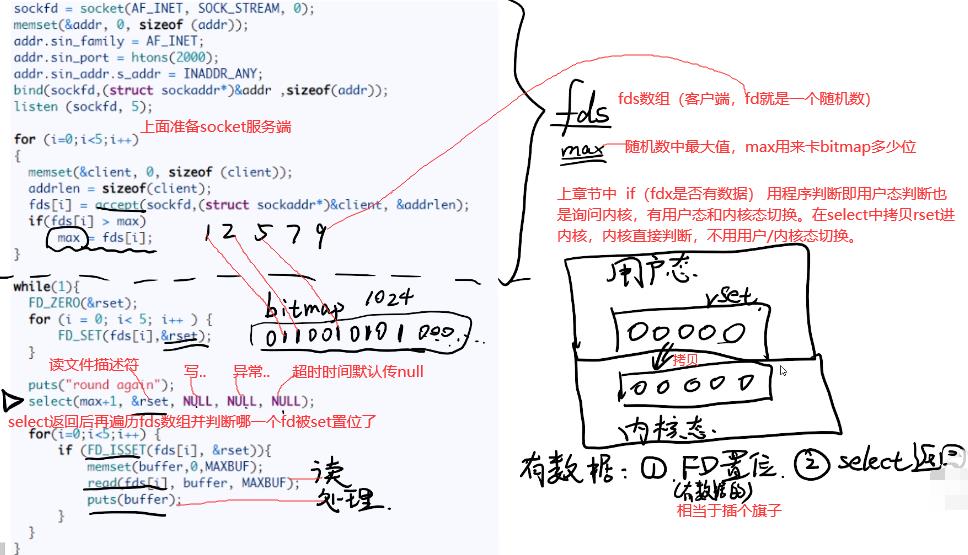
while(1)中FD_ZERO将rset初始化0,用FD_SET将有数据的fd插个旗子,并赋给reset。

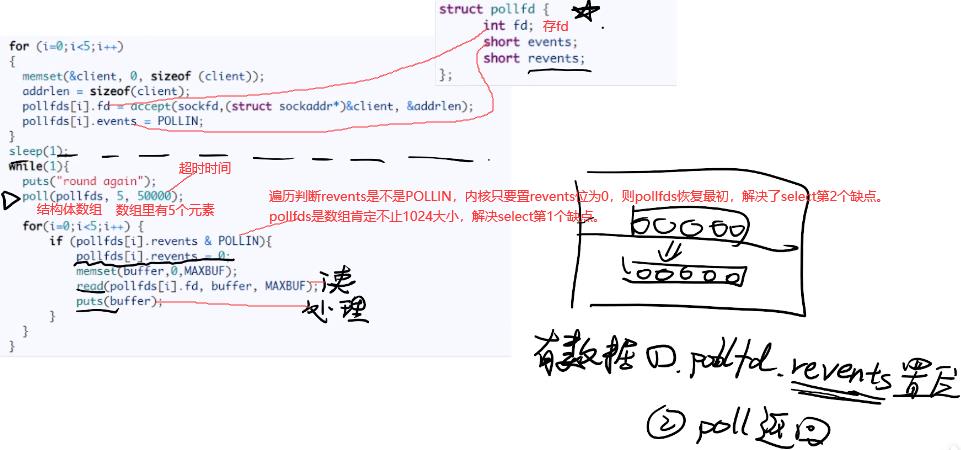
7.2 poll:pollfds数组替代bitmap,阻塞
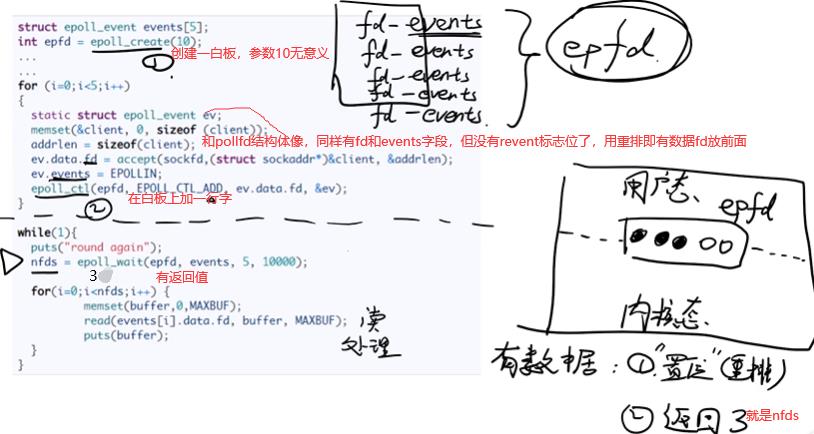
7.3 epoll:epfd是共享内存,不需要用户态切换到内核态
epoll_wait和前面select和poll不一样,有返回值。最后只遍历nfds,不需要轮询,时间复杂度为O(1)。epoll解决select的4个缺点。redis,nginx,javaNIO/AIO都用的是epoll,多路io复用借助了硬件上优势DMA。
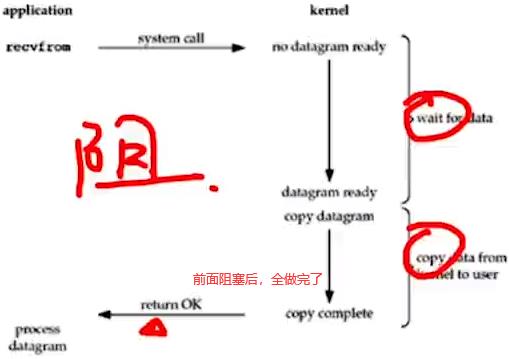
7.4 IO模型:阻塞:发起io读取数据的线程中函数不能返回。同步:拿到io读取完的数据之后,对数据的处理是在接收数据线程的上下文后紧接着处理。异步:回调函数中进行数据处理
如下是BIO,NIO,AIO的说明。
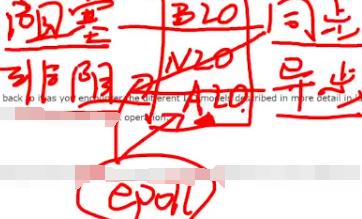
1.blocking I/O(BIO):wait和copy data。
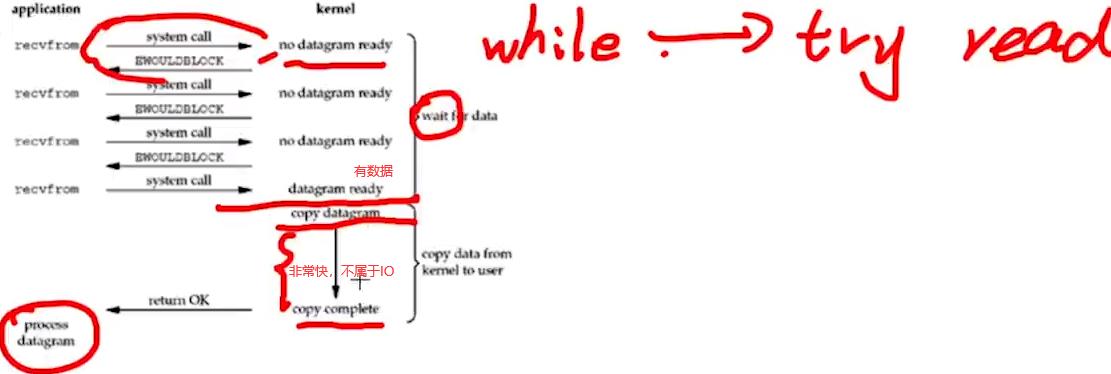
2.nonblocking I/O(NIO):如调用read函数,一调用立马返回。
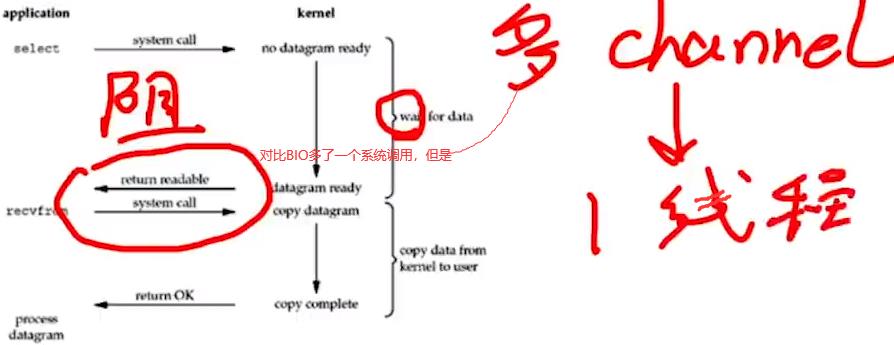
3.I/O多路复用:多路多channel的数据放入一个线程中去处理。
4.信号I/O:kernel即os发送SIGIO给应用层,应用层需编写监听SIGIO中断信号函数进行数据处理。
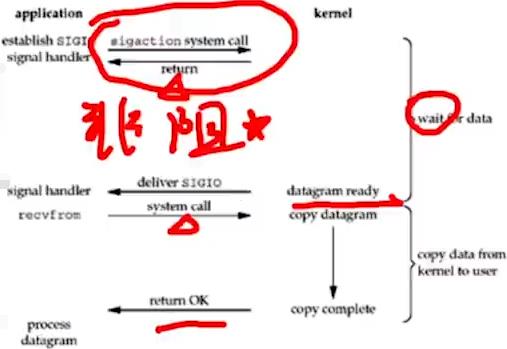
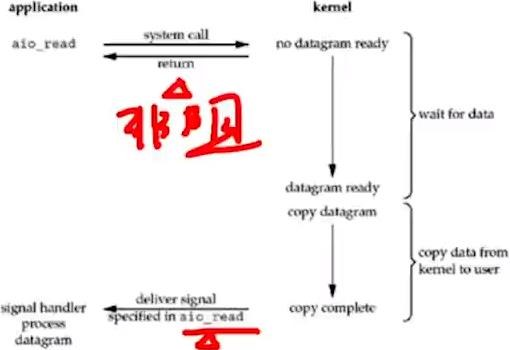
5.asynchronous I/O(AIO):收到aio_read信号后就可在回调函数中处理了。
7.5 硬盘,网口,套接字:du,df,fdisk,lsblk,smarctrl -i, blkid
如下是硬盘(块,扇区,文件管理中inode记录的内容)

如下是网卡。


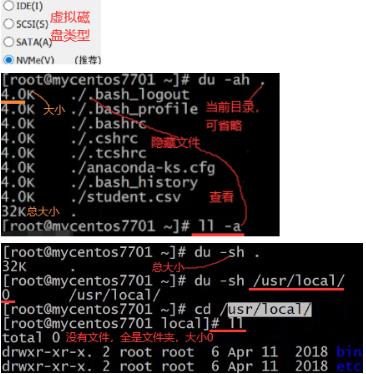
df:如果你想知道某个文件夹或文件大小用du,磁盘相关使用和挂载用df。lsblk和fdisk -l查看分区。blkid查看当前系统用的哪个盘文件系统。如下Type一列是查看文件系统的格式,还有cat /etc/fstab也可以。

fdisk /dev/sda:(d,4)删除sda4分区,(n,4,+408G)新建408G的sda4,(w)保存退出。
mkfs.ext4 /dev/sda4 : 格式化并建文件系统,后面可进行mount挂载,df -h查看。
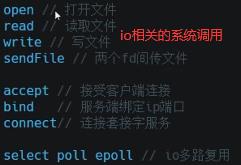
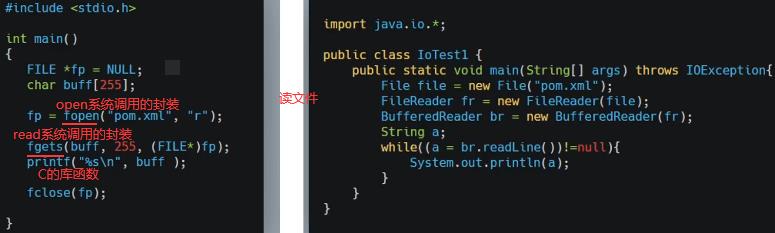

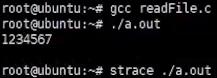
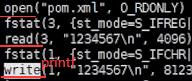
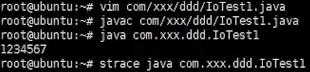
如上看出java比C语言系统调用多的多,因为java要启动jvm虚拟机,jvm要读jdk的lib库等很多操作。如上并没有发现open…xml操作,因为java程序主要启动jvm进程,jvm进程可能又起了很多线程去真正运行main函数,所以加-f。

8.操作系统内存管理与分类:分页,页大小位数=偏移量
8.1 内存条/总线/DMA(硬件):CPU和DMA是同级,两者对总线控制是轮换隔离
io总线 (包括PCIE总线)最常见的USB(通用串行总线)。
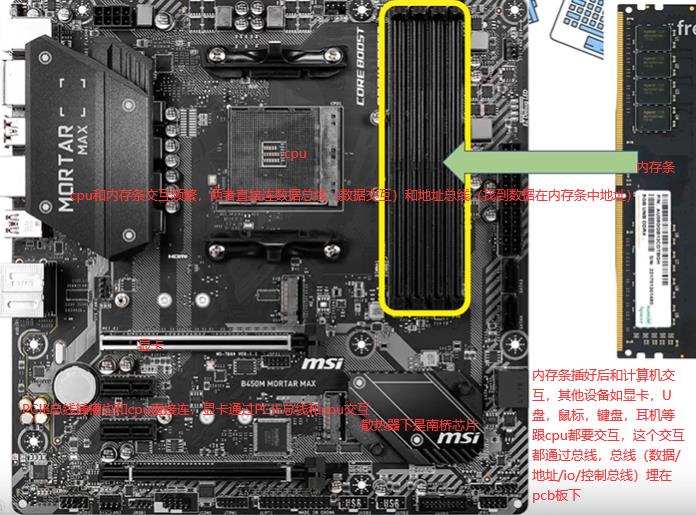
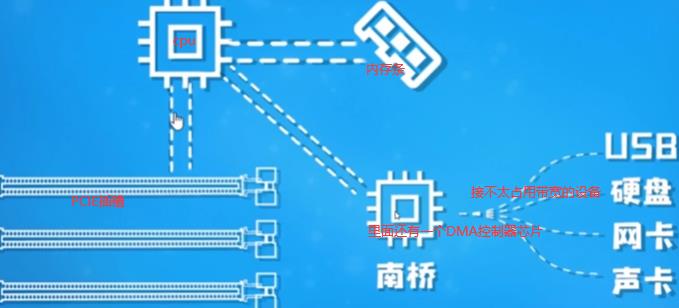
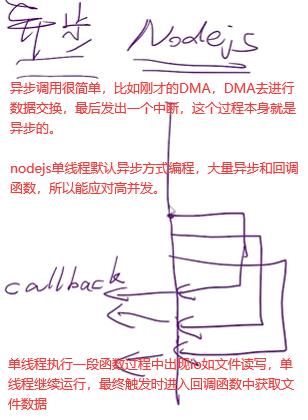
Nodejs是单线程,但在读文件时,文件还没读完却可以执行下面几行程序,文件读完后触发一个回调。因为单线程按理来说cpu直接读磁盘中文件的话,应该一直读取这文件,读完前不能进行其他操作,它怎么做到执行其他操作的呢?需要有硬件支持即DMA,读文件操作是非常机械劳动,cpu资源宝贵不能干这种活,下面xxx是内存地址。

8.2 用户态和内核态:程序运行过程中可能处于内核态,也可能处于用户态,某一时刻处于用户态,下一时刻可能切换到用户态(但必须有触发条件)
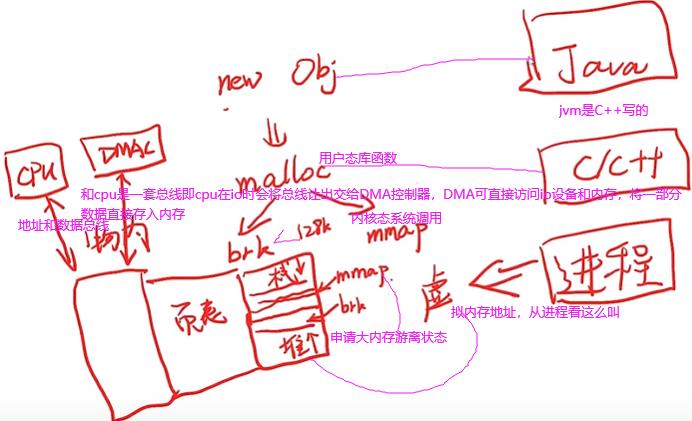
读写文件和申请内存是用户态转内核态的两个例子。malloc的两种实现方式brk和mmap,两者只选一种。brk和mmap申请的都是虚拟内存,不是物理内存,想真拿到物理内存空间还要第一次访问时发现虚拟内存地址未映射到物理内存地址,于是促发一个缺页中断(也叫缺页异常,os中异常和中断有很多类似地方)。C语言是malloc,而java和c++中new对象申请内存空间,也是经过这么过程。
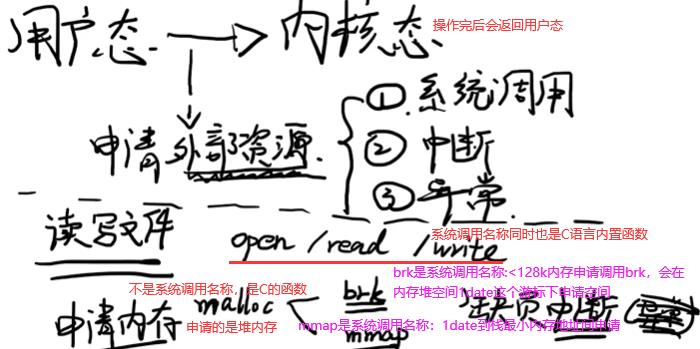
查看linux内核中有多少系统调用:man syscalls如下。第四类信息相关,如获取cpu信息等。管道pipe是进程间通信。open,read,write是文件相关,同时也是对磁盘操作,也可归到设备这类。mmap是文件和内存的映射,mmap申请内存也是对磁盘设备操作,也可属于第三类。

逻辑地址(逻辑/虚拟/进程内存):程序自身看到的内存地址
以上是关于Note1网络,并发/IO,内存,linux/vi命令,正则,Hash,iNode,文件查找与读取,linux启动/构建的主要内容,如果未能解决你的问题,请参考以下文章