中科院NLPIR中文分词java版
Posted 起个名字好难
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中科院NLPIR中文分词java版相关的知识,希望对你有一定的参考价值。
原文:http://blog.csdn.net/k21325/article/details/53052855
摘要:为解决中文搜索的问题,最开始使用PHP版开源的SCWS,但是处理人名和地名时,会出现截断人名地名出现错误。开始使用NLPIR分词,在分词准确性上效果要比SCWS好。本文介绍如何在windows系统下编译Java ,生成可以执行的jar文件。

NLPIR的下载地址:
http://ictclas.nlpir.org/downloads
GitHub的地址:
https://github.com/NLPIR-team/NLPIR
两个版本有一些不同,本文将分别讲解如何利用Eclipse建立工程。
一、NLPIR官方版本
下载后文件夹中bin目录,如下图所示,其中NLPIR_WinDemo.exe是一个NLPIR的演示程序,可以尝试运行,了解NLPIR的功能。
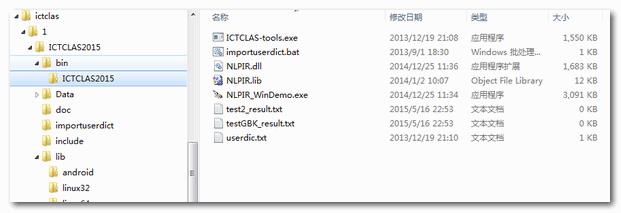
工程源码在sample目录下,包含C、C++、Hadoop、JAVA、Python等语言示例。
用Eclipse新建一个工程导入JAVA工程目录JnaTest_NLPIR,
(1)Eclipse -> File->import
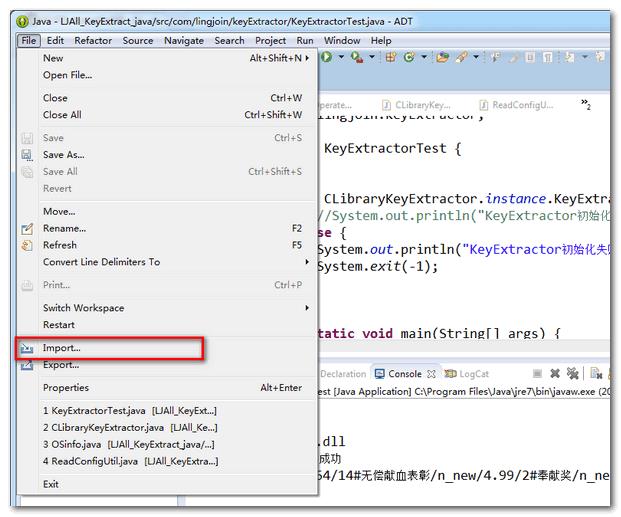
(2)选择JnaTest_NLPIR所在的路径,点击Finish
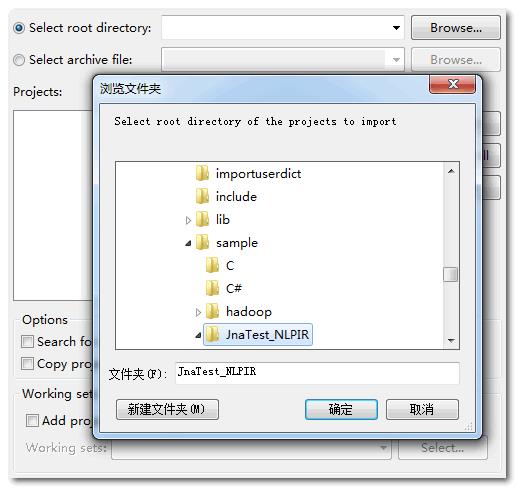
(3)查看Eclipse工程
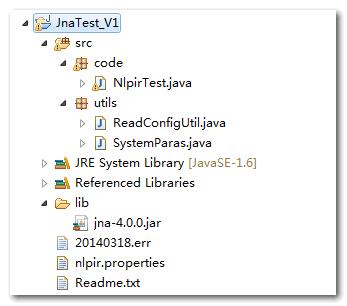
(4)NlpirTest.java文件中包含main函数,下面的语句初始化NLPIR需要的库文件
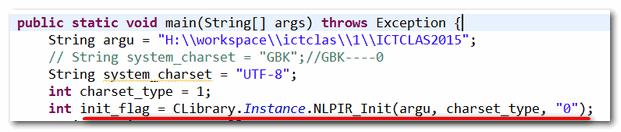
CLibrery类是包含在NlpirTest.java文件中,
- CLibrary Instance = (CLibrary) Native.loadLibrary("H:\\\\workspace\\\\ictclas\\\\1\\\\ICTCLAS2015\\\\lib\\\\win64\\\\NLPIR", CLibrary.class);
函数loadLibrary需要传递库文件位置,源码提供了多种语言类库,我们的工程需要加载win64类库,该文件夹内容如下,
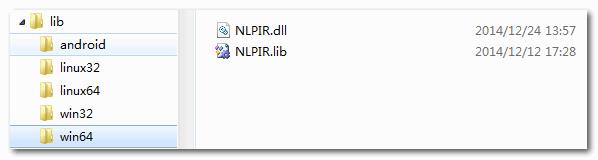
(5)加载分词数据Data文件夹路径
- String argu = "H:\\\\workspace\\\\ictclas\\\\1\\\\ICTCLAS2015";
- String system_charset = "UTF-8";
- int charset_type = 1;
- int init_flag = CLibrary.Instance.NLPIR_Init(argu, charset_type, "0");
H:\\\\workspace\\\\ictclas\\\\1\\\\ICTCLAS2015是Data文件夹的父文件夹。
这步骤完成后,你就可以调试代码了。有关API可以阅读手册。
二、github上下载的代码
目录中包含了NLPIR SDK目录,每一个目录是NLPIR提供的一个组件。NLPIR-ICTCLAS目录包含NLPIR组件的代码。
在Eclipse中导入ICTCLAS_java工程,工程目录如下图
工程中没有填写main函数,可以在NlpirTest.java文件中,加入main函数
- public class NlpirTest {
- public static void main(String[] args) throws Exception{
- NlpirTest t = new NlpirTest();
- t.testParticiple();
- }
- public void testParticiple() throws IOException {
- .....
- }
- .......
- }
和官方网站不同,加载库文件可以自动判断系统类型,在工程当前目录下查找库文件。“工程当前目录”的win32、win64、linux32、linux64都是包含库文件的文件夹。
同时会自动加载“工程当前目录“下Data问佳佳为分词数据目录。这些目录设置好,就可以进行调试工作了。
三、在github中"查找关键字"的组件Key_Extract
工程目录如下,
project中提供java版本的示例代码,利用Eclipse导入工程
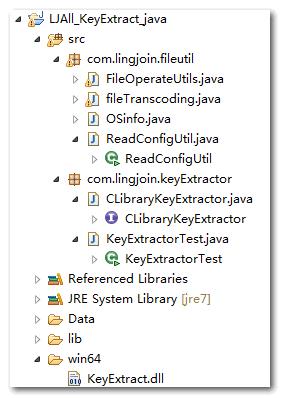
同样在KeyExtractor.java文件中添加main函数。KeyExtract_GetKeyWords的第一个参数是需要提取关键字的文本,第二参数是关键字的个数。
在工程的当前文件夹下,有一个Data目录,是分词和提取关键词需要用到的分词数据。需要将需要的license考入到这个文件夹。你可以不用区分用到哪一个user文件,建议把全部文件都考到当前工程目录Data文件夹中。
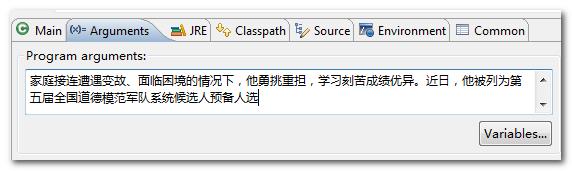
这些设置完成,在Eclipse中传入参数,菜单项run-->run configure。
四、导出jar
Eclipse工程目录上,右键选择Export
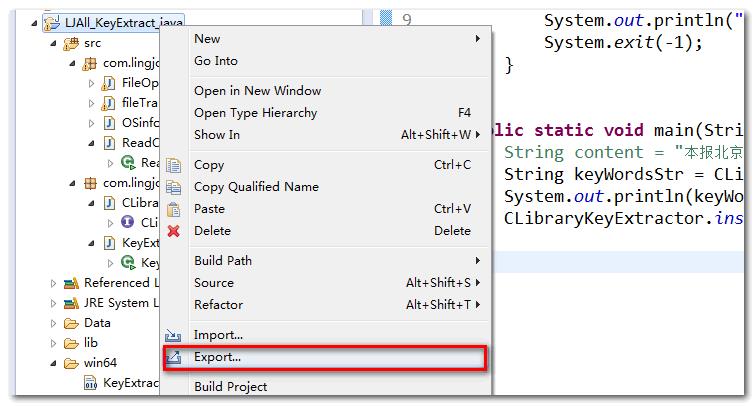
选择runnablejar,生成jar文件
之后就可以利用cmd执行,传递参数,效果如下

以上是关于中科院NLPIR中文分词java版的主要内容,如果未能解决你的问题,请参考以下文章