双全估计算均值和方差——理论与 Python 实现
Posted zhuo木鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了双全估计算均值和方差——理论与 Python 实现相关的知识,希望对你有一定的参考价值。
文章目录
本文主要参考标准:16269-4:2010 的 5.2.3 条款和 5.3.3 条款
设样本为 x 1 , x 2 , ⋯ , x n x_1, x_2, \\cdots, x_n x1,x2,⋯,xn。
均值估计(location estimate)
步骤
双权(biweight)均值估计主要用在样本采样与一个不对称分布,并存在离群值的情景。他是通过迭代方法求解均值的,迭代过程如下:
T
n
=
∑
∣
u
i
∣
<
1
x
i
(
1
−
u
i
2
)
2
∑
∣
u
i
∣
<
1
(
1
−
u
i
2
)
2
T_n = \\frac\\sum_|u_i | < 1 x_i (1 - u_i^2)^2 \\sum_|u_i| < 1 (1-u_i^2)^2
Tn=∑∣ui∣<1(1−ui2)2∑∣ui∣<1xi(1−ui2)2
其中:
u
i
=
x
i
−
T
n
c
⋅
M
a
d
u_i = \\fracx_i - T_n c \\cdot M_ad
ui=c⋅Madxi−Tn
其中
M
a
d
=
median
(
∣
x
i
−
median
(
x
)
∣
)
M_ad= \\textmedian (|x_i - \\textmedian(x)|)
Mad=median(∣xi−median(x)∣)。
T
n
T_n
Tn 的初始值可以取为样本中位数。迭代停止的条件是:
T
n
T_n
Tn 和
T
n
+
1
T_n+1
Tn+1 基本不变为止。此时
T
n
T_n
Tn 就是稳健均值。
注:系数 c c c 一般取为 6。意味着样本的总体为正态分布时,那些落在 median ( x ) ± 4 × σ \\textmedian(x) \\pm 4\\times \\sigma median(x)±4×σ 之外的点,参与计算 T n T_n Tn 是,其权重为 0 。 σ \\sigma σ 为标准差。
Python 实现
def perform_beweight_location_estimate(x, c=6, epochs=100):
if isinstance(x, pd.Series):
x = x.astype('float').values
x_med = np.median(x)
T_last = x_med
epoch = 1
while True:
mad = np.median(np.abs(x-x_med))
u_arr = (x-T_last)/(c*mad)
idx = np.abs(u_arr) < 1
coeff = (1-u_arr[idx]**2)**2
Tn = sum(x[idx]*coeff)/sum(coeff)
T_curr = Tn
if np.abs(T_curr - T_last) <= 1e-5:
return T_curr
epoch = epoch + 1
if epoch >= epochs:
print('迭代达到最大步数,自动停止')
return T_curr
T_last = T_curr
方差估计(scale estimate)
首先给出 beweight 估计的修正系数
s
b
i
s_bi
sbi 与样本容量 n 的表格如下(来源 16269-4 的表格 D.1):
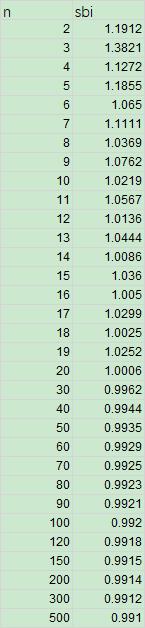
步骤
根据 beweight scale estimate 算法,只需要一步到位计算即可:
S
b
i
=
s
b
i
×
n
n
−
1
∑
∣
u
i
∣
<
1
(
x
i
−
M
)
2
(
1
−
u
i
2
)
2
∣
∑
∣
u
i
∣
<
1
(
1
−
u
i
2
)
(
1
−
5
u
i
2
)
∣
S_bi = s_bi \\times \\fracn\\sqrtn-1 \\frac\\sqrt\\sum_|u_i|<1 (x_i - M)^2 (1-u_i^2)^2 |\\sum_|u_i| < 1 (1-u_i^2)(1-5u_i^2) |
Sbi=sbi×n−1n∣∑∣ui∣<1(1−ui2)(1−5ui2)∣∑∣ui∣<1(xi−M)2(1−ui2)2
其中 M 为样本中位数,
u
i
u_i
ui 的计算公式同上。此时常熟
c
c
c 一般取 9,意味着样本来源为正态分布时,那些落在
M
±
6
×
σ
M\\pm6 \\times \\sigma
M±6×σ 的点,在计算
S
b
i
S_bi
Sbi 时的权重为 0 。
Python 代码
将 s b i s_bi sbi 的系数表格存储在一个与 Python 代码在同一文件夹中的 excel 表格,取名为 correction_factors.xlsx:
def perform_beweight_scale_estimate(x, c=9):
if isinstance(x, pd.Series):
x = x.astype('float').values
x_med = np.median(x)
mad = np.median(np.abs(x-x_med))
u_arr = (x-x_med)/(c*mad)
# 样本数量
n = len(x)
path = r'./correction_factors.xlsx'
factor_data = pd.read_excel(path, header=0)
n_list = factor_data['n']
if n not in n_list:
if n <= 150:
n_list_interpolate = np.arange(2, 151)
sbi_list = factor_data['sbi'].values
f = interpolate.interp1d(n_list, sbi_list, kind='cubic')
sbi_list = f(n_list_interpolate)
sbi = sbi_list[n-2]
elif 150 < n and n <= 200:
sbi = 0.9914
elif 200 < n and n<=300:
sbi = 0.9912
else:
sbi = 0.9910
else:
sbi = factor_data.loc[factor_data['n']==n]['sbi']
sbi = float(sbi)
idx = np.abs(u_arr) < 1
numerator = np.sqrt(sum((x[idx]-x_med)**2*(1-u_arr[idx]**2)**4))
denominator = np.abs(sum((1-u_arr[id以上是关于双全估计算均值和方差——理论与 Python 实现的主要内容,如果未能解决你的问题,请参考以下文章