论文笔记:Deep Learning for Anomaly Detection inTime-Series Data: Review, Analysis,and Guidelines
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记:Deep Learning for Anomaly Detection inTime-Series Data: Review, Analysis,and Guidelines相关的知识,希望对你有一定的参考价值。
2021 的paper
1 时间序列数据异常的定义
- 离群值(outlier):与其他观察结果偏差过大,以至于怀疑它是由不同机制产生的
- 时间序列的异常值:某一个/些时间片的数值值,展现出与先前时间步长显着不同的意外行为。
根据之前的文献,作者将时间序列异常分成了以下三类:
1.1 点异常(point anomaly)
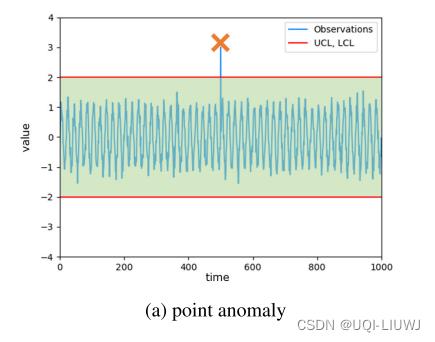
- 突然偏离常态的数据点或序列
- 通常是由传感器错误或异常系统操作引起的。
- 检测点异常,在传统上根据先前数据设置控制上限和下限,通常分别称为 UCL 和 LCL。 存在于这些限制之外的值被视为点异常。
1.2 内容异常 (contextual anomaly)

- 在预定义的 UCL 和 LCL 范围内。 然而,考虑到给定的上下文,数据点超出了预期的模式或形状。
- 这些异常相对来说可能难以检测。
1.3 累积异常(collective anomaly)
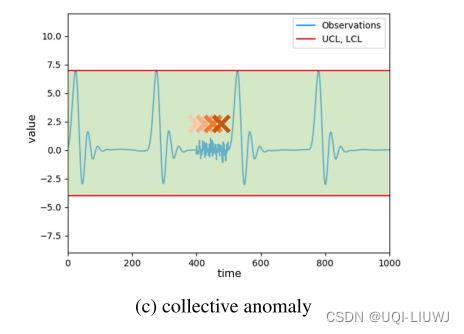
- 指一组数据点应该被视为异常,因为它们随着时间的推移逐渐显示出与正常数据不同的模式
- 这种异常中的每一个时刻的观测可能看起来没有问题,但总的来说,它们会引起怀疑。
- 由于它们不容易立即识别,因此长期的上下文对于检测它们特别重要。
1.4 其他的异常
取决于在不同的问题和环境下,什么是normal

2 时间序列的特征
如果充分理解时间序列数据的特征,则可以利用信号中的上下文信息有效地检测异常
2.1 时序特征
每个连续观察之间存在时间相关性或依赖性。

2.2 维度
- univariate:只考虑当前状态和之前状态之间的关系(比如时间依赖关系)
- multivariate:时间依赖关系和各个变量之间的关联性都需要被考虑
2.3 非平稳性(nonstationarity)
- 如果一个时间序列的统计属性不随时间变化,那么称这个时间序列是平稳的。即

- 其中Fx是联合概率分布
-
理想情况下,我们需要一个平稳的时间序列来建模,但许多所需的属性在现实场景中并不满足。 季节性、概念漂移和变化点等易变特征使时间序列数据变得不稳定。
- 由于大多数时间序列数据是非平稳的,因此在某些时刻指示虚假异常的数据点在更大范围内可能并不是真正的异常。
- ——> 因此,好的检测方法需要适应数据结构变化。
2.4 噪声
- 在许多情况下,噪声是由传感器灵敏度的微小波动引起的,并且对整体数据结构基本上没有影响。
- 然而,当噪声系统中的噪声和异常难以分离时,噪声会严重影响检测模型的性能。
- 因此,了解噪声的性质并在预处理阶段降低噪声至关重要。
3 工业界应用
略
4 传统方法及挑战
4.1 传统方法
4.1.1 傅里叶变化
数学笔记;离散傅里叶变化 DFT_UQI-LIUWJ的博客-CSDN博客4
4.1.2 统计模型
- 通过计算均值、方差、中位数、分位数、峰度、偏度等统计指标来生成统计模型。
- 使用生成的模型,可以检查新添加的时间序列数据,判断其是否属于正常边界
4.1.3 基于距离的模型
- 基于预先定义的相似函数,计算需要检测的时间序列和normal时间序列之间的相似程度
- 如果他们之间的距离大于期望的范围,那么人为时间序列异常

- DTW 笔记: Dynamic Time Warping 动态时间规整 (&DTW的python实现)_UQI-LIUWJ的博客-CSDN博客
4.1.4 预测模型
- 基于过去和现在的状态,预测未来的状态
- 根据预测值和真实值的差距,判断是否有异常的情况
- 算法笔记:ARIMA_UQI-LIUWJ的博客-CSDN博客
4.1.5 聚类模型
- 在无监督环境中,基于聚类的方法是对数据进行分组和检测异常的简单而有效的选择。
- 一旦将时间序列数据映射到多维空间,聚类算法就会根据它们的相似性将它们分组到每个聚类的质心附近。
- 如果新接收的数据样本远离预定义的聚类或属于任何聚类的概率很低,则模型会将它们分类为异常。
4.2 传统方法的挑战
4.2.1 label数量不足
- 异常数据过少
- 正常数据和异常数据之间的类不平衡也会阻碍模型训练
4.2.2 数据的复杂性
- 很多univariate的方法没有考虑变量之间的关系,因而在multivariate的场景中效果不好
5 深度学习方法

5.1 假设条件
- 半监督/无监督学习
- 对于半监督学习,所有数据都被认为属于正常类
- 在无监督学习中,没有考虑正常类和异常类之间的明确区分。
- 两种策略都通过学习数据结构以克服标记数据的不足。
- multivariate time series
5.2 变量之间的关系
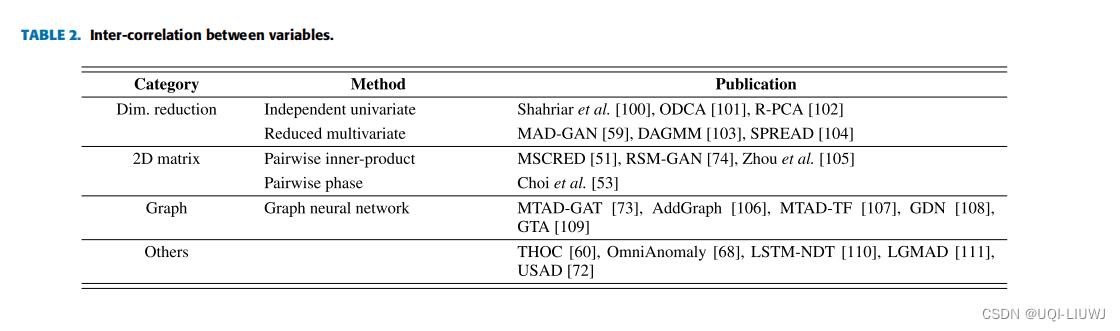
5.2.1 2D矩阵
- 二维矩阵直接捕获各个变量之间的形态相似性和相对比例。
- 两种2D矩阵
 表示:
表示:
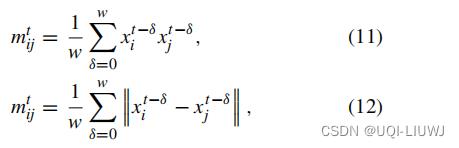
- 如果各个变量的相位由于意外事件突然上升或下降,(11)可以检测到异常,但(12)不能。(乘积变大了)
- 另一方面,当整体阶段因概念漂移或变化点而发生变化时,(12) 将此事件视为正常情况,而 (11) 会标记不必要的警报。(差值不变)
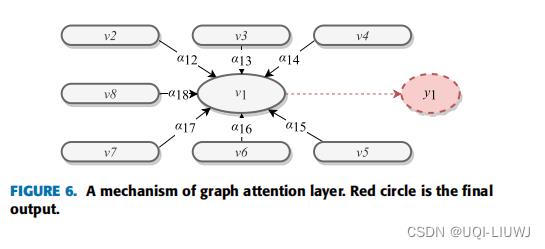
5.2.2 图
- 图可以定义明确的拓扑关系并学习各个变量间的因果关系
- 给定一个图,一种计算各个点的经过attention layer 的输出表征是:

- yu是输出表征
- σ是sigmoid激活函数
- aij是注意力权重
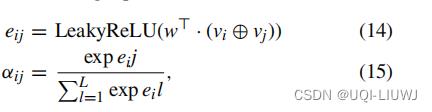
 这里是concatenate的意思
这里是concatenate的意思
- vj是点j的特征向量
5.3 建模时间维度的内容
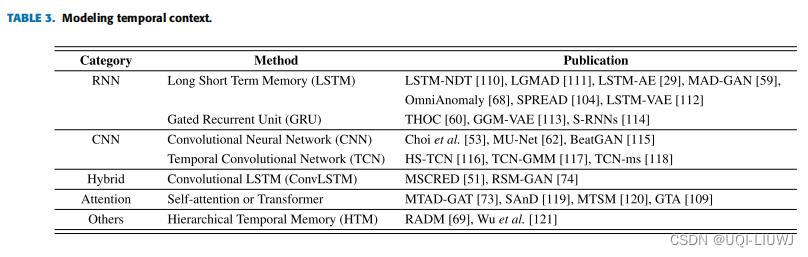
5.3.1 RNN
- LSTM和GRU在一定程度上可以缓解梯度爆炸和梯度消失
- dilated RNN可以提取多尺度的特征
- 基于 RNN 的方法通常以两种方式用于异常检测。
- 一种是预测未来值并将它们与预定义的阈值或观察值进行比较。
- 另一种是构建AE或VAE来恢复观察值并评估重建值与观察值之间的差异。

5.3.2 CNN
- CNN的好处是可以并行,坏处是如果需要学习一个很长的时间序列的特征,需要堆叠很多层
5.3.3 混合
- 每一个时间步是不同变量之间的correlation
- ——>使用Conv-LSTM机器学习笔记 :LSTM 变体 (conv-LSTM、Peephole LSTM、 coupled LSTM、conv-GRU,TPA-LSTM)_lstm变体_UQI-LIUWJ的博客-CSDN博客
5.3.4 attention
5.4 异常的指标
- 上述模型通过最小化定义的目标(损失)函数,以无监督或半监督的方式学习给定数据的表示。
- 目标因模型架构而异,通常与异常的决策标准有关。
- 模型经过训练后,将应用于异常检测。
- 通常,检测结果以数字表示以帮助理解给定状态。
- 这个数字指标称为为异常分数。
- 越大,状态越有可能不正常。
- 具体来说,当分数超过某个阈值时,对应的数据点被判定为异常。
- 一些模型采用自适应阈值,随着时间的推移不断调整数据的变化。
- 用于导出异常分数的方案可以分为三种类型:重构误差、预测误差和相异性。
5.4.1 重构误差
- 通常,AE、VAE、GAN 和 Transformers 使用重构误差作为异常分数。
- 基于 AE 的模型通过提取特征来重建输入数据。
- 基于 VAE 的模型 估计数据分布并从中生成样本,这些样本与输入数据非常相似。
- 基于 GAN 的模型使用生成器显式生成与输入数据尽可能相似的样本,
- 尽管这些模型使用不同的训练方案和目标函数,但它们计算异常分数的方式相似。 它们重建或生成类似于输入数据的数据,并测量输入数据和生成数据之间的残差。
5.4.2 预测误差
- 有两种方法可以从预测模型中得出异常分数。
- 根据数据点被分类为正常的概率应用二进制标签。
- 预测误差表明预期的标签是否与基本事实相匹配。
- 另一种方法是预测下一个时间步长的预期值
- 在这种情况下,预测误差是期望值和观察值之间的残差。
- 根据数据点被分类为正常的概率应用二进制标签。
- 第二个比第一个更实用,因为现实世界中的标签不足。 5
5.4.3 相异性
- 基于差异的方法衡量模型得出的值与累积数据的分布或cluster之间存在多远。
- 相似度的度量方法有很多种,如欧氏距离、明可夫斯基距离、余弦相似度、马氏距离等。
以上是关于论文笔记:Deep Learning for Anomaly Detection inTime-Series Data: Review, Analysis,and Guidelines的主要内容,如果未能解决你的问题,请参考以下文章