H264编码原理之帧间预测与帧内预测
Posted 贺二公子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了H264编码原理之帧间预测与帧内预测相关的知识,希望对你有一定的参考价值。
原文地址:https://www.jianshu.com/p/12a707cf0d3c
文章目录
H264基本概念
视频的本质就是很多帧图片,在视频采集过程中其实就是图片采集,而h264编码就是对这些图片进行压缩,以便于存储和传输。针对一帧帧的图片,引申出以下的概念:
I帧
关键帧,采用帧内压缩技术
举个例子,如果你用摄像头对着一棵树来拍摄,1秒之内,实际你发生的变化是非常少的。1秒钟之内实际很少有大幅度的变化.摄像机一般一秒钟会抓取几十帧的数据。动画一般都是15帧/s,平时我们的视频文件一般也就是30帧/s,对于一些要求比较高的,对动作的精细度有要求,想要捕捉到完整的动作的,高级的摄像机一般是60帧/s。I帧一般都是一组帧的第一帧,I帧需要完整的保存下来,如果没有这个关键帧后面解码数据,是完成不了的.所以I帧特别关键.。
P帧
向前参考帧.压缩时只参考前一个帧.属于帧间压缩技术
视频的第一帧会被作为关键帧完整保存下来.而后面的帧会向前依赖.也就是第二帧依赖于第一个帧.后面所有的帧只存储于前一帧的差异.这样就能将数据大大的减少.从而达到一个高压缩率的效果.
B帧
双向参考帧,压缩时即参考前一帧也参考后一帧.帧间压缩技术.
B帧,即参考前一帧,也参考后一帧.这样就使得它的压缩率更高.存储的数据量更小.如果B帧的数量越多,你的压缩率就越高.这是B帧的优点,但是B帧最大的缺点是,如果是实时互动的直播,那时与B帧就要参考后面的帧才能解码,那在网络中就要等待后面的帧传输过来.这就与网络有关了.如果网络状态很好的话,解码会比较快,如果网络不好时解码会稍微慢一些.丢包时还需要重传.对实时互动的直播,一般不会使用B帧。(如果我们对实时性的要求不高的话,就可以使用B帧,单对于一些实时性要求比较高的直播来说,B帧可以完全不用的)。
GOF(Group of Frame)一组帧
如果在一秒钟内,有30帧.这30帧可以画成一组.如果摄像机或者镜头它一分钟之内它都没有发生大的变化.那也可以把这一分钟内所有的帧画做一组.
一组帧:
一个I帧到下一个I帧.这一组的数据.包括B帧/P帧.我们称为GOF(如下图)
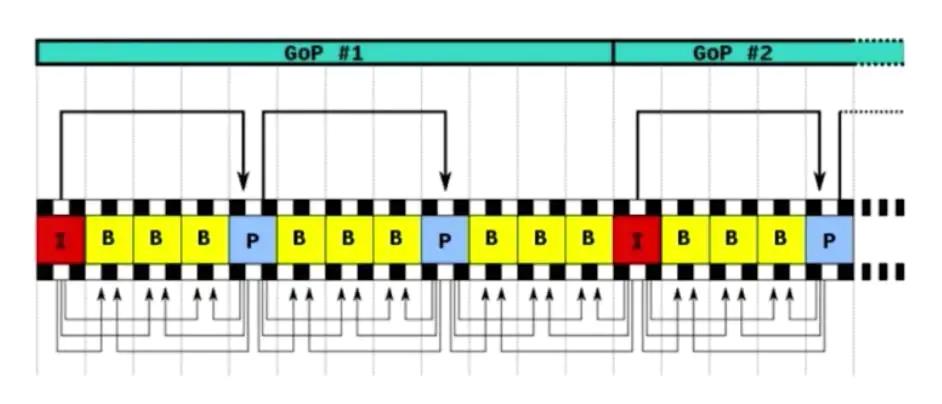
补充:
简单分析一下我们在平时看视频时候会发现花屏或者卡顿的现象,主要是一组帧(GOF)里面的P帧缺失或者受损让解码时候发生错误导致的。为了避免花屏的发生,一般会不显示发生P帧或者I帧丢失的那一组帧,等到下一个I帧到来时才显示下一组帧,然而这样子治标不治本,长时间显示上一组帧,会导致卡顿现象的发生。
帧内预测压缩
帧内预测压缩,解决的是空域数据冗余问题,一幅图里数据在宽高空间内包含了很多颜色,光亮.人的肉眼很难察觉的数据. 对于这些数据,我们可以认作冗余.直接压缩掉的。
帧间预测压缩
解决的是时域数据冗余问题,摄像头在一段时间内所捕捉的数据没有较大的变化,我们针对这一时间内的相同的数据压缩掉.这叫时域数据压缩。
其他
(除以上之外还有CABAC无损压缩与整数离散余弦变换(DCT)
在分析帧内预测与帧间预测之前我们还需知道宏块划分与分组
H264宏块划分:

将一个图片左上角用宏块描述,就是宏块是8*8的元素.取出的颜色,像右边的去描述.描述颜色.将一个图片全部用宏块描述就如下图。

基本上宏块划分就完成了,那么宏块还可以在细分吗?当然是可以的,宏块可以进行子块的划分,如下图:

在这个大的宏块里,可以再细化. 我们可以看到在这个大的宏块里,我们更加细化了. 比如我们中间这个全部都是蓝色的这个宏块,就可以用一个色块,更加简单描述就行了。
由上图可以看出,MPEG2和H.264.就会发现MPEG2存储时还算比较完整.占用的空间相对于比较多.而H.264还是减少了很多空间.像重复的颜色他们就用非常简单的色块描述了。
帧间预测压缩分析
现在我们有一组帧(如下图),记录的是桌球在桌球台上的运动,好明显这一组帧的背景就是桌球台,这是不变的,改变的就是桌球的位置,这就是帧分组。

然后进行组内宏块的查找(如下图),台球从一角滚到另外一角.相邻的2幅图做组内的宏块查找。将图逐行扫描,扫描到第三行.发现了台球. 然后围绕它的周围查找.发现了有类似的图块。

以上操作找到了对应的宏块,然后就会进行运动估算。然后把他们放在同一张图上面(如下图),而在两个位置之间就会存在着一个运动矢量。矢量会包含运动的方向和距离。以此类推,我们将所有的图进行两两比较的话,就会得出第一张图+很多帧的运动矢量,数据就达到了很大的减少。

你以为这样子就结束了嘛?其不然!虽然说每张图的背景都一样的,其实还是存在着一些差别的。好明显就是台球的数据,有些我们肉眼看不清的数据,例如光线的影响。所以帧间预测过程中还会对每帧图进行残差数据的计算,实际经过我们一运算后.它留下的就只是运动矢量数据+残差值的数据。经过这样的一个计算.帧间压缩数据我们就可以看到实际我们只需要存储一点点数据.而不像以前要将几十帧的所有图片数据保存下来.这就达到了压缩的效果,这个过程就叫做帧间压缩技术的原理。

帧内预测压缩分析
帧内预测压缩在平时开发中使用较多,帧内压缩是针对于I帧的。因为它解决的是空间的数据冗余,而帧间压缩是解决的时间数据冗余。我们刚刚说明的是帧间压缩技术,将大量在时间轨迹上相同的数据压缩掉,只留下运算估量和残差值。
而帧内压缩用到了完全不同的技术手段,我们首先计算出每个宏块的宏块模式,一共9种。如图所示:


参考文献:帧内预测9种模式原理介绍
经过计算最后得到的数据是每个宏块预测得出宏块的模式数据,如图所示:

在每个宏块模式确定之后呢,就可以形成一张“预测图”,左边是预测图,右边是源图。

得到的“预测图”与原图比较起来还是显得比较粗糙的,然后两者进行残差数据的计算,得到残差值。如图:

低下的就是源于,灰色图就是残差值。
预测模式与残差值压缩:
拿到残差值之后,我们就进行压缩. 压缩时保存,残差数据和每个宏块选择的模式信息数据. 那么有了这2个数据之后.当我们解码时,首先通过宏块的模式信息计算出预测图.然后将预测图与我们的残差值进行累积.就能还原成原图像. 那这个过程就是"帧内压缩技术"的原理过程。

以上是关于H264编码原理之帧间预测与帧内预测的主要内容,如果未能解决你的问题,请参考以下文章