YOLOv7实验记录
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLOv7实验记录相关的知识,希望对你有一定的参考价值。
这篇博客主要记录博主在做YOLOv7模型训练与测试过程中遇到的一些问题。
首先我们需要明确YOLO模型权重文件与模型文件的使用
其实在github的readme中已经告诉我们使用方法,但我相信有很多像博主一样眼高手低的人可能会犯类似的错误。
训练
首先是训练时的设置:
这里的训练指的是从头开始训练,即不使用任何权重文件。
官方给出的命令如下:可以看到此时其只是使用了模型的配置文件(cfg参数所指定的),而权重文件(weights所指定的)为空,此时训练时对服务器的配置要求高。
python train.py --workers 8 --device 0 --batch-size 32 --data data/coco.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml
迁移学习
迁移学习指的是我们使用官方给出的预训练模型,我们可以在这个基础上进行微调,相较于从头训练,其配置要求相对低。
使用的权重文件:

官方给出的命令:
可以看到此时我们使用的预训练模型为yolov7_training.pt
python train.py --workers 8 --device 0 --batch-size 32 --data data/custom.yaml --img 640 640 --cfg cfg/training/yolov7-custom.yaml --weights 'yolov7_training.pt' --name yolov7-custom --hyp data/hyp.scratch.custom.yaml
yolov7_training.pt
测试
测试指的是我们使用官方提供好的测试权重文件来进行对我们的数据进行测试。
使用的权重文件:
下载地址:
https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7.pt
python test.py --data data/coco.yaml --img 640 --batch 32 --conf 0.001 --iou 0.65 --device 0 --weights yolov7.pt --name yolov7_640_val
推理
在视频中:
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source yourvideo.mp4
在图像上:
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/horses.jpg
epoch太小问题
实验中设置epoch为300,batch-size=16,但运行完成后发现模型还有优化的趋势
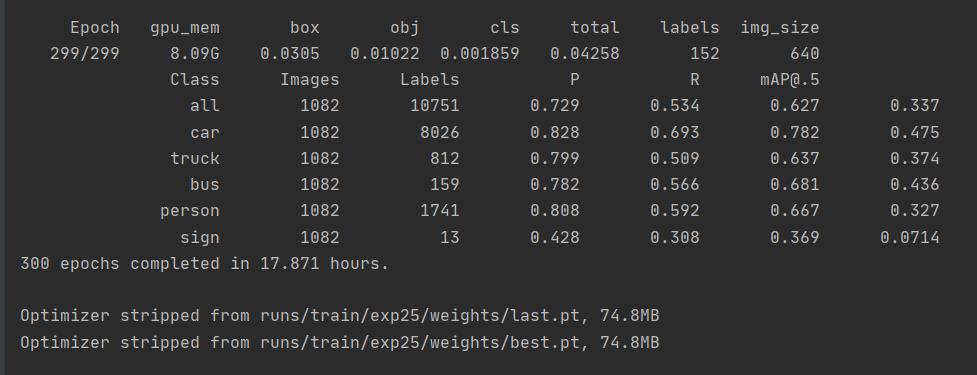
只能将其调大。重新训练
随后再次开始训练时遇到问题终止了:
磁盘空间不足问题
RuntimeError: [enforce fail at inline_container.cc:319] . unexpected pos 216903872 vs 216903768
这是由于硬盘容量不足造成的。
这是由于我们在运行过程中会产生大量的权重文件,这些文件在数量多后所占空间是极大的。要注意随时清理。
这一次其没有完全运行完便终止了,但根据迭代时的效果来看其已经不会有更多提升。
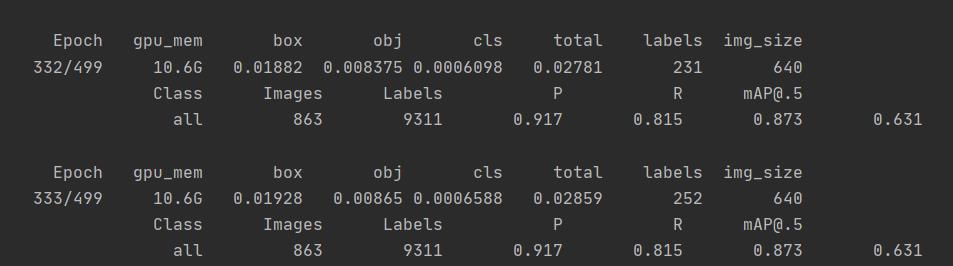
进行测试,效果并不理想
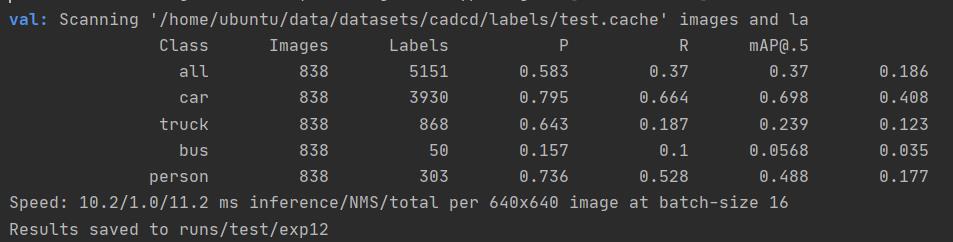
模型在训练过程中会产生大量的权重文件这些文件会占用大量的磁盘空间。但其实通过查看保存到权重文件我们可以看到很多都是在训练的某个epoch中产生的,而我们一般只需要最好的那个模型文件即可,即best.pt文件,那么我们就可以在实验过程中将这些不需要的文件删除。
我们可以选择一个个的命令输入删除:
rm epoch_049.pt epoch_074.pt
但这种需要输入很多文件名,很是费力,这时我们可以使用只保留某个文件其余都删除:
如我们只保留best.pt,init.pt,last.pt文件
rm -f !(best.pt|init.pt|last.pt)
但在运行中可能会报错:bash中运行后会提示,不能识别 ! 这个命令符
bash: !: event not found
这时可以使用shopt 内置命令启用shell选项 (extglob), 则会识别几个扩展模式匹配运算符
模式列表是由 | 分割
查看shell选项 extglob
shopt |grep extglob
启动shell选项 extglob
shopt -s extglob
关闭shell选项 extglob
shopt -u extglob
P,R,Map一直为0问题
今天遇到的一个Map一直为0问题,说实话先前在detr模型中也曾经遇到过,但一直没有得到解决,今天在yolo中再次遇到了,说实话就很无语。后来查阅资料提到说可能是pytorch版本不匹配导致的。这下更无语了,先前博主的环境一直使用的是这个,没有出现过这个问题呀。如下图:
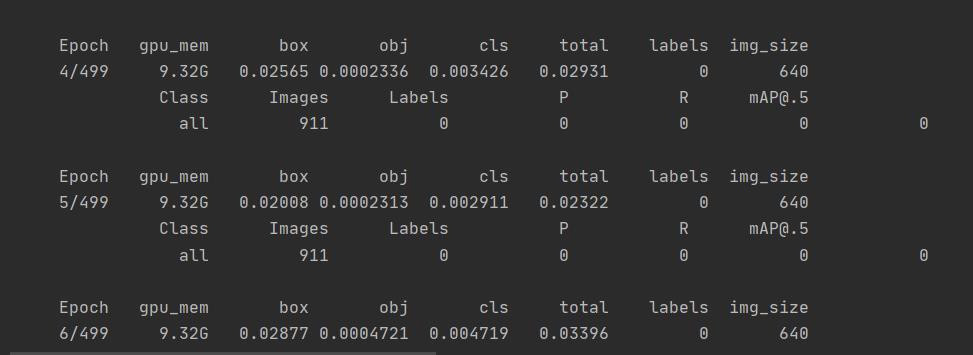
考虑到自己更换了预训练模型,心想是不是这个问题导致的,因此便重新换回了先前的模型:
发现竟然原先的模型也一直为0,这下让博主懵了,明明用的都是同样的环境呀。
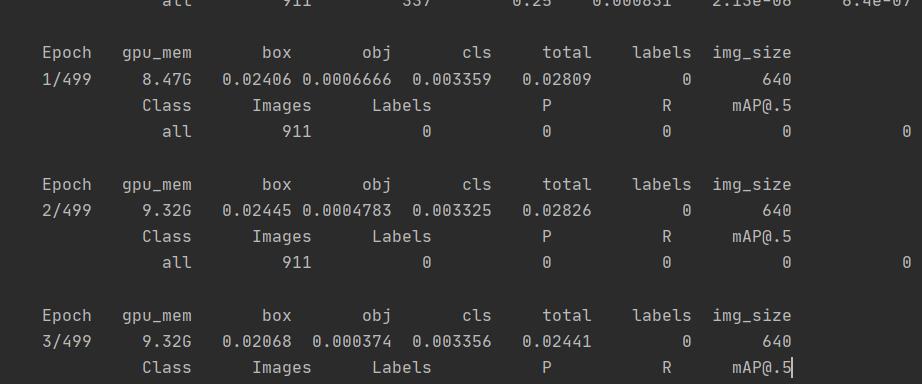
随后博主使用了另一个服务器,发现在另一个服务器上的运行是正常的。这~,难道说博主的环境真的出了问题,随后博主打开了两个服务器的环境查看一下:发现果然环境不同。


其实在源码的依赖包配置文件中已经指出:

随后将其更换为一样的后。再次运行,发现问题依旧没有解决,但这时两边对比,发现labels有些不同,便猜测是数据集加载出了问题。
随后检测了一下数据集,发现果然是数据集出现了问题,labels中标签缺失,将数据集替换后再次运行便正常了。
哎,白高兴一场,还以为可以解决先前detr里面出现的问题了呢。
以上是关于YOLOv7实验记录的主要内容,如果未能解决你的问题,请参考以下文章