八3月5日-关于《手机行为识别》近日问题和解决方法
Posted 小常在学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了八3月5日-关于《手机行为识别》近日问题和解决方法相关的知识,希望对你有一定的参考价值。
首先,这篇笔记是在3.2日学习完深度学习计算后,希望将数据集搭建简单网络模型测试中遇到的各种问题,在几天的查阅资料过程中多次尝试解决方法,写的总结。
第一个问题:为什么数据集用SVM网格搜索可以得到良好结果
数据集构建
本数据集是通过实验采集,变量控制良好,原始数据良好。
特征数据转换为可用于机器学习的数字特征
经过更多的查阅资料和这方面数据提供者对数据集的介绍,原始数据已经被转化成数字特征方便学习。
普通数据特征
例如以下特征等上百种特征:
最小值、min
最大值、max
均值、mean
中值、median
均方根、RMS():Root mean square
四分位数、Quartile(25%, 50% , 75%)
轴间相关系数、cc_axis(): Correlation coefficient between axis
皮尔逊相关系数
小波包变换子带能量及其子带能量之和
过零率、ZCR(Zero crossing rate)
偏度、Skewness
峰度,Kurtosis
加速度数据特征
时域——均值、标准差、方差、四分位数范围(IQR)、平均绝对偏差(MAD)、轴间相关性、熵和峰度。子空间池的技术(将原始复杂的输入数据建模/投影到新的维度中)。频域——傅里叶变换,和离散余弦变换。
相关特征选取
当人们在进行各项日常活动时,身体加速度最能反映活动的变化情况。
通常人体活动所产生的身体加速度的有效频率成分出现在25Hz以下,大于25Hz的频率成分基本上为噪声数据,而重力仅具有低频分量且其频率成分通常分布在0Hz附近,这是因为其对总加速度的影响变化相当小。
综合分析
数据在初期已经被良好处理,但是我们仍可做标准化、归一化等工作使数据更符合学习要求。
要不要做异常值处理
可以看到处理图中,明显,坐和躺有离群值存在。
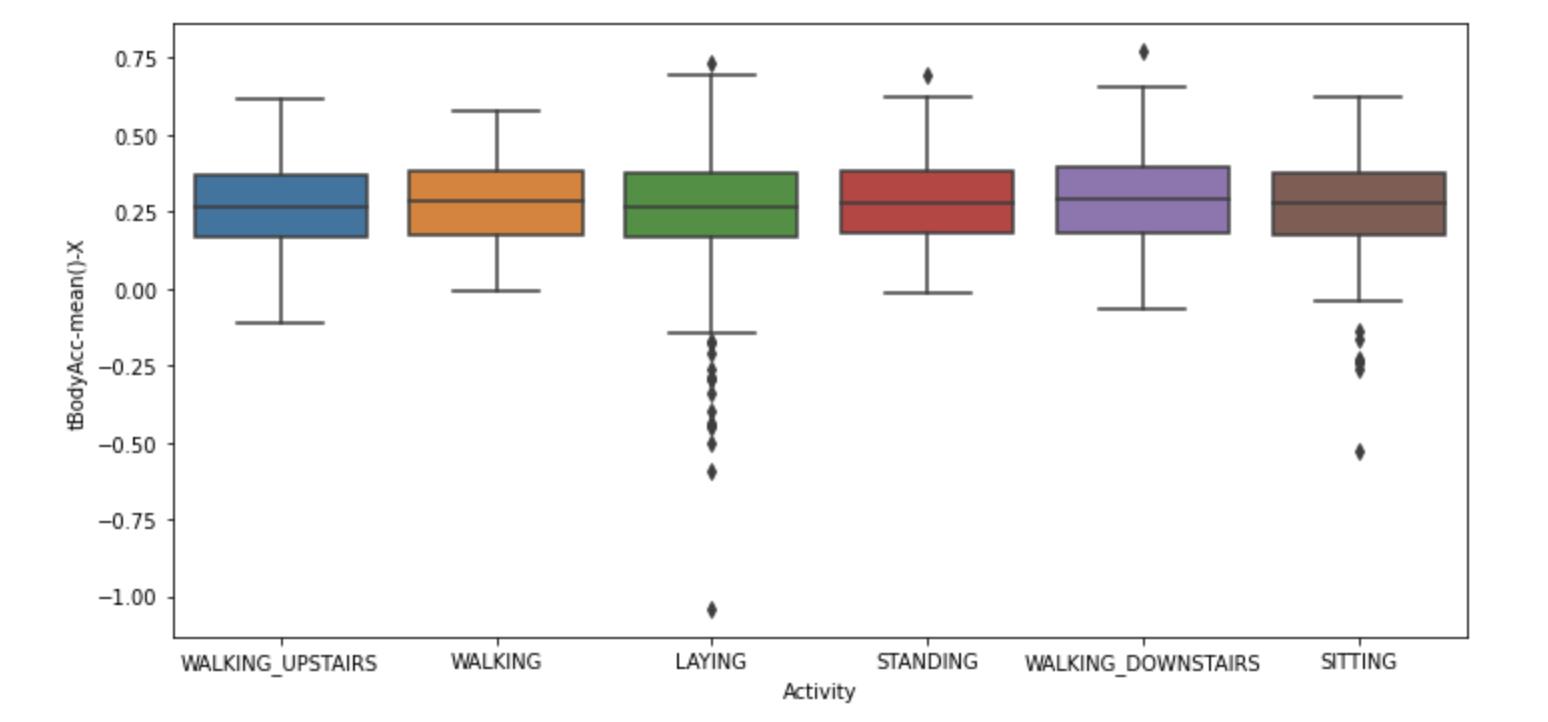
但是对于三种静止状态行为来讲,其规律性也许没有那么强。离群值完全有可能是人在不同地方或者情景中坐、躺。也应该是这两种行为的特殊情况,如果不对此进行学习,机器可能无法对某些特殊情况下坐躺进行有效识别。个人认为,不需要去掉离群值,而是应该让计算机学习到一些特殊情况下的坐躺。
因为只有静止动作可存在离群值。
第二个问题:关于个人数据集进行softmax分类需要注意的点
在学习过程中,各种教材都使用了Minist等pytorch内包含的数据集进行操作。而我们个人数据集和已经有相关函数直接进行模型标准化输入张量生成的数据集不同。我们面临着模型输入格式如何转变成模型要求格式,是一个很大的问题。
1、格式转换
dataframe或numpy转tensor
对于pytorch而言我们无法像之前机器学习和keras框架等,直接传入一个df格式或者ndarray格式数据进行学习。必须转化成tensor,并且在最后保存预测文件为.csv时,又需要将tensor转会df格式进行保存。
X=np.array(test_df)
X_test = torch.from_numpy(X)
X_test= X_test.to(torch.float32)tensor转ndarry再转dataframe
predicted=np.array(predicted)
predicted = pd.DataFrame(predicted,columns=["Activity"])2、pytorch模型学习要求
首先,我对手机行为识别数据转成tensor,模型输入也设置了561,但是提示两矩阵形状不符合。然后根据查阅资料得到的两种可能错误原因进行解决。
数据集要求
首先,pytorch喜欢较小的数据集,而不是一次传入较大数据集一次计算。所以经常需要分批进行。这也是我们看到各种教材中选用MINIST数据集时都会设计对batch_size的原因。
然后我尝试将数据集只选出部分,发现还是有问题,提示两矩阵格式不符合。
然后我使用tensor.dtype属性查看了我分好的数据和MINIST最后传给模型的数据,发现都是tensor然后矩阵形状也完全按照对应思路来调整了模型输入输出。
但是最后还是报错。
最终原因如下:
pytorch对数据精度的不敏感性
最终经过漫长的修改、尝试、报错,在阅读一份文档时发现,“pytorch对数据精度不敏感,无法处理高精度数据,会产生出错导致无法计算。”然后我突然想到之前数据精度是float64,而MINIST数据最后处理出来精度是float32。在尝试将数据精度改变后,发现报错内容变了,变成了最后输出计算的矩阵格式不对。然后我对照了MINIST数据集输出,发现它的输出和标签格式是Long64,而我的标签格式是int32。
在修改后,终于成功实现了基本的softmax回归和加入线性层的两层网络回归,提交结果分别为76.1和86.6。
代码如下:
完整的转换格式,转成tensor再改变数据精度:
##################################这一步很关键,涉及到torch对精度不敏感,如果float64的话会报错矩阵有误
###X_tensor.dtype
###结果是torch.float64
X_tensor= X_tensor.to(torch.float32)
Y=np.array(train_Y)
Y_tensor = torch.from_numpy(Y)
#################################同理,这一步也很关键,如果是int32的话也会报错
###X_tensor.dtype
###结果是torch.int32
Y_tensor = Y_tensor.to(torch.long)完整的softmax回归解决《手机行为识别》代码
#导入库
import torch
import torch.nn as nn
import torch.optim as optim
#读取数据,我的数据就在同一目录下
train_df = pd.read_csv('train.csv')
test_df = pd.read_csv('test.csv')
#先提取特征集合、标签
train_X = train_df.iloc[:,0:561] #提取特征集
train_Y = train_df['Activity'] #提取标签
#将其转化成tensor格式
X=np.array(train_X)
X_tensor = torch.from_numpy(X)
##################################这一步很关键,涉及到torch对精度不敏感,如果float64的话会报错矩阵有误
###X_tensor.dtype
###结果是torch.float64
X_tensor= X_tensor.to(torch.float32)
Y=np.array(train_Y)
Y_tensor = torch.from_numpy(Y)
#################################同理,这一步也很关键,如果是int32的话也会报错
###X_tensor.dtype
###结果是torch.int32
Y_tensor = Y_tensor.to(torch.long)
X=np.array(test_df)
X_test = torch.from_numpy(X)
X_test= X_test.to(torch.float32)
#定义特征和种类数量
n_features, n_classes = 561,6
#然后构建多层softmax分类器
class MultiSoftmaxClassifier(nn.Module):
def __init__(self, n_features, n_classes):
super(MultiSoftmaxClassifier, self).__init__()
self.linear = nn.Linear(n_features, n_classes)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.linear(x)
x = self.softmax(x)
return x
#定义模型、交叉熵损失函数、优化器
model = MultiSoftmaxClassifier(n_features=561, n_classes=6)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
for epoch in range(100):
running_loss = 0.0
optimizer.zero_grad()
outputs = model(X_tensor)
loss = criterion(outputs, Y_tensor)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 将数据集分为输入和标签
test_inputs = torch.tensor(X_test, dtype=torch.float32)
with torch.no_grad():
test_outputs = model(test_inputs)
_, predicted = torch.max(test_outputs.data, 1)
print('Predictions:', predicted)
predicted=np.array(predicted)
predicted = pd.DataFrame(predicted,columns=["Activity"])
predicted['Activity'] = predicted['Activity'].map(
0:'LAYING',
1:'STANDING',
2:'SITTING',
3:'WALKING',
4:'WALKING_UPSTAIRS',
5:'WALKING_DOWNSTAIRS'
)
predicted.to_csv('submission.csv', index=None)
!zip submission.zip submission.csv以上代码最终结果提交得分为86.6
以上是关于八3月5日-关于《手机行为识别》近日问题和解决方法的主要内容,如果未能解决你的问题,请参考以下文章