DataScience之boxcox:scipy.stats.boxcox函数的简介案例应用(将非正态分布数据转换为正态分布数据)之详细攻略
Posted 一个处女座的程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DataScience之boxcox:scipy.stats.boxcox函数的简介案例应用(将非正态分布数据转换为正态分布数据)之详细攻略相关的知识,希望对你有一定的参考价值。
DataScience之boxcox:scipy.stats.boxcox函数的简介、案例应用(将非正态分布数据转换为正态分布数据)之详细攻略
目录
相关文章
ML之FE:特征工程中变量变换(数据归一化/分布正态化等)的概述、构造新变量/构造特征的概述等处理方法技巧总结之详细攻略
scipy.stats.boxcox函数的简介
官方文档:scipy.stats.boxcox — SciPy v1.10.1 Manual
scipy.stats.boxcox(x, lmbda=None, alpha=None, optimizer=None)
| Parameters | |
| x | Ndarray 要转换的输入数组。 如果lmbda不为None,则这是scipy.special.boxcox的别名。如果x < 0,返回nan;如果x == 0且lmbda < 0则返回-inf。 如果lmbda为None,则数组必须为正的、一维的、非常量。 (1)、实际应用中,详见df2boxcox()函数 |
| lmbda | 标量,可选 如果lmbda为None(默认值),则找到使对数似然函数最大化的lmbda值,并将其作为第二个输出参数返回。 如果lmbda不是None,则对该值进行转换。 |
| alpha | 浮动,可选 如果lmbda为None且alpha不是None(默认),则返回lmbda的100 * (1-alpha)%置信区间作为第三个输出参数。必须在0.0和1.0之间。 如果lmbda不为None, alpha将被忽略。 |
| optimizer | 可调用,可选 如果lmbda为None,则optimizer是用于查找使负对数似然函数最小的lmbda值的标量优化器。Optimizer是一个接受一个参数的可调用对象: 有趣可调用:目标函数,在给定的lmbda值处评估负对数似然函数 并返回一个对象,例如scipy.optimize的实例。OptimizeResult,它保存属性x中lmbda的最优值。 请参阅boxcox_normmax中的示例或scipy.optimize的文档。Minimize_scalar获取更多信息。 如果lmbda不是None,优化器将被忽略。 |
| Returns | |
| boxcox | Ndarray Box-Cox power转换阵列。 |
| maxlog | maxlog 浮动,可选 如果lmbda参数为None,则返回的第二个参数是使对数似然函数最大化的lmbda。 |
| (min_ci max_ci) | float的元组,可选 如果lmbda参数为None且alpha不为None,则返回的浮点元组表示给定alpha的最小和最大置信度限制。 |
scipy.stats.boxcox函数的案例应用
1、将非正态分布数据转换为正态分布数据
我们从非正态分布中生成一些随机变量,并为其绘制概率图,以显示尾部是非正态分布:
我们现在使用boxcox来转换数据,使其最接近正常:
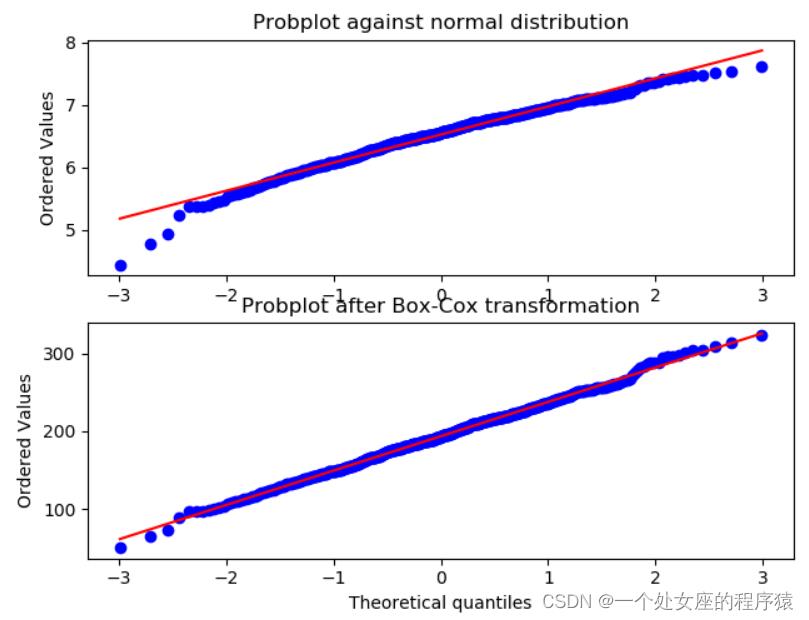
from scipy import stats
import matplotlib.pyplot as plt
fig = plt.figure()
ax1 = fig.add_subplot(211)
x = stats.loggamma.rvs(5, size=500) + 5
prob = stats.probplot(x, dist=stats.norm, plot=ax1)
ax1.set_xlabel('')
ax1.set_title('Probplot against normal distribution')
ax2 = fig.add_subplot(212)
xt, _ = stats.boxcox(x)
prob = stats.probplot(xt, dist=stats.norm, plot=ax2)
ax2.set_title('Probplot after Box-Cox transformation')
plt.show()
以上是关于DataScience之boxcox:scipy.stats.boxcox函数的简介案例应用(将非正态分布数据转换为正态分布数据)之详细攻略的主要内容,如果未能解决你的问题,请参考以下文章