Python案例篇:某短视频采集(不用等着大数据给你推送了)
Posted 五包辣条!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python案例篇:某短视频采集(不用等着大数据给你推送了)相关的知识,希望对你有一定的参考价值。

前言
大家好,我是辣条哥
|

于是乎我开始总结了一下,肯定是系统推送有问题不然不至于让我这一顿熬夜,那么这时候我的程序员毛病来了,为啥我不直接采集出来这样就没必要一个一个的去刷了吗? 说干就干,边干边记录然后就有了这个博文了~ |
目录
采集目标
工具准备
开发工具:pycharm
开发环境:python3.7, Windows10
使用工具包:requests
项目思路解析
我们今天需要获取的是某短视频的点赞视频信息,首先定位到我们需要的数据位置,通过抓包的方式进行准确的数据,点击快手页面进行登录,点击个人中心,点击我赞的视频,在当前页面进行抓包,获取到我们想要的数据信息
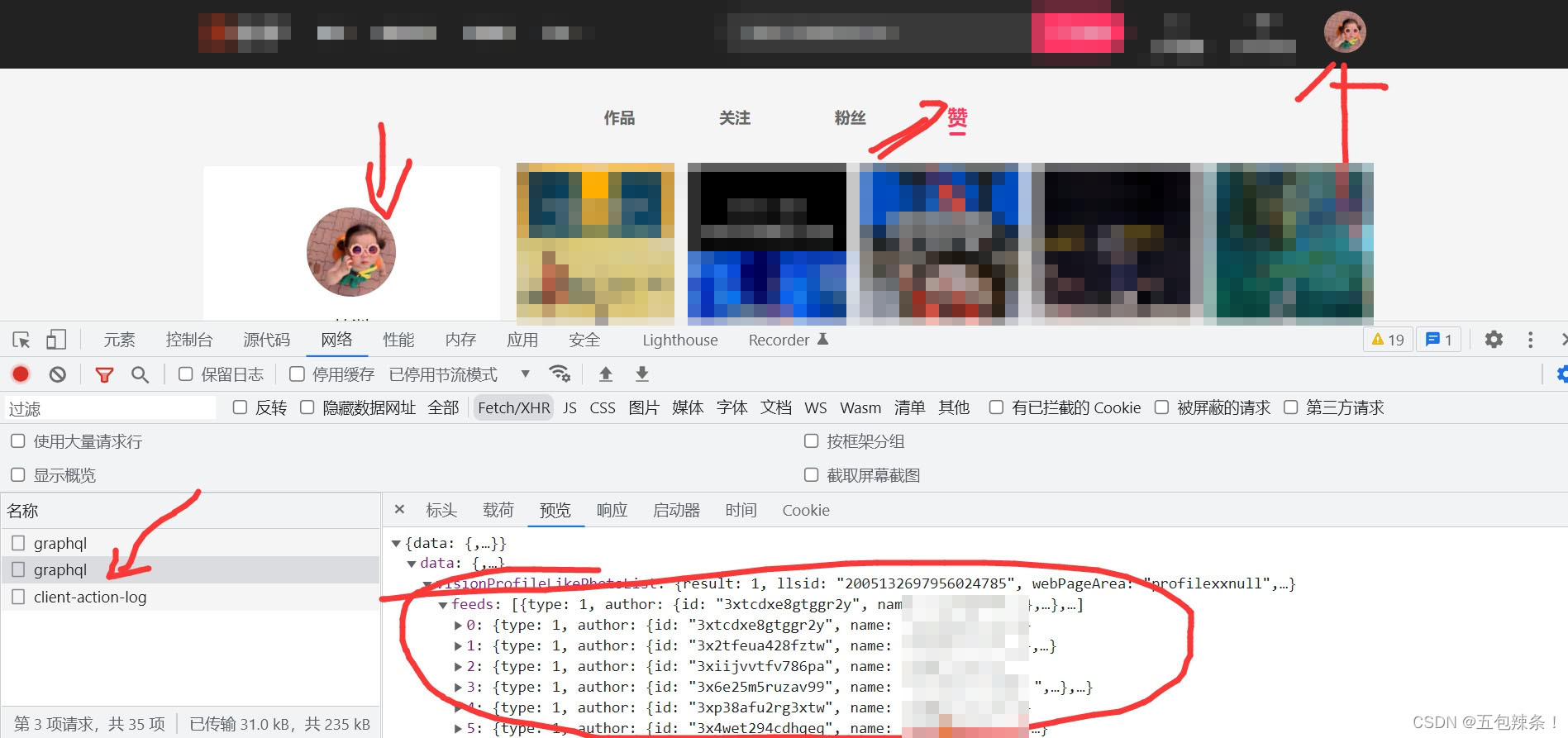
明确到自己需要采集的数据之后做我们爬虫的第一步,获取到我们目标地址:某短视频首页,通过requests发送网络请求,带上我们需要的请求头,这个请求头需要注意,他的请求头需要带上accept: /,不然在获取下一页的时候页数是不会变化的,这个需要重点注意,请求头入下:
headers =
'accept': '*/*',
'content-type': 'application/json',
'Cookie': '',
'Host': 'www.kuaishou.com',
'Origin': 'https://www.xxxxxxxxxx.com',
'Referer': 'https://www.xxxxxxxxx.com/profile/3x382umv98zjz79',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/100.0.4896.127 Safari/537.36',
发送的是post请求需要携带的参数,pcursor是用来控制页数信息的,传递的数据是载荷数据,传输时以json接受就行,一下是提交的数据信息:
data =
"operationName": "visionProfileLikePhotoList",
"variables":
"pcursor": '',
"page": "profile"
,
"query": "fragment photoContent on PhotoEntity \\n id\\n duration\\n caption\\n likeCount\\n viewCount\\n realLikeCount\\n coverUrl\\n photoUrl\\n photoH265Url\\n manifest\\n manifestH265\\n videoResource\\n coverUrls \\n url\\n __typename\\n \\n timestamp\\n expTag\\n animatedCoverUrl\\n distance\\n videoRatio\\n liked\\n stereoType\\n profileUserTopPhoto\\n __typename\\n\\n\\nfragment feedContent on Feed \\n type\\n author \\n id\\n name\\n headerUrl\\n following\\n headerUrls \\n url\\n __typename\\n \\n __typename\\n \\n photo \\n ...photoContent\\n __typename\\n \\n canAddComment\\n llsid\\n status\\n currentPcursor\\n __typename\\n\\n\\nquery visionProfileLikePhotoList($pcursor: String, $page: String, $webPageArea: String) \\n visionProfileLikePhotoList(pcursor: $pcursor, page: $page, webPageArea: $webPageArea) \\n result\\n llsid\\n webPageArea\\n feeds \\n ...feedContent\\n __typename\\n \\n hostName\\n pcursor\\n __typename\\n \\n\\n"
发送请求获取的数据为json数据信息转换成字典数据,从中提取出你想要的数据信息,筛选出我们想要的视频标题,以及视频的播放地址,对视频地址发送请求就行,想实现翻页效果需要注意,我们下一页的页面数据是在他上个数据的接口里,提取数据了时候一起提取出来
简易源码分享
import requests
data =
"operationName": "visionProfileLikePhotoList",
"variables":
"pcursor": '',
"page": "profile"
,
"query": "fragment photoContent on PhotoEntity \\n id\\n duration\\n caption\\n likeCount\\n viewCount\\n realLikeCount\\n coverUrl\\n photoUrl\\n photoH265Url\\n manifest\\n manifestH265\\n videoResource\\n coverUrls \\n url\\n __typename\\n \\n timestamp\\n expTag\\n animatedCoverUrl\\n distance\\n videoRatio\\n liked\\n stereoType\\n profileUserTopPhoto\\n __typename\\n\\n\\nfragment feedContent on Feed \\n type\\n author \\n id\\n name\\n headerUrl\\n following\\n headerUrls \\n url\\n __typename\\n \\n __typename\\n \\n photo \\n ...photoContent\\n __typename\\n \\n canAddComment\\n llsid\\n status\\n currentPcursor\\n __typename\\n\\n\\nquery visionProfileLikePhotoList($pcursor: String, $page: String, $webPageArea: String) \\n visionProfileLikePhotoList(pcursor: $pcursor, page: $page, webPageArea: $webPageArea) \\n result\\n llsid\\n webPageArea\\n feeds \\n ...feedContent\\n __typename\\n \\n hostName\\n pcursor\\n __typename\\n \\n\\n"
headers =
'accept': '*/*',
'content-type': 'application/json',
'Cookie': '',
'Host': 'www.xxxxxxxxxx.com',
'Origin': 'https://www.xxxxxxxx.com',
'Referer': 'https://www.xxxxxxxx.com/profile/3x382umv98zjz79',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36',
url = 'https://www.xxxxxxxx.com/graphql'
res = requests.post(url, headers=headers, json=data)
for i in res.json()['data']['visionProfileLikePhotoList']['feeds']:
# print(i)
title = i['photo']['caption']
play_url = i['photo']['photoUrl']
res = requests.get(play_url)
# print(res.content)
title = title.replace('#', '').replace('?', '').replace('\\n', '')
with open('某短视频/' + title + '.mp4', 'wb')as f:
f.write(res.content)
print('正在下载:'.format(title))
以上是关于Python案例篇:某短视频采集(不用等着大数据给你推送了)的主要内容,如果未能解决你的问题,请参考以下文章