Elastic:使用 Python 方便地实现 Elasticsearch-To-CSV 导出
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elastic:使用 Python 方便地实现 Elasticsearch-To-CSV 导出相关的知识,希望对你有一定的参考价值。
在我之前的文章 “Elasticsearch:如何把 Elasticsearch 中的数据导出为 CSV 格式的文件” ,我介绍了两种方法来把一个 Elasticsearch 索引导出到一个 CSV 格式的文档中。但是据 一些人的实践,在面临海量文档的情况下,会出现 timeout 错误 (使用 CSV report),或者导出速度比较慢的情况(在使用 Logstash 的方案)。在本篇文章中,我将介绍一个使用 Python 的方法,很方便地把所需要的数据导出到一个 CSV 文件中。
准备数据
在本次是有中,我们将一个 Kibana 自带的 eCommerce 数据为例:

点击上面的 Add data 按钮:
这样我们就把 eCommerce 的索引导入到 Elasticsearch 中了。我们可以通过如下的命令来进行查看:

我们可以看见被导入的 kibana_sample_data_ecommerce 索引。
安装 python 工具
我们在 terminal 中进行安装一个比较容易使用的 CLI 工具 elasticsearch-tocsv。你必须安装好 python3,并且版本在 3.8 及以上。我们可以通过如下的方式来进行安装:
$ sudo pip3 install elasticsearch-tocsv你会看到它已下载并安装(如果尚未安装)所需的软件包(pandas,pytz,elasticsearch,tqdm,requests),片刻之后n 应该可以使用。 如果一切顺利,你应该可以使用以下命令启动命令:
$ elasticsearch_tocsv
usage: elasticsearch_tocsv [-h] [-af AGGREGATION_FIELDS]
[-at AGGREGATION_TYPE] [-asi ALLOW_SHORT_INTERVAL]
[-b BATCH_SIZE] [-c CERT_VERIFICATION]
[-dp DISABLE_PROGRESSBAR] [-e EXPORT_PATH]
[-ed ENDING_DATE] [-em ENABLE_MULTIPROCESSING] -f
FIELDS [-ho HOST] -i INDEX [-k KEEP_PARTIALS]
[-lbi LOAD_BALANCE_INTERVAL] [-mf METADATA_FIELDS]
[-o SCROLL_TIMEOUT] [-p PORT]
[-pcs PARTIAL_CSV_SIZE] [-pn PROCESS_NUMBER]
[-pw PASSWORD] [-q QUERY_STRING]
[-rd REMOVE_DUPLICATES] [-s SSL]
[-sd STARTING_DATE] [-spw SECRET_PASSWORD]
[-t TIME_FIELD] [-tz TIMEZONE] [-u USER]
elasticsearch_tocsv: error: the following arguments are required: -f/--fields, -i/--index如果是这种情况,则意味着你的 elasticsearch_tocsv 软件包已正确安装,你可以继续提取。 然后,假设你的 ES 实例在 localhost 上运行,并且禁用了 SSL 并且未进行身份验证,则可以轻松进行以下操作:
$ elasticsearch_tocsv -i kibana_sample_data_ecommerce \\
-f "customer_first_name,customer_last_name,email"那么在你运行命令的目录下你可以发现一个叫做 es_export.csv 的文件。它的内容如下:
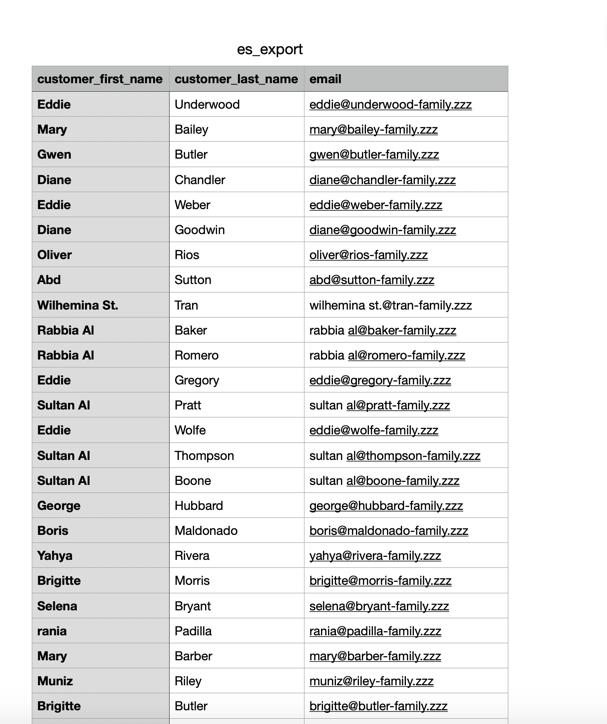
这是该工具所需的最少参数,即你要从中提取数据的索引以及你感兴趣的该索引的字段。显然,字段数越多和/或字段越冗长提取,提取时间越长,生成的 CSV 文件越重。虽然如此,由于部分文件写入和合并的内部逻辑以及一些用于设置某些临界范围的可调参数(例如 -pcs /-partial_csv_size),它永远不会导致 OOM 错误,并且始终可以完成工作。唯一的物理限制显然是由用于存储结果文件的可用磁盘空间来表示的(对于数百万个提取的文档,其大小可能约为 GB)。
一旦运行了先前的命令,脚本就会知道它必须在没有 SSL 或身份验证的情况下连接到 localhost:9200,从kibana_sample_data_ecommerce 索引中获取所有数据,提取所选字段,并将这些字段的所有值写入 CSV 文件 es_export 中。 .csv(默认导出路径),索引中每个文档一行。
对于你可以设置的所有特定参数以及使用此工具可以执行的所有操作,我宁愿将你重定向到项目的 github 页面,。 希望不久后将有更多结构化的文档。
参考:
【1】 https://www.linkedin.com/pulse/elasticsearch-to-csv-export-made-easy-python-fabio-pipitone/
以上是关于Elastic:使用 Python 方便地实现 Elasticsearch-To-CSV 导出的主要内容,如果未能解决你的问题,请参考以下文章