Java多线程系列-- Fork&Join框架,分治的艺术
Posted leobert_lan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java多线程系列-- Fork&Join框架,分治的艺术相关的知识,希望对你有一定的参考价值。
前言
本篇是多线程系列中的一篇,我们在先前的一篇文章中回顾了线程池的主要知识
过去了很长时间,我们简单提要一下:
- 设计目的:简化线程的使用,管理与复用,避免直接操作线程
- 如何使用线程池
- 设计实现与源码细节
本篇我们延续下去,回顾 Fork&Join。主要内容如下:
- 使用场景和注意事项
- 设计原理
- 示例代码演示使用方式以及和线程池简单对比
全文总结
内容为基础部分,简单拾遗的读者扫一眼总结即可,若均已掌握,没必要浪费时间阅读细节
- ForkJoinPool是线程池的补充,并不是替代。线程池一般用于处理 独立的 请求、任务
- 适合实现 “分治” 类算法,尤其是分治后递归调用的函数
- 适用于计算密集型,如果是I/O密集型,或者线程间同步等造成长时间阻塞时,可配合ManagedBlocker使用
- Work Stealing(工作窃取)机制 和 双端队列,已经了解设计细节便不需要再看下去了
如何使用
本章非常的基础,已经掌握如何使用,但没有思考过Fork&Join设计思路的读者,可以跳跃到 原理
我们挑选一道简单题 计算斐波那契数 ,并使用递归算法求解。
斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0,F(1) = 1
F(n) = F(n - 1) + F(n - 2),其中 n > 1
给定 n ,请计算 F(n) 。
来源:力扣(LeetCode)
Fork&Join 实现
如题,我们需要定义计算任务,这将通过继承 ForkJoinTask 实现,当计算任务不可分(或者没有必要分解)时,自行处理结果返回,否则分解任务。
static class Fibonacci extends RecursiveTask<Long>
final int n;
public Fibonacci(int n)
this.n = n;
@Override
protected Long compute()
System.out.println("compute fib(" + n + "), in thread:" + Thread.currentThread().getName());
if (n <= 1)
return (long) n;
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
f2.fork();
return f2.join() + f1.join();
我们通过 fork() 将子任务丢入任务队列,并通过 join() 得到计算后的结果。
接下来看一看使用ForkJoinPool执行任务:
我们定义一个最大工作线程数为4的ForkJoinPool,并计算 Fib(5) 的结果。可按照CPU核心数取最大工作线程数
注意,因为没有针对计算过程做任何优化,并且使用了输出,不要计算过大的值折腾电脑
class Demo
public static void main(String[] args)
ForkJoinPool forkJoinPool = new ForkJoinPool(4);
Fibonacci fib = new Fibonacci(5);
Long result = forkJoinPool.invoke(fib);
System.out.println(result);
通过 invoke(ForkJoinTask<T> task) 可以在当前线程阻塞式获取计算结果。
通过 execute(ForkJoinTask<?> task) 可以进行异步处理,因为 class ForkJoinTask<V> implements Future<V>,
使用方式和Future一致,复习链接
可以看到,递归过程中有很多的重复,但这源于算法本身,
当递归算法本身会使得子任务产生重复计算或者重复任务时,应当考虑处理中间结果缓存,减少不必要的任务,可以减少重复计算和GC压力。
如果移除控制台输出,一般可以尝试下计算第40个,不建议再计算你更靠后的值。
compute fib(5), in thread:ForkJoinPool-1-worker-1
compute fib(3), in thread:ForkJoinPool-1-worker-1
compute fib(1), in thread:ForkJoinPool-1-worker-1
compute fib(2), in thread:ForkJoinPool-1-worker-3
compute fib(0), in thread:ForkJoinPool-1-worker-3
compute fib(1), in thread:ForkJoinPool-1-worker-0
compute fib(4), in thread:ForkJoinPool-1-worker-2
compute fib(2), in thread:ForkJoinPool-1-worker-2
compute fib(0), in thread:ForkJoinPool-1-worker-2
compute fib(1), in thread:ForkJoinPool-1-worker-2
compute fib(3), in thread:ForkJoinPool-1-worker-2
compute fib(1), in thread:ForkJoinPool-1-worker-2
compute fib(2), in thread:ForkJoinPool-1-worker-0
compute fib(0), in thread:ForkJoinPool-1-worker-0
compute fib(1), in thread:ForkJoinPool-1-worker-3
5
原理
实际上,关于Java ForkJoin设计原理的分析,均源自其开发者 Doug Lea 的论文 A Java Fork/Join Framework
以及结合源码展开讨论。
时间充裕的读者可以看一看论文原文,接下来我们节选论文重要内容进行理解。
分治算法的核心思路
以伪代码描述分治的思想如下,当问题足够小(无需再拆分)时,直接处理,否则拆分问题,处理并汇总结果
Result solve(Problem problem)
if(problem is small)
directly solve problem
else
split problem into independent parts
fork new subtasks to solve each part
join all subtasks
compose result from subresults
分治+并行的核心要求
核心要求:框架能够让构建的子任务并行执行,并且拥有一种等待子任务运行结束的机制。
不难理解这一要求。
让我们思考一下,线程池+Future是不是满足这一要求?
很显然,线程池满足这个要求,但线程池的部分策略,甚至Thread的很多核心设计,对于 Fork/Join思路 而言是多余(过剩)的。
哪些是过剩的
包含这几个方面的过剩:
- Thread本身跟踪记录阻塞的手段
- 线程池对线程的管理
- 线程池对任务的管理
首先, 在同步和管理方面,Fork/Join任务只有简单的和常规的需求。例如,Fork/Join任务除了等待子任务执行结果,其他情况下不需要阻塞。
因此传统的用于跟踪记录阻塞线程的代价,是一种过剩。
但这种过剩不会为了Fork/Join而推翻重建
其次,对于合理的基础任务粒度而言,构建和管理一个线程的代价,可能比执行任务花费的代价更大。线程池对线程的多种管理手段,大多是不必要的。
再者,Fork&Join 是处理同一个任务的子任务,它更像是一组 “事务”,只在意最终结果,否则就全部取消并丢弃。 而线程池是面向独立的任务,并且采用了BlockingQueue暂存任务,以保障并发时高效且准确。这些对于Fork&Join
而言,都是没有必要的。
FJTask框架思路图示
注:论文从开始就以 “FJTask框架” 指代了Java中将要实现的Fork&Join框架,以 “FJTask” 指代一个可由分治解决的任务
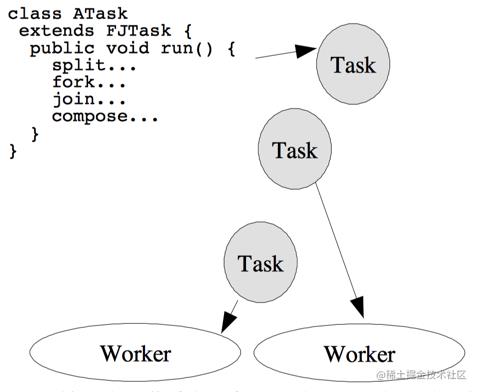
很朴素的思路,让任务得到拆分,并被指派到合适的工作线程中执行,汇总出结果。
work-stealing
上文中我们已经提及,线程池对于任务的管理机制对于 FJTask框架 而言是过剩的。除此之外,Fork&Join倾向于 “大任务优先” 去窃取任务。
这也是Java API文档中提到的,ForkJoinPool和线程池最大的不同(毕竟核心线程数和最大线程数一致的线程池,管理线程是类似的)
all threads in the pool attempt to find and execute tasks submitted to the pool and/or
created by other active tasks (eventually blocking waiting for work if none exist).This enables efficient processing when most tasks spawn other subtasks (as do most ForkJoinTasks),
as well as when many small tasks are submitted to the pool from external clients.Especially when setting asyncMode to true in constructors, ForkJoinPools may also be appropriate
for use with event-style tasks that are never joined.
按照该设计思路,先让每一个工作线程拥有自己的任务队列,这样在管理方式上才有减负的空间。
参考CILK的设计,给FJTask框架制定如下的任务管理策略
- 每一个工作线程维护自身调度队列中的可运行任务
- 队列以双端队列的形式被维护,支持后进先出:LIFO的push和pop操作; 和先进先出:FIFO的take操作
- 工作线程将任务所产生的子任务,放入到工作线程自身的双端队列中
- 处理队列中的任务时,工作线程使用后进先出(LIFO)的策略,递归
- 当一个工作线程,没有本地任务可运行时,它将尝试窃取其他工作线程的任务。此时按照先进先出(FIFO)的策略,即大任务优先。
- 当一个工作线程触及了join操作,它将尝试处理其他任务,直到目标任务被告知已经结束(通过isDone方法)。所有的任务都会无阻塞的完成。
当一个工作线程,没有本地任务可运行,且无法从其他线程中获取任务时,它就会退出(通过yield、sleep和/或者优先级调整)并经过一段时间之后再度尝试直到所有的工作线程都被告知他们都处于空闲的状态。在这种情况下,他们都会阻塞直到其他的任务再度被上层调用。
其中的1-5条,均在下图中得到体现。
椭圆代表了工作线程,它内部维护一个双端队列,通过Pushing 放入任务,通过Popping弹出任务执行,并可能被其他工作者从另一端窃取任务
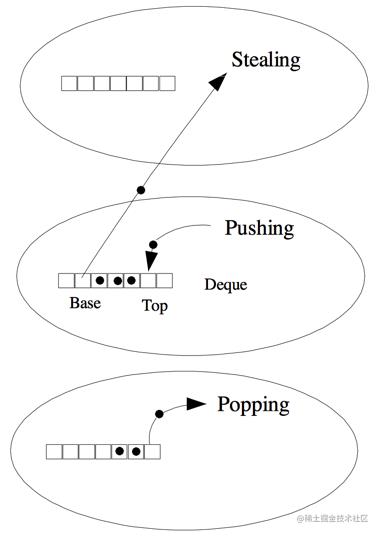
作者按:源码部分本篇不展开,建议没有读过源码的读者,花点时间泛读一二
ManagedBlocker
这是 ForkJoinPool中采用的,为任务提供扩展管理并行数的接口。
在FJTask中,我们希望充分的发挥多核CPU的计算性能,它被设计的擅长计算,但遇到会阻塞的任务时,CPU则会被浪费。
往往在可能会阻塞的任务中,我们期望能增加线程来处理任务,而不是单纯的阻塞等待。
public static interface ManagedBlocker
boolean block() throws InterruptedException;
boolean isReleasable();
实现并调用:ForkJoinPool#managedBlock。
isReleasable(): 如果不需要阻塞,则返回 true;
block(): 可能阻塞当前线程,例如等待锁定或条件, 如果没有额外的阻塞必要,返回true。
关于创建补偿线程的细节,不再展开。
以上是关于Java多线程系列-- Fork&Join框架,分治的艺术的主要内容,如果未能解决你的问题,请参考以下文章