fairseq学习笔记
Posted 雨宙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了fairseq学习笔记相关的知识,希望对你有一定的参考价值。
本文主要对fairseq框架模型训练之前的准备工作原理展开说明,重点是对框架源码的理解,文中以transformer模型为例,数据处理的过程是按照官方文档中对IWSLT数据集的处理进行的。
-
如何将task和criterion等(和模型无关的)参数绑定到
args中-
直接在命令中指定
-
不在命令中指定,则通过以下流程按照默认设置(default)完成绑定,主要思想是先获取
parser,再根据获取的parser生成args,方法调用流程如下所示:-
训练时首先调用
train.py中的主函数if __name__ == "__main__": cli_main() -
调用
fairseq_cli/train.py中的cli_main()函数,函数中首先获得parser,绑定一些没有在命令中指定的、按照默认值设置的参数# 获得parser parser = options.get_training_parser() -
然后再对
get_training_parser()进行详细说明,它位于fairseq/options.py位置,方法内首先调用get_parser()方法获取初始化parser并同时完成对一些参数的绑定,这其中包含我们重点关注的task和criterion参数,然后再调用add_dataset_args()等方法将其他参数也绑定到parser中def get_training_parser(default_task="translation"): # 获取初始化parser parser = get_parser("Trainer", default_task) # 向parser中添加参数 add_dataset_args(parser, train=True) add_distributed_training_args(parser) add_model_args(parser) add_optimization_args(parser) add_checkpoint_args(parser) add_ema_args(parser) return parser -
然后我们关注
get_parser()方法,它位于fairseq/options.py位置,方法内通过遍历REGISTRIES.items(),完成对一些参数的绑定,比如绑定criterion参数为默认值cross_entropy,需要注意的是,task参数是单独绑定的,它的默认值是由get_parser()方法传入的def get_parser(desc, default_task="translation"): # Before creating the true parser, we need to import optional user module # in order to eagerly import custom tasks, optimizers, architectures, etc. usr_parser = argparse.ArgumentParser(add_help=False, allow_abbrev=False) usr_parser.add_argument("--user-dir", default=None) usr_args, _ = usr_parser.parse_known_args() utils.import_user_module(usr_args) parser = argparse.ArgumentParser(allow_abbrev=False) gen_parser_from_dataclass(parser, CommonConfig()) from fairseq.registry import REGISTRIES # 在这里加入一些参数,比如criterion for registry_name, REGISTRY in REGISTRIES.items(): parser.add_argument( "--" + registry_name.replace("_", "-"), default=REGISTRY["default"], choices=REGISTRY["registry"].keys(), ) # Task definitions can be found under fairseq/tasks/ from fairseq.tasks import TASK_REGISTRY # 在这里task参数 parser.add_argument( "--task", metavar="TASK", default=default_task, choices=TASK_REGISTRY.keys(), help="task", ) # fmt: on return parser -
以上流程完成了对
parser参数的绑定,接下来我们需要根据parser生成args,同样是在fairseq_cli/train.py中的cli_main()函数中,当函数递归执行完生成parser的语句后,就会执行这一句来根据parser生成args# 根据获得的parser生成args args = options.parse_args_and_arch(parser, modify_parser=modify_parser) -
然后我们来关注一下
parse_args_and_arch()函数,它位于fairseq/options.py位置,我们重点关注以下语句,其将返回的namespace赋值到args上,完成了args参数绑定# 将返回的namespace赋值到args上 args, _ = parser.parse_known_args(input_args) -
parse_known_args()函数实际上不是位于项目中的,而是位于配置的环境envs\\fairseq_test\\Lib\\argparse.py中,其中通过循环将self的action属性中的参数循环赋值给namespace,在方法的末尾再将namespace返回def parse_known_args(self, args=None, namespace=None): if args is None: # args default to the system args args = _sys.argv[1:] else: # make sure that args are mutable args = list(args) # default Namespace built from parser defaults if namespace is None: namespace = Namespace() # 将self的action属性中的参数循环赋值给namespace # add any action defaults that aren't present for action in self._actions: if action.dest is not SUPPRESS: if not hasattr(namespace, action.dest): if action.default is not SUPPRESS: setattr(namespace, action.dest, action.default) # add any parser defaults that aren't present for dest in self._defaults: if not hasattr(namespace, dest): setattr(namespace, dest, self._defaults[dest]) # parse the arguments and exit if there are any errors try: namespace, args = self._parse_known_args(args, namespace) if hasattr(namespace, _UNRECOGNIZED_ARGS_ATTR): args.extend(getattr(namespace, _UNRECOGNIZED_ARGS_ATTR)) delattr(namespace, _UNRECOGNIZED_ARGS_ATTR) return namespace, args except ArgumentError: err = _sys.exc_info()[1] self.error(str(err))
-
-
-
如何将模型特有的参数绑定到
args中-
以
transformer模型中的transformer结构举例@register_model_architecture("transformer", "transformer") def base_architecture(args): ...首先通过装饰器将方法
base_architecture注册到ARCH_CONFIG_REGISTRY中 -
下面的代码位于
fairseq/options.py的parse_args_and_arch()方法中,首先检索args中有无arch参数并且arch是否注册到ARCH_CONFIG_REGISTRY,若符合条件,则将arch的名称作为索引调用ARCH_CONFIG_REGISTRY中的方法,args则作为方法参数传入,添加一些新的模型特有的参数if hasattr(args, "arch") and args.arch in ARCH_CONFIG_REGISTRY: ARCH_CONFIG_REGISTRY[args.arch](args)-
需要注意的是,
ARCH_CONFIG_REGISTRY存储的都是通过装饰器注册的方法名
ARCH_CONFIG_REGISTRY['transformer'] = <function base_architecture at 0x000001DA330F6F70> # 方法存储的位置所以其实
ARCH_CONFIG_REGISTRY[transformer](args)语句相当于调用base_architechture(args)方法
-
-
-
经过以上两步后,需要的参数现在都保存在
args中,fairseq为了使参数更加的结构化,通过调用convert_namespace_to_omegaconf()方法将args变成如下格式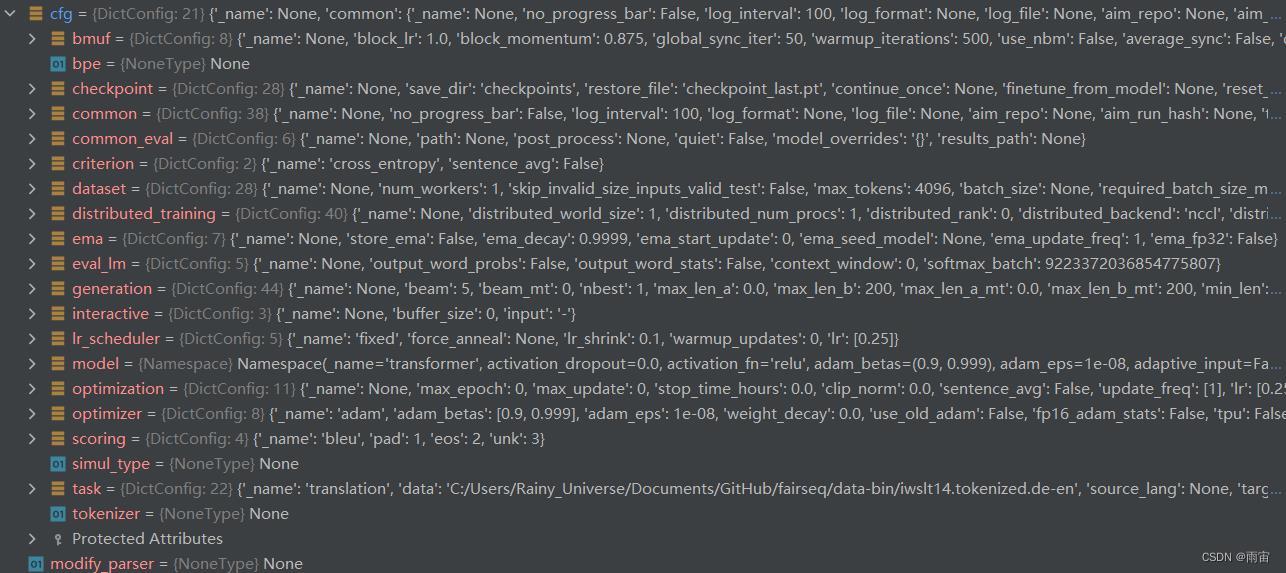
可以看到,同一类的参数被分到同一组中,完成参数的结构化
-
以上步骤中已经完成了参数的设置和处理,那么如何对
model/task/criterion进行构建呢-
目前代码还在
train.py中的cli_main()方法中,方法的最后一部分还通过调用distributed_utils.call_main(cfg, main)对代码的分布式训练的参数进行设置,这里暂时按下不表,call_main()函数的最后通过调用main(cfg, **kwargs)调整到train.py的main()方法中 -
在
main()方法中,通过以下代码完成对model/task/criterion的构建# Setup task, e.g., translation, language modeling, etc. # 任务构建 task = tasks.setup_task(cfg.task) # 检查参数中是否包含criterion assert cfg.criterion, "Please specify criterion to train a model" # Build model and criterion # 这里添加了对分布式训练参数中ddp_backend属性的判断,我们暂时忽略 if cfg.distributed_training.ddp_backend == "fully_sharded": with fsdp_enable_wrap(cfg.distributed_training): model = fsdp_wrap(task.build_model(cfg.model)) else: # 模型构建 model = task.build_model(cfg.model) # 标准构建 criterion = task.build_criterion(cfg.criterion) -
构建任务的步骤:
-
首先调用
fairseq/tasks/__init__.py中的setup_task()方法,这是一个通用的task构建方法def setup_task(cfg: FairseqDataclass, **kwargs): # 首先获取task的name task = None task_name = getattr(cfg, "task", None) if isinstance(task_name, str): # legacy tasks task = TASK_REGISTRY[task_name] if task_name in TASK_DATACLASS_REGISTRY: dc = TASK_DATACLASS_REGISTRY[task_name] cfg = dc.from_namespace(cfg) else: task_name = getattr(cfg, "_name", None) if task_name and task_name in TASK_DATACLASS_REGISTRY: dc = TASK_DATACLASS_REGISTRY[task_name] cfg = merge_with_parent(dc(), cfg) task = TASK_REGISTRY[task_name] # 此时的task包含两个方法,分别是source_dictionary和target_dictionary # source_dictionary方法的返回值为src_dict,目前为空 # target_dictionary方法的返回值为tgt_dict,目前为空 assert ( task is not None ), f"Could not infer task type from cfg. Available argparse tasks: TASK_REGISTRY.keys(). Available hydra tasks: TASK_DATACLASS_REGISTRY.keys()" return task.setup_task(cfg, **kwargs) -
通过调用
task.setup_task()方法进入特定的task构建方法,这里指的是fairseq/tasks/translation.py中的setup_task()方法(translation task)def setup_task(cls, cfg: TranslationConfig, **kwargs): """Setup the task (e.g., load dictionaries). Args: args (argparse.Namespace): parsed command-line arguments """ paths = utils.split_paths(cfg.data) assert len(paths) > 0 # find language pair automatically # 指定cfg中的source_lang属性和target_lang属性 if cfg.source_lang is None or cfg.target_lang is None: cfg.source_lang, cfg.target_lang = data_utils.infer_language_pair(paths[0]) if cfg.source_lang is None or cfg.target_lang is None: raise Exception( "Could not infer language pair, please provide it explicitly" ) # load dictionaries src_dict = cls.load_dictionary( os.path.join(paths[0], "dict..txt".format(cfg.source_lang)) ) tgt_dict = cls.load_dictionary( os.path.join(paths[0], "dict..txt".format(cfg.target_lang)) ) assert src_dict.pad() == tgt_dict.pad() assert src_dict.eos() == tgt_dict.eos() assert src_dict.unk() == tgt_dict.unk() logger.info("[] dictionary: types".format(cfg.source_lang, len(src_dict))) logger.info("[] dictionary: types".format(cfg.target_lang, len(tgt_dict))) # 通过调用cls方法将加载的src_dict和tgt_dict加入到cfg中 return cls(cfg, src_dict, tgt_dict)
-
-
构建模型的步骤:
-
首先通过调用
task.build_model()方法进入translation特定任务的build_model()方法,然后通过super().build_model()调用父类fairseq_task.py中的build_model()方法,再通过models.build_model()调用通用模型(fairseq/models/__init__.py)中的build_model()方法,最后通过model.build_model调用特定模型TransformerModel的build_model()方法 -
TransformerModel类中的build_model()方法主要也是为模型添加一些参数,比如max_source_positions、max_target_positions等,真正构建模型还是在它(TransformerModel)调用的父类(TransformerModelBase)的build_model()方法中# 构建embedding # 这里省略了对share_all_embeddings和merge_src_tgt_embed的判断 encoder_embed_tokens = cls.build_embedding(cfg, src_dict, cfg.encoder.embed_dim, cfg.encoder.embed_path) decoder_embed_tokens = cls.build_embedding(cfg, tgt_dict, cfg.decoder.embed_dim, cfg.decoder.embed_path) # 构建encoder和decoder encoder = cls.build_encoder(cfg, src_dict, encoder_embed_tokens) decoder = cls.build_decoder(cfg, tgt_dict, decoder_embed_tokens)
-
-
以上是关于fairseq学习笔记的主要内容,如果未能解决你的问题,请参考以下文章