Jetpack Compose 深入探索系列二:Compose 编译器
Posted 川峰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Jetpack Compose 深入探索系列二:Compose 编译器相关的知识,希望对你有一定的参考价值。
Jetpack Compose由一系列的库组成,但我们需要重点关注三个特定的库:Compose compiler、Compose runtime 和 Compose UI。
其中 Compose编译器 和 Compose runtime 是Jetpack Compose的支柱。从技术上讲,Compose UI 不是Compose体系结构的一部分,因为运行时和编译器被设计为通用的,并由符合其需求的任何客户端库使用。Compose UI 只是其中一个可用的客户端。还有其他的客户端库正在开发中,比如JetBrains为桌面和Web开发的客户端库。也就是说,浏览Compose UI将帮助我们理解Compose如何提供可组合树的运行时内存表示,以及它最终如何从其中物化真正的元素。

到目前为止,我们已经了解到Compose编译器和Compose runtime一起工作来解锁所有的库特性,但这可能仍然有点太抽象了,因为我们还不太足够熟悉它。关于Compose编译器会采取什么操作使我们的代码符合runtime要求,runtime如何工作,何时触发初始组合和进一步的重组,如何在内存中提供树的表示,如何将这些信息用于进一步的重组……等等,我们可能希望得到更深入的解释。掌握这样的概念可以帮助我们在编写代码时对库的工作方式和期望有一个全面的认识。
Kotlin编译器插件
Jetpack Compose有点依赖于代码生成。在Kotlin和JVM的世界中,通常的方法是通过kapt实现注解处理器,但是Jetpack Compose不同于此。Compose编译器实际上是一个Kotlin编译器插件。这使得库能够将其编译工作嵌入到Kotlin的编译阶段,从而获得关于代码形式的更多相关信息,并加快整个过程。虽然kapt需要在编译之前运行,但编译器插件可以直接内联到编译过程中。
作为一个Kotlin编译器插件也提供了在编译器的前端阶段报告诊断异常的机会,提供了一个非常快速的反馈循环。但是,这些诊断不会在IDE中得到报告,因为IDEA没有直接与插件集成。我们今天在Compose中可以找到的任何IDEA级别的检查都是通过一个单独的IDEA插件添加的,这个插件不与Compose编译器插件共享任何代码。也就是说,只要我们按下编译按钮,前端诊断就会被报告。改进反馈循环是Kotlin编译器前端阶段静态分析的最终好处,Jetpack Compose编译器很好地利用了这一点。
Kotlin编译器插件的另一个巨大优势是,它们可以随意调整现有的源代码(不只是像注解处理器那样添加新代码)。它们能够在这些元素被降级为更底层的产物之前,修改它的输出 IR ,进而可以将其转换为目标平台支持的原语(记住Kotlin是支持多平台的)。这将使Compose编译器能够根据runtime的需要来转换Composable函数。
编译器插件在Kotlin中有着前途无量的未来。许多已知的注解处理器可能会通过KSP逐渐迁移为编译器插件或“轻量级”编译器插件。
如果你对Kotlin编译器插件特别感兴趣,我强烈建议你学习一下KSP (Kotlin符号处理器),谷歌提议将其作为Kapt的替代品。KSP提出了一种规范化的DSL,用于“编写轻量级编译器插件”,任何库都可以依赖它进行元编程。如果你对KSP感兴趣的话,可以参考我的博文:Kotlin 元编程之 KSP 全面突破 以及 Kotlin 元编程之 KSP 实战:通过自定义注解配置Compose导航路由
另外,请注意,Jetpack Compose编译器在很大程度上依赖于IR转换,如果将其作为元编程的广泛实践,可能会有危险。如果所有的注解处理器都被翻译成编译器插件,我们可能会有太多的IR转换,类似的事情可能会破坏语言的稳定。调整/扩充语言总是有风险的。总的来说,这就是为什么KSP可能是一个更好的选择。
Compose 注解
我们首先需要了解的一件事情是如何注解代码,以便编译器能够扫描所需的元素并发挥它的魔力。让我们从了解可用的Compose注解开始学习。
即使编译器插件相比注解处理器可以做更多的事情,两者也有一些共同之处。这方面的一个例子是它们的前端编译阶段,经常用于静态分析和验证。
Compose编译器利用kotlin编译器前端的钩子/扩展点来验证它想要强制执行的约束是否满足,类型系统是否正确处理了@Composable函数、声明或表达式。
除此之外,Compose还提供了其他补充注解,用于在某些特定情况下解锁额外的检查和各种运行时优化或“快捷方式”。所有可用的注解都是由Compose runtime库提供的。
所有的Jetpack Compose注解都是由Compose runtime提供的,因为编译器和runtime模块都很好地利用了这些注解。
@Composable
Compose编译器和注解处理器之间最大的区别在于,Compose可以有效地更改被注解的声明或表达式。大多数注解处理器无法做到这一点,它们必须生成额外的或者同级声明。这就是Compose编译器使用IR转换的原因。@Composable注解实际上改变了事物的类型,并且编译器插件被用于在前端阶段强制执行各种规则,以确保Composable类型不会被视为与非Composable的注解类型对等。
通过@Composable改变声明或表达式的类型会给它一个“内存”。这就是调用 remember 和利用Composer/slot table的能力。它也提供了一个生命周期,使得在其函数体内启动的副作用能够遵从生命周期( eg:跨越重组的作业)。Composable函数还将被分配一个它们将保留的标识,并在生成的树中有一个位置,这意味着它们可以将Node节点发射到Composition组合树中。
简要回顾:Composable函数表示从数据到节点的映射,该节点在执行时被发送到树中。这个节点可以是一个UI节点,也可以是任何其他性质的节点,这取决于我们用来使用Compose runtime的库。Jetpack Compose runtime使用不绑定到任何特定用例或语义的泛型节点类型。
@ComposeCompilerApi
Compose使用这个注解来标记它的某些部分,这些部分只能由编译器使用,其唯一目的是通知潜在用户这一事实,并让他们知道应该谨慎使用它。
@InternalComposeApi
在Compose中,有些api被标记为内部的,因为即使公开的api接口保持不变并冻结到稳定版本,它们也会在内部发生变化。这个注解的范围比语言的internal关键字更广,因为它允许跨模块使用,而Kotlin不支持这个概念。
@DisallowComposableCalls
用于防止在函数内部发生可组合调用。这对于组合函数的内联lambda参数非常有用,因为它们不能安全地在其中包含可组合调用。它最好用于lambdas,因为lambdas不会在每次重组时都被调用。
这方面的一个例子可以在Compose runtime的remember函数中找到。这个Composable函数记住由计算块产生的值。此块仅在初始组合期间计算,任何进一步的重新组合将始终返回已经生成的值。

由于这个注解,在calculation lambda中禁止Composable调用。如果允许,那么它们将在调用(发射)时占用 slot table 中的空间,并且在第一次组合之后将被丢弃,因为lambda不再被调用。
该注解最好用于作为实现细节有条件调用的内联lambdas,但不应该像可组合元素那样是“活的”。之所以需要这样做,是因为内联lambda的特殊之处在于它们“继承”了其父调用上下文的可组合能力。例如,forEach调用的lambda没有标记为@Composable,但是如果forEach本身是在可组合函数中调用的,则可以调用可组合函数。这在forEach和许多其他内联api的情况下是需要的,但在其他一些情况下不需要,如remember,这就是这个注解的用途。
还需要注意的是,这个注解具有“传染性”,即如果你在标记为@DisallowComposableCalls的内联lambda中调用内联lambda,编译器将要求你将该lambda也标记为@DisallowComposableCalls。
正如你可能猜到的那样,这可能是一个你永远都不会在任何客户端项目中使用到的注解,但如果你将Jetpack Compose用于除了 Compose UI 外的其他场景,那么它很可能会变得更加有意义。在这种情况下,你可能需要为runtime编写自己的客户端库,这将要求你遵守运行时约束。
@ReadOnlyComposable
当其应用于一个可组合函数时,这意味着我们知道这个可组合函数的主体永远不会写入composition,只会从它读取。对于主体中的所有嵌套Composable调用也必须保持如此。这允许runtime避免生成不需要的代码,如果Composable能够满足这个假设。
对于任何写入内部composition的Composable,编译器会生成一个“group”来包装它的主体,因此整个group在runtime被触发。这些发出的group为composition提供了关于Composable的必要信息,因此当重新组合需要用不同Composable的数据覆盖它时,它知道如何清除任何已写入的数据,或者如何通过保留Composable的标识来移动这些数据。可以被生成的group有着不同的类型:例如:可重新启动的组,可移动的组……等等。
要了解group究竟是什么,可以想象在选定文本的给定范围的开始和结束处有一对指针。所有组都有一个源码位置的key,用于存储group,从而解锁位置记忆。这个key也是它如何知道在if或else分支条件逻辑之间的不同标识,例如:

它们都是文本,但它们具有不同的标识,因为它们对调用者而言表示不同的意思。可移动的组也有一个语义标识Key,因此它们可以在父group中重新排序。
当我们的可组合对象不写入composition时,生成这些组不会提供任何值,因为它的数据不会被替换或移动。这个注解有助于避免这种情况。
在Compose库中,关于只读组合的例子可能是许多CompositionLocal默认值或委托它们的utilities,如 Material Colors, Typography,isSystemInDarkTheme()函数,LocalContext,任何关于获取应用resources类型的调用(因为它们依赖于LocalContext或LocalConfiguration)。总的来说,它是关于在运行我们的程序时只设置一次的东西,并且希望保持不变,并且可以从树上的Composables中读取。
@NonRestartableComposable
当其应用于函数或属性getter时,它基本上使其成为一个不可重新启动的Composable。
(注意,默认情况下不是所有的组合都是可重新启动的,因为内联组合或具有非Unit返回类型的组合都是不可重新启动的)。
添加该注解时,编译器不会生成允许函数重组或在重组期间跳过所需的引用。请记住,这必须非常谨慎地使用,因为它可能只对非常小的函数有意义,这些函数可能会被重新组合(重新启动)由另一个调用它们的Composable函数调用,因为它们可能包含很少的逻辑,所以对它们来说自我失效没有多大意义。换句话说,它们的无效/重组本质上是由它们的父组件/封闭组件驱动的。
为了“准确性”,应该很少或永远不需要这个注解,但如果您知道这种行为将产生更好的性能,则可以将其用作非常轻微的性能优化。
@StableMarker
Compose runtime还提供了一些注解来表示类型的稳定性。它们是@StableMarker元注解,以及@Immutable和@Stable注解。让我们从@StableMarker开始。
@StableMarker是一个元注解,它注解了其他的注解,比如@Immutable和@Stable。这听起来可能有点多余,但它是为了可重用性,因此它的含义也适用于用它注解的所有注解。
@StableMarker暗示了与最终注解类型的数据稳定性相关的以下要求:
- 对于相同的两个实例,无论何时调用
equals的结果总是相同的 。 - 当被注解的类型的公开属性发生变化时,总是会通知其Composition。
- 被注解的类型的所有公开属性也必须是稳定的。
第一条要求实际上是在表达"现在相等以后就永远相等",第二条要求实际上意味着被注解类的所有公开的 var 属性应该使用 mutableStateOf() 来修饰。
任何用@Immutable或@Stable注解的类型也需要隐含这些要求,因为这两个注解都被标记为@StableMarker,或者换句话说,它们都是作为稳定性的标记。
请注意,这些是我们给编译器的承诺,这样它就可以在处理源码时做出一些假设,但在编译时不会验证它们。这意味着您(开发人员)将决定何时满足所有需求。
也就是说,Compose编译器将尽力推断某些类型何时满足上述要求,并将这些类型视为稳定类型,而不进行注解。在许多情况下,这是首选的,因为它保证是正确的,然而,有两种情况下,直接注解它们是重要的:
- 当它是接口或抽象类的必要契约/期望时。该注解不仅成为对编译器的承诺,而且成为了对实现者的要求。
- 当实现是可变的,但在稳定性假设下以一种可变性是安全的方式实现时。最常见的例子是,如果类型是可变的,因为它有某种类型的内部缓存,但该类型对应的公共API与缓存的状态无关。
@Immutable
此注解应用于类上,作为编译器的严格承诺,即所有公共可访问的类属性和字段在创建后保持不变。注意,这是一个比语言val关键字更强的承诺,因为val只确保属性不能通过setter重新分配,但它可以指向一个可变的数据结构(例如val指向一个类对象,但该对象的数据内容字段可变)。这将打破Compose runtime的期望。换句话说,Compose之所以需要这个注解,本质上是因为Kotlin语言没有提供一种机制(关键字或其他东西)来确保某些数据结构是不可变的。
基于从类型中读取的值在初始化后永远不会改变的假设,运行时可以对智能重组和跳过重组特性应用优化。
可以安全地标记为@Immutable的类的一个比较好的例子是一个只有val属性的数据类,其中没有一个具有自定义getter(否则在每次调用时都会重新计算,并可能每次返回不同的结果,这会使其成为一个不稳定的api被读取),该数据类的所有属性的类型要么是基本类型,要么也是标记为@Immutable的类型。
@Immutable也是一个@StableMarker,如上所述,所以它也继承了它的所有含义。一个被认为是不可变的类型总是遵守为@StableMarker声明的含义,因为它的公开值永远不会改变。@Immutable注解的存在是为了将不可变类型标记为稳定类型。
值得注意的是,不可变类型不会通知组合它们的值发生变化,虽然这是
@StableMarker中列出的要求之一,但它们实际上不必这样做,因为它们的值根本就不会改变,所以它无论如何都满足约束。
@Stable
这个可能比@Immutable要轻松一些。根据其应用到的语言元素不同,它有不同的含义。
当这个注解应用于一个类型时,它意味着该类型是可变的(否则我们将使用@Immutable),并且它只具有由@StableMarker继承的含义。
当@Stable注解应用于函数或属性时,它会告诉编译器,该函数对于相同的输入总是返回相同的结果(纯函数)。只有当函数的参数也是@Stable、@Immutable或基本类型(这些类型被认为是稳定的)时,才有可能这样做。
官方文档中有一个很好的例子可以说明这与runtime有多么相关:当所有作为参数传递给Composable函数的类型都被标记为稳定时,则根据位置记忆比较参数值是否相等,如果所有值都与前一次调用相同,则跳过调用。
可以标记为@Stable的类型的一个例子是,一个对象,其公开属性不会改变,但不能被认为是不可变的。例如,它具有私有可变状态,或者它使用属性委托给MutableState对象,但就外部如何使用它而言,它是不可变的。
再一次,编译器和runtime使用此注解的含义来假设数据将如何演变(或不演变),并在需要的地方采取捷径。同样,除非您完全确定它的含义得到了满足,否则决不应该使用该注解。否则,我们将向编译器提供不正确的信息,这很容易导致运行时错误。这就是为什么建议谨慎使用所有这些注解的原因。
值得强调的是,即使
@Immutable和@Stable注解是具有不同含义的不同承诺,但今天Jetpack Compose编译器以相同的方式对待它们:启用和优化智能重组和跳过重组。
@Stable实际上是适用于从技术上讲是可变的,但主观上我们认为它不会变的类。
注册编译器扩展
一旦我们了解了runtime提供的最相关的注解,就可以了解Compose编译器插件是如何工作的,以及它是如何使用这些注解的。
Compose编译器插件做的第一件事是使用ComponentRegistrar将自己注册到Kotlin编译器管道中,这是Kotlin编译器为此提供的机制。ComposeComponentRegistrar为不同的目的注册一系列编译器扩展。这些扩展将负责简化库的使用,并为runtime生成所需的代码。所有注册的扩展都将与Kotlin编译器一起运行。
Compose编译器还根据启用的编译器标志注册一些扩展。使用Jetpack Compose的开发人员有机会启用一些特定的编译器标志,允许他们启用一些功能,如实时文字,包括生成代码中的源信息,以便android Studio和其他工具可以检查组合,优化记忆函数,抑制Kotlin版本兼容性检查,或者在IR转换中生成欺骗方法。
如果我们有兴趣深入了解编译器插件是如何注册编译器扩展的,或者其他进一步的探索,请记住,我们可以在 cs.android.com上浏览源代码。
Kotlin编译器版本
Compose编译器需要一个非常特定的Kotlin版本,因此它会检查所使用的Kotlin编译器版本是否与所需的版本匹配。这发生在第一次检查中,因为如果不匹配的话它将是一个大的障碍。
有机会通过使用suppressKotlinVersionCompatibilityCheck编译器参数来绕过这个检查,但这是我们自己承担的风险,因为这样我们就可以使用任何版本的Kotlin运行Compose,这很容易导致严重的不一致。如果我们考虑Kotlin编译器后端在最新Kotlin版本中的发展,就会发现更多不一致。添加这个参数可能是为了允许针对实验性的Kotlin发行版等运行和测试Compose。
静态分析
遵循一个普通编译器插件的标准行为,首先发生的是linting。静态分析是通过扫描源代码,搜索库注解,然后执行一些重要的检查,以确保它们被正确的使用。我说的正确是指runtime期望的方式。在这里,通过编译器插件可以访问的上下文跟踪报告相关的警告或错误。这与idea集成得很好,因为它已经准备好在开发人员仍在输入时内联显示这些警告或错误。如前所述,所有这些验证都发生在编译器的前端阶段,这有助于Compose为开发者提供尽可能快的反馈循环
让我们来看看执行的一些最重要的静态检查。
静态检查
一些注册的扩展以静态检查器的形式出现,它们将指导开发人员进行编码。Jetpack Compose 通过扩展注册调用、类型和声明的检查器。它们将确保库的正确使用,显然会对该库想要解决的问题持有主观看法。
在Kotlin编译器的世界中,根据我们想要检查的元素,有不同类型的分析程序可用。有用于类实例化、类型、函数调用、弃用调用、契约、闭包捕获、中缀调用、协程调用、操作符调用等的检查器,这些检查器允许编译器插件分析来自输入源的所有相应元素,并在需要时报告信息、警告或错误。
考虑到所有已注册的检查器都运行在Kotlin编译器的前端阶段,因此它们的速度应该非常快,并且不包含消耗大量cpu的操作。这是开发人员的责任,所以要始终记住,这些检查将在开发人员输入时运行,我们不想创建一个糟糕的用户体验是关键。我们希望实现轻量级检查器。
调用检查
Compose 中注册的不同类型的检查器之一是用于验证调用的检查器。Compose 编译器已经设置了静态调用检查,用于在许多不同的上下文中验证组合函数调用,比如像@DisallowComposableCalls或 @ReadOnlyComposable范围内调用组合函数时做的那样。
Call checker是一个编译器扩展,用于对代码库中的所有调用执行静态分析,因此它提供了一个递归调用的检查函数,用于访问源码中被视为调用的所有PSI元素。或者换句话说:PSI树上的所有节点。它是基于访问者模式的实现。
其中一些检查需要比它们正在访问的当前语言元素更广泛的上下文,因为它们可能需要知道从哪里调用Composable。这意味着分析单个PSI节点是不够的。收集这样的信息需要从访问过的不同元素中记录更小的信息,并在进一步的检查中执行更复杂的验证。为此,编译器可以方便地在上下文跟踪中记录该信息。这可以扩大检查的范围,并能够查找包含的 lambda 表达式、try/catch 块或类似的相关事物。
以下是一个编译器调用的例子,它记录与上下文相关的信息到跟踪信息中,并使用它在标有@DisallowComposableCalls的上下文中调用Composable时报告错误。
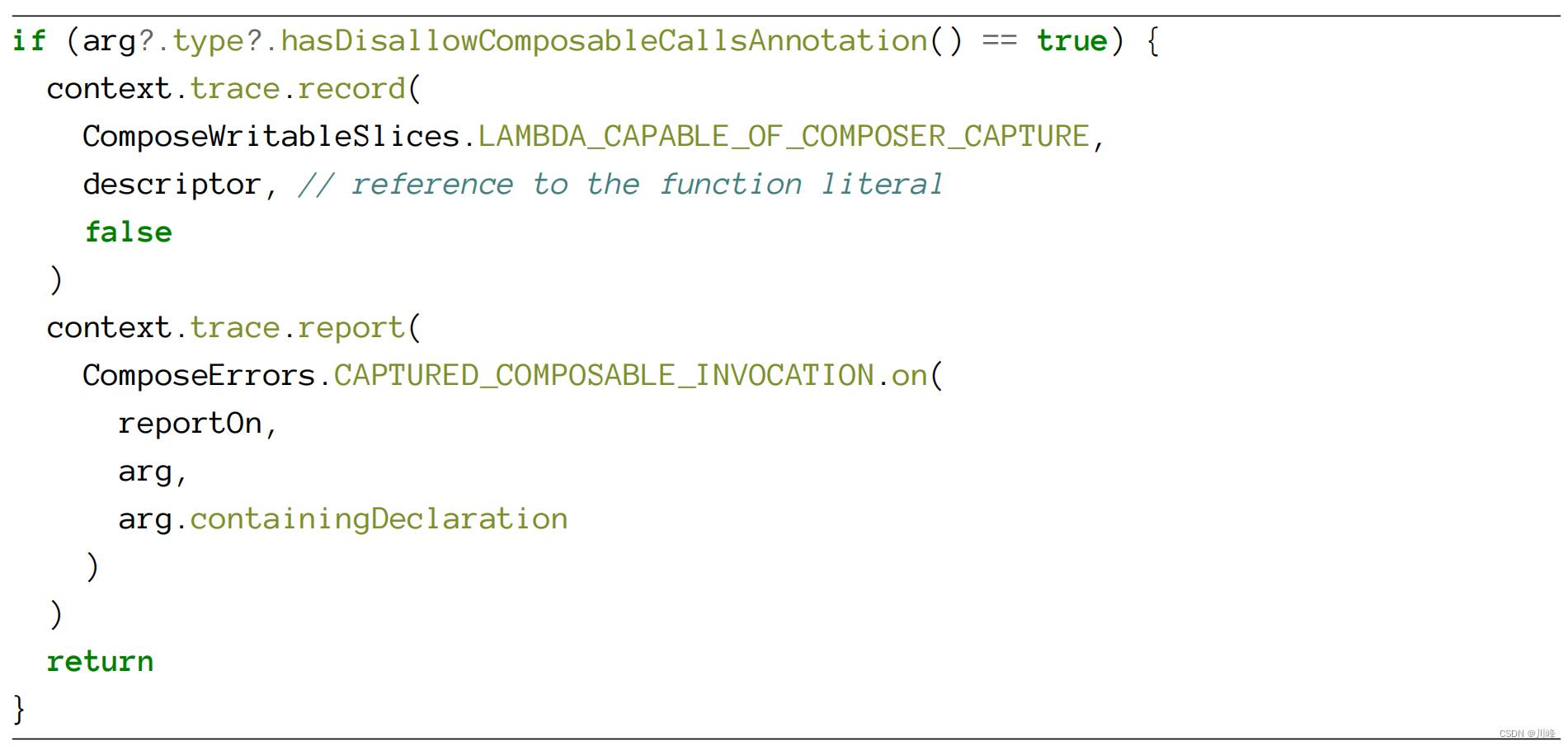
上下文和上下文跟踪在每次调用check函数时都可用,实际上,我们也可以使用相同的跟踪来报告错误、警告或信息消息。我们可以将跟踪理解为一个可变的结构,我们可以填充相关信息以进行整体分析。
其他检查则更简单,只需要当前访问的元素可用的信息,所以它们执行其操作并返回。在每次检查调用时,插件将匹配当前节点的元素类型,并根据其进行简单的检查并返回(如果一切正确),报告错误 (如果需要), 记录相关信息到上下文跟踪中,或者再次递归到该节点的父级,以继续访问更多节点并收集更多信息。沿途执行不同注解的不同检查。
Compose编译器检查的一件事是,Composables不会从不被允许的地方调用,比如在try/catch块中调用(不支持),从未标记为@Composable的函数中调用,或者从带有@DisallowComposableCalls注解的lambdas中调用。 请记住,该注解是用于避免在内联lambda中使用Composable注解的。
对于每个可组合调用,编译器都会访问PSI树,检查它的调用者、它的调用者的调用者,等等,以确认这个调用的所有需求都得到了满足。所有场景都要考虑在内,因为父元素可以是lambda表达式、函数、属性、属性访问器、try/catch块、类、文件等等。
PSI为前端编译器阶段建模了语言的结构,因此我们必须记住,它理解代码的方式完全是语法的和静态的。
对于这些检查来说,考虑内联函数也很重要,因为只要内联 lambda 的调用者也是可组合的,就必须允许从内联 lambda 中调用可组合函数。编译器会检查调用Composable函数的任何内联lambdas是否也在调用堆栈的某个级别上被一个Composable函数包围。
另一个调用检查是在需要或预期的地方检测可能缺少Composable注解的情况,因此它可以方便地要求开发人员添加这些注解。 eg:如果在lambda中调用了一个Composable函数,编译器会友好地建议将Composable注解也添加到该lambda中。静态分析检查的存在是为了指导开发人员编写代码,所以它并不是完全禁止,有时它们可以推断和建议需要什么,或者告诉我们如何改进代码。
对于注解为@ReadOnlyComposable的可组合函数,也有静态调用检查。它们只能调用其他的只读组合对象,否则我们就违反了优化的约定,只读组合对象只能从组合对象中读取,而不能写入组合对象。考虑到这必须在可组合的所有深度级别上实现,因此访问者模式会很有用。
我们可以找到的另一个检查是禁止使用 Composable 函数引用,因为目前 Jetpack Compose 还不支持。
类型检查
有时我们会将类型注解为Composable,而不仅仅是函数。为此,Compose编译器有一个与类型推断相关的检查,因此当期望使用@Composable注解的类型,但发现了非注解的类型时,它就会报告错误。类似于上面提到的函数调用检查。该错误将打印推断出的类型和期望的类型以及它们的注解,以更清晰地表明区别。
声明检查
调用和类型的检查是必要的,但并不足够。声明检查也是任何Compose代码库的一部分。例如,属性、属性访问器、函数声明或函数参数需要进行分析。
属性、属性 getter 和函数可以被重写,即使它们被注解为 Composable。任何这些 KtElement 的重写都会被 Compose 编译器检查是否也被注解为 Composable,以保持一致性。
另一个可用的声明检查是确保 Composable 函数不是 suspend 的,因为不支持 suspend。 suspend 有不同于 @Composable 的含义,即使两者都可以被视为某种语言原语,但它们被设计用于表示完全不同的东西。到目前为止,这两个概念还不能同时得到支持。
通过声明检查,像 Composable 注解的main函数或者 Composable 注解的属性的 backing fields 这样的东西也是被禁止的。
诊断抑制
编译器插件可以将诊断抑制器注册为扩展,以便它们可以基本上消除一些特定情况下的诊断。例如:静态检查通知的错误。这通常发生在编译器插件生成或支持Kotlin编译器不接受的代码时,这样编译器就可以绕过相应的检查并使其正常工作。
Compose 注册了一个 ComposeDiagnosticSuppressor,用于绕过一些语言限制(否则会导致编译失败),从而释放一些特定的用例。
其中之一的限制是关于在调用点上使用“非源代码注解”注解的内联 lambda。即使用保留 BINARY 或 RUNTIME 的注解。这些注解会一直存在直到输出二进制文件,不像SOURCE注解那样。由于内联 lambda 在编译时会被实际内联到其调用者中,它们不会被存储在任何地方,因此在那一点上将不再有任何需要注解的内容。这就是为什么 Kotlin 禁止这样做,并报告以下错误:
The lambda expression here is an inlined argument so this annotation cannot be stored anywhere.
(这里的lambda表达式是一个内联参数,因此这个注解不能存储在任何地方。)
下面是会触发该错误的示例代码:

Compose编译器只会对使用@Composable注解的情况抑制此检查,这样我们就可以编写以下类似的代码:
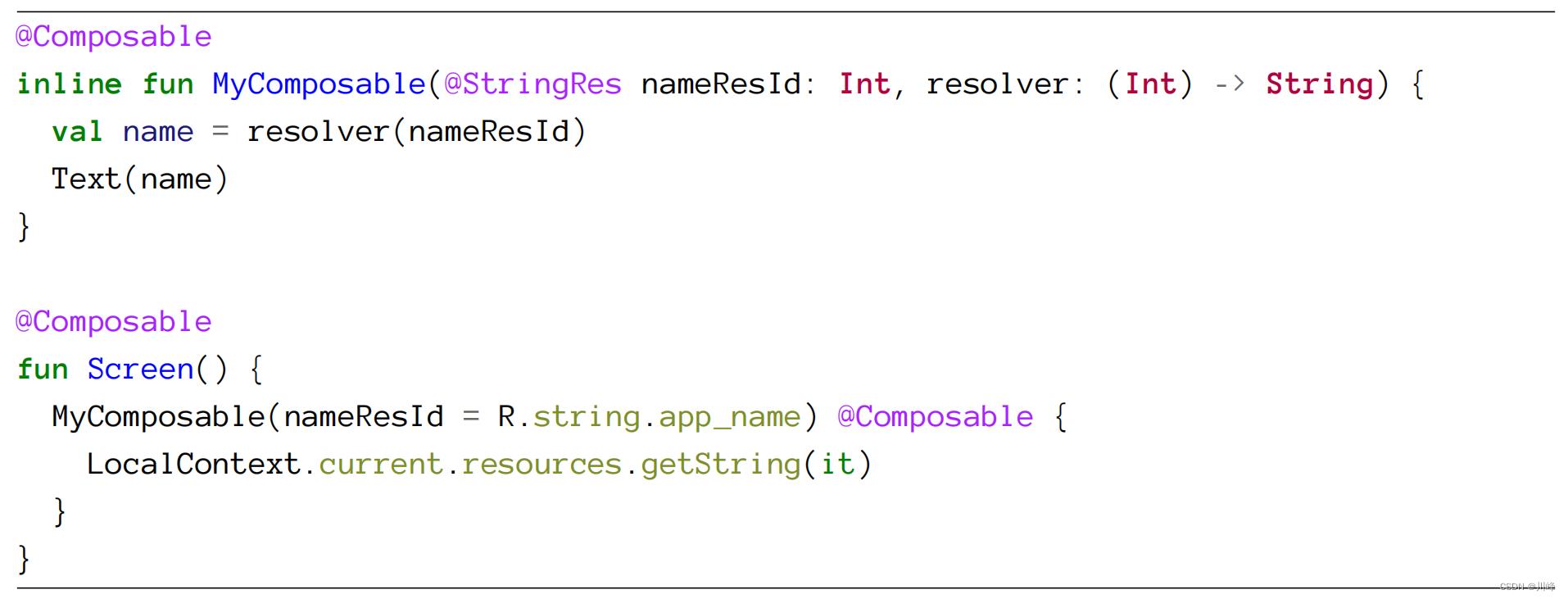
这样我们就可以在调用函数时将 lambda 参数标注为 @Composable,而不一定非要在函数声明时这么做。这使得该函数具有更灵活的契约。
使用 suppressor 时,可以绕过另一个与 Kotlin 语言限制相关的限制,即在 Kotlin 编译器不支持的地方允许使用命名参数,但仅当它们所属的函数被注解为 @Composable 时。
函数类型就是一个例子。Kotlin不允许在函数类型上使用命名参数,但如果该函数被注解为 @Composable,则Compose会使其成为可能:
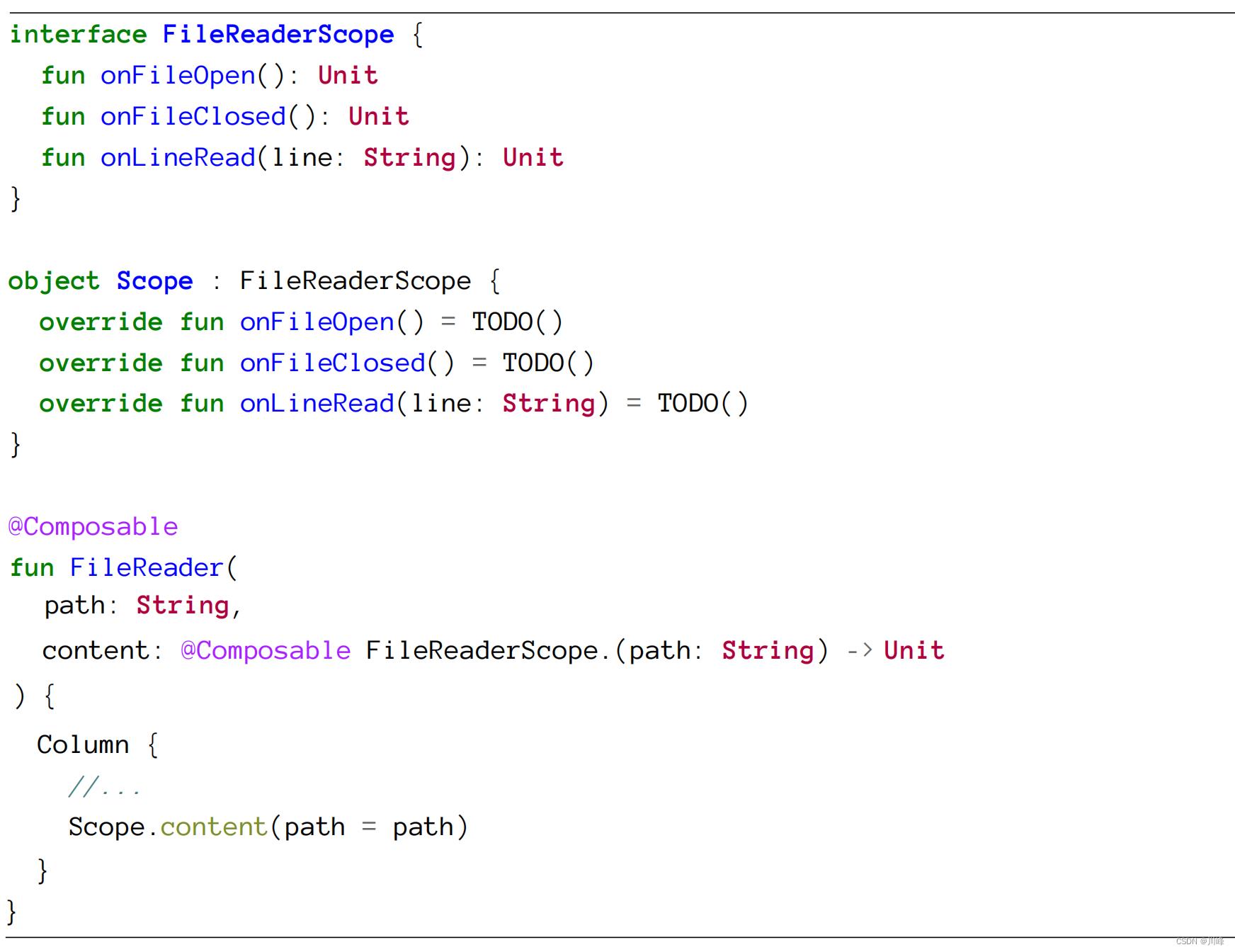
如果我们移除@Composable注解,我们会得到一个类似这样的错误:
Named arguments are not allowed for function types.
相同的要求也适用于其他情况,例如预期类的成员。请记住,Jetpack Compose旨在成为多平台的,因此运行时应当明确地接受被标记为@Composable的expect函数和属性。
runtime 版本检查
在代码生成之前,我们已经安装好了所有的静态检查器和诊断抑制器。接下来要进行的第一件事是检查使用的 Compose runtime 版本。Compose 编译器需要 runtime 的最低版本,因此它会进行检查,确保 runtime 没有过时。它可以检测到 runtime 缺失和过时的情况。
一个 Compose 编译器版本可以支持多个运行时版本,只要它们高于所支持的最小版本。
这是第二次版本检查。第一次是针对 Kotlin 编译器的版本的检查,然后第二次才是针对 Jetpack Compose runtime的版本的检查。
代码生成
最后,编译器将进入代码生成阶段。这是注解处理器和编译器插件的另一个共同特点,因为两者都经常用于合成便于我们的runtime库使用的代码。
Kotlin IR
正如前面所解释的,编译器插件不仅可以生成新代码,而且可以修改源代码,因为它们可以访问语言的中间表示形式(IR),在生成目标平台的最终代码之前进行修改。这意味着编译器插件可以替换参数、添加新参数、重构代码结构,然后再“提交”它。这一过程发生在 Kotlin 编译器的后端阶段。很可能你已经猜到了,这正是 Compose 为每个 Composable 调用 “注入” 隐式额外参数 Composer 所做的事情。
编译器插件可以以不同的格式生成代码。如果我们只针对 JVM,可以考虑生成兼容 Java 字节码,但随着 Kotlin 团队最新的计划和重构向着将所有 IR 后端稳定化并将其规范化为所有平台的单个后端的方向发展,更有意义的是生成 IR。请记住,IR 作为语言元素的表示形式,它是与目标平台无关的“中间表示”。这意味着生成 IR 将使 Jetpack Compose 生成的代码多平台化。
Compose编译器插件通过注册IrGenerationExtension的实现来生成IR。IrGenerationExtension是由Kotlin编译器提供的扩展,用于生成通用IR后端。
如果您想深入学习 Kotlin IR,推荐查看 Brian Norman 的这个系列视频,它涵盖了 Kotlin IR 和编译器插件创建主题的讲解。深入学习 IR 超出了本文的能力范围。
Lowering
“Lowering”这个术语指的是编译器可以将更高级或更先进的编程概念转换为更低级和更基本的概念的翻译。在 Kotlin 中,这是非常常见的,因为 Kotlin 有一种语言的中间表示(IR),它能够表达非常先进的概念,然后需要将它们翻译为更低级别的基本概念,然后才能将它们转换为 JVM 字节码、javascript、LLVM 的 IR 或其他平台的字节码。Kotlin 编译器有一个这样的过程。将高级概念转换为更低级概念也可以被理解为一种标准化的形式。
Compose编译器需要将其支持的某些概念降低到运行时可以理解的表示形式。降低的过程是Compose编译器插件的实际代码生成阶段。在这个阶段,它会访问IR树中的所有元素,并根据运行时的需要随意调整IR。
以下是接下来会介绍的在降低过程中发生的一些有意义的例子的简要总结概述:
- 推断类的稳定性并添加必要的元数据以在运行时了解它。
- 将实时文字表达式转换为访问可变状态实例,使得运行时可以反映源代码的更改而无需重新编译(实时文字特性)。
- 封装Composable函数体,处理以下情况:
- 生成控制流的不同类型的组(可替换组,可移动组等)。
- 实现默认参数支持,使它们可以在函数生成的组的作用域内执行,而不是依赖于Kotlin默认参数支持。
- 将函数设计为可跳过重组。
- 将与状态更改相关的信息向下传播到树中,以便在更改时自动进行重新组合。
接下来让我们学习Jetpack Compose编译器插件应用的各种降级方式。
类的稳定性推断
智能重组(smart recomposition)指的是当Composable函数的输入没有改变且这些输入被认为是稳定时,跳过重新组合。稳定性在这个意义上是一个非常重要的概念,因为它意味着Compose runtime可以安全地读取和比较这些输入,以在需要时跳过重新组合。稳定性的最终目标是帮助runtime。
按照这种思路,让我们回顾一下一个稳定类型必须满足的属性:
- 相同的两个实例的 equals 调用始终返回相同的结果。这意味着比较是一致的,因此运行时可以依赖它。
- 当类型的公开属性更改时,总是会通知Composition组合。否则,我们可能会遇到输入与最新状态不同步的情况。为了确保不会发生这种情况,总是针对此类情况触发重新组合。智能重组合无法依赖此输入。
- 所有拥有基本数据类型的公开属性,或者拥有同样被视为稳定的类型的公开属性。
默认情况下,所有基本类型都是稳定的,String类型和所有函数类型也是稳定的。这是因为根据定义,它们是不可变的。因为不可变类型不会改变,所以它们也不需要通知组合。
我们还了解到,有些类型不是不可变的,但可以被Compose假设为稳定的,它们可以用@Stable 进行注解。其中一个例子是MutableState,因为每当Compose改变时都会被通知,因此依赖它进行智能重组是安全的。
对于我们在代码中创建的自定义类型,我们可以判断它们是否符合上面列出的属性,并方便地使用@Immutable或@Stable注解手动将它们标记为稳定类型。但依靠开发者履行契约是相当危险的,而且很难长期维持。相反,自动推断类的稳定性是可取的。
Compose就是这样做的。推断稳定性的算法在不断进化,但它在沿着 访问每个类并为其合成一个名为@stabilityinfer的注解 的方向前进。它还添加了一个合成的 static final int $stable 值,用于编码类的相关稳定性信息。这个值将帮助编译器在后面的步骤中生成额外的机制,以确定类在运行时的稳定性,因此Compose可以确定依赖于这个类的Composable函数是否需要重新组合。
为了推断一个类的稳定性,Compose考虑了不同的东西。当类的所有字段都是只读且稳定时,类型被推断为稳定。将field引用为所产生的JVM字节码。像 class Foo 或 class Foo(val value: Int) 这样的类将被推断为稳定的,因为它们没有字段或只有稳定字段。然后像 class Foo(var value: Int) 这种将被推断为不稳定的。
但是类的泛型类型参数也可能影响类的稳定性,例如:

在这种情况下,T 被用于类的参数之一,因此 Foo 的稳定性将依赖于传递给 T 的类型的稳定性。但鉴于T 不是具象化的类型,它在运行时之前都是未知的。因此,一旦已知传递给 T 的类型,就需要存在某种机制来确定类在运行时的稳定性。为了解决这个问题,Compose编译器计算并在StabilityInferred 注解中放入一个位掩码(bitmask),该注解表示在运行时计算该类的稳定性应该依赖于其绑定的类型参数的稳定性。
但是拥有泛型类型并不一定意味着不稳定。编译器知道,例如像:class Foo<T>(val a: Int, b: T) val c: Int = b.hashCode() 这样的代码是稳定的,因为hashCode总是为同一个实例返回相同的结果。这是契约的一部分。
对于由其他类组成的类,如 class Foo(val bar: Bar, val bazz: Bazz),稳定性被推断为所有参数稳定性的组合。这种情况会通过递归来解决。
像内部可变状态这样的东西也会使类不稳定。其中一个例子如下:

这种状态会随着时间的推移发生变化,即使它是由类本身在内部发生变化。这意味着运行时并不能真正的相信它会总是保持一致不变的。
总的来说,Compose编译器只有在能够证明一个类型是稳定的时候才会考虑它。例如:一个接口被认为是不稳定的,因为Compose不知道它将如何实现。
再来看一个示例代码:

在这个例子中,我们得到一个List作为参数,它能以可变的方式实现(它可以是List也可以是MutableList实现)。对编译器来说,如果假设我们只会使用不可变的List来实现它,这是非常不安全不靠谱的。这种情况下推断会变得及其困难,所以它会直接假设它是不稳定的。
另一个例子是具有可变公共属性的类型,其实现可以是不可变的。这些默认情况下也被认为是不稳定的,因为编译器不能推断那么多。
这有点让人困惑,因为很多时候这些东西可以被实现为不可变的,对于 Compose runtime 来说,这应该足够了。因此,如果我们输入到可组合函数的模型被 Compose 编译器认为是不稳定的,我们仍然可以显式地将它标记为@Stable,这表示你在拍着胸脯告诉 Compose :你把心放肚子里,出了事情我兜着。官方文档给出了如何这样做的一个例子:

类稳定性推断算法涵盖了更多的情况。如果需要了解对于这个特性所涵盖的所有情况,建议阅读ClassStabilityTransform的库测试。
请记住,编译器如何推断稳定性的内部算法实现可能会随着时间的推移而变化和改进。好的一点是它对库的使用者始终是透明的。
启用实时字面量
我们可以传递给编译器的标志之一是实时字面量。随着时间的推移,这个特性已经有了两个实现, liveLiterals(v1) 或 liveLiteralsEnabled (v2) ,所以你可以选择启用其中一个标志。
实时字面量是一个允许 Compose 工具能够在预览中实时反映变化,而不需要重新编译的功能特性。合成编译器所做的是将这些表达式替换为从MutableState中读取其值的新版本。这允许运行时立即收到更改通知,而不需要重新编译项目。正如库kdocs所揭露的:
Compose 编译器所做的是将这些表达式替换为从 MutableState 中读取其值的新版本。这允许 runtime 立即收到更改通知,而不需要重新编译项目。正如官方文档中所描述的:
“This transformation is intended to improve developer experience and should never be enabled in a release build as it will significantly slow down performance-conscious code.”
( 这种转换旨在改善开发人员的体验,永远不应该在发布版本中启用,因为它会显著降低注重性能的代码的速度。)
Compose编译器将为我们代码库中的每个常量表达式生成唯一的id,然后它将所有这些常量转换为属性getter,从每个文件中持有的某个MutableState读取到生成的单个类。在运行时,有一些api可以使用生成的key获取这些常量的值。
下面是一个从官方文档中提取的示例:

它会被转换成下面这样:
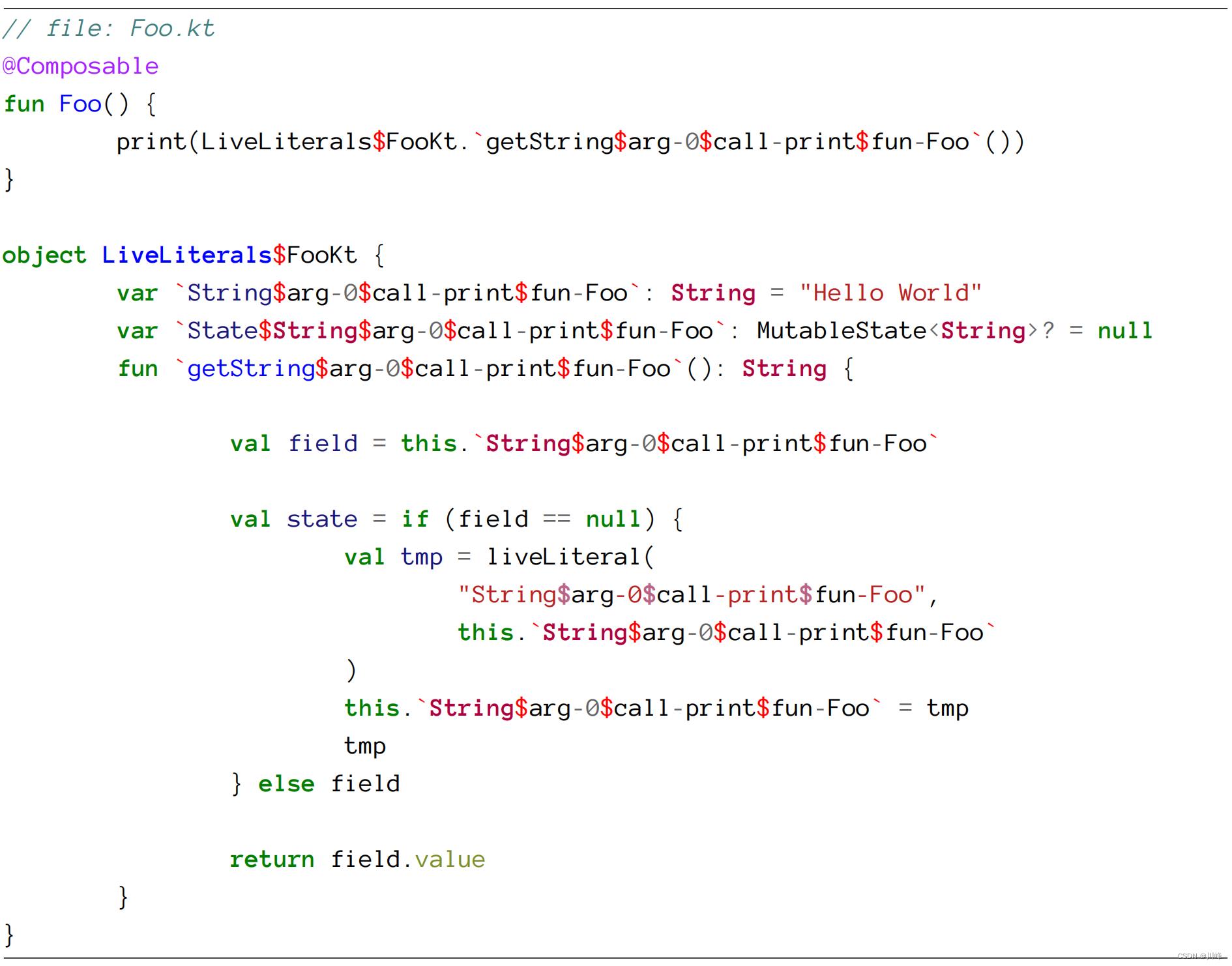
我们可以看到常量是如何被getter替换的,getter从MutableState读取到相应文件生成的单例中。
Compose lambda 记忆
这一步骤生成方便的IR,以教导runtime如何优化传递给可组合函数的lambda函数的执行。这项工作是针对两种类型的 lambda 完成的:
- 非 Composable 类型的 lambdas : 编译器通过将每个lambda包装到一个
remember调用中来生成记忆化所需的IR。可以想象一下我们传递给可组合函数的回调。remember允许稍后调用slot table来存储和读取这些 lambda 函数。 - Composable 类型的 lambdas : 编译器生成的IR会将它们包装起来,并添加相关信息,以便教导runtime如何将表达式存储到Composition中并从其中读取。这与使用
remember的最终目标相同,但并不使用它。一个常见的例子是,我们会向 Compose UI 节点中传递 Composable 类型的contentlambdas 。
非 Composable 类型的 lambdas
此操作优化传递给可组合函数的lambda调用,使它们可以被重用。当 lambda 不捕获任何值时,Kotlin 已经通过将其建模为单例来优化了它们,因此整个程序只有一个可重用实例。但是,当 lambda 捕获值时,这种优化就不可能了,因为这些值可能每次调用都不同,因此每个 lambda 需要不同的实例。对于后者这种特定情况,Compose 更加智能。让我们通过一个例子来探讨这一点。

这里,onClick 是一个标准的 Kotlin lambda,传递给了一个可组合函数。如果我们从调用处传递给它的 lambda 捕获了任何值,Compose 有能力教导 runtime 如何记忆它。基本上,这意味着将其包装成一个 remember 调用。这是通过生成的 IR 完成的。只要这些值是稳定的,此调用就会基于它们捕获的 lambda 表达式进行记忆。这使得 runtime 可以重用已经存在的 lambda,而不是创建新的 lambda,只要它们捕获的值匹配(包括输入参数)。
要求捕获的值稳定的原因是,它们将用作
remember调用的条件参数,因此它们必须是能用于比较的可靠的值。
请注意,记忆化的 lambda 不能是内联的,因为否则在编译时,它们在调用者处内联之后就没有什么可以记忆的了。
此优化仅适用于捕获值的 lambda。如果它们不捕获任何值,Kotlin 的默认优化——将其表示为单例——就足够了。
如上所述,记忆化是基于 lambda 捕获的值完成的。在为表达式生成 IR 时,编译器将在返回类型匹配记忆表达式类型的 remember 调用之前添加一个调用,并将泛型类型参数添加到 remember<T>... 调用中,以匹配表达式返回类型。接着,它将添加所有被 lambda 捕获的值作为条件参数:remember<T>(arg1, arg2...),以便于比较,最后,将添加表达式的 lambda:remember<T>(arg1, arg2..., expression) 作为尾随 lambda。
使用捕获的值作为条件参数将确保它们被用作记忆表达式结果的 key,因此每当它们变化时都将被无效化。
传递给 Composable 函数的 自动记忆化的 lambdas,解锁了在重组(recomposition)发生时可以重用 lambdas 的能力。
Composable 类型的 lambdas
Compose 编译器还能够记忆 Composable lambdas。鉴于 Composable lambdas 的“特殊”实现方式,实现细节可能略有不同。但最终目标是相同的:将这些 lambdas 存储到 slot table 中并读取它们。
下面是一个可以被记忆的 Composable lambda 的示例:

为此,lambda 表达式的 IR 被调整。
首先会调用一个带有特定参数的 composable 工厂函数:composableLambda(...)。
第一个添加的参数将是当前的 $composer,因此它会按预期进行转发。即 composableLambda($composer, ...)。
然后,它会添加一个key参数,该参数通过从 Composable lambda 的完全限定名称的hashcode 以及表达式起始偏移量(也就是它在文件中的位置)的组合获得,以确保key是唯一的。即 位置记忆 。此时生成的IR调用将变成:composableLambda($composer, $key, ...).
然后会添加一个名为 shouldBeTracked 的布尔型参数,该参数用于确定该 Composable lambda 调用是否需要被追踪。当 lambda 没有捕获值时,Kotlin 将其转换为单例实例,因为它们永远不会改变。这也意味着它们不需要被 Compose 追踪。因此,shouldBeTracked 参数的值可能为 false。然后生成的IR调用会变成:composableLambda($composer, $key, $shouldBeTracked, ...)。
之后可以添加一个关于表达式参数个数的可选参数(arity),只有在参数个数超过22个时(神奇数字),才需要使用这个参数。此时生成的IR调用会变成:composableLambda($composer, $key, $shouldBeTracked, $arity, ...)。
最后,它将 lambda 表达式本身作为包装器的最后一个参数添加(即将block代码块作为尾随lambda)。最终生成的IR调用会变成:composableLambda($composer, $key, $shouldBeTracked, $arity, expression) 。
Composable 工厂函数的目的很简单:添加一个可替换的group组到组合中,以便使用生成的key来存储 lambda 表达式。这就是 Compose 如何告诉 runtime 存储和检索 Composable 表达式的。
Compose 还可以对不捕获值的 Composable lambdas 进行优化,与 Kotlin 使用单例的方式相同:通过使用单例表示这些 lambda。为此,它为每个文件生成一个合成的内部对象 “internal object ComposableSingletons” ,而 Composable lambdas 就被保存在其中。该对象将保留或者说记忆对这些 Composable lambdas 的静态引用、以及getter,以便稍后检索它们。
Composable lambdas 有最终的优化,实现方式类似于 MutableState。我们可以把 @Composable (A, B) -> C 的 Composable lambda 看作 State< @Composable (A, B) -> C > 来等价实现。在调用 lambda 的地方 (lambda(a, b)) 就可以被等价替换成 lambda.value.invoke(a, b)。
这是一种优化。它为所有 Composable lambda 创建了一个快照状态对象,使 Compose 能够更智能地基于 lambda 的变化重组子层次结构。这最初被称为 “donut-hole skipping”(跳过甜甜圈空心),因为它允许更新树的“高”部分的 lambda,而 Compose 只需要在实际读取此值的树的“低”部分重新组合。这最终成为了特定的 lambda 的良好权衡,因为它们的自然使用会导致实例被频繁传递,而且通常传递到较“低”层次的结构中,而从未实际“读取”它们的值(调用它们)。
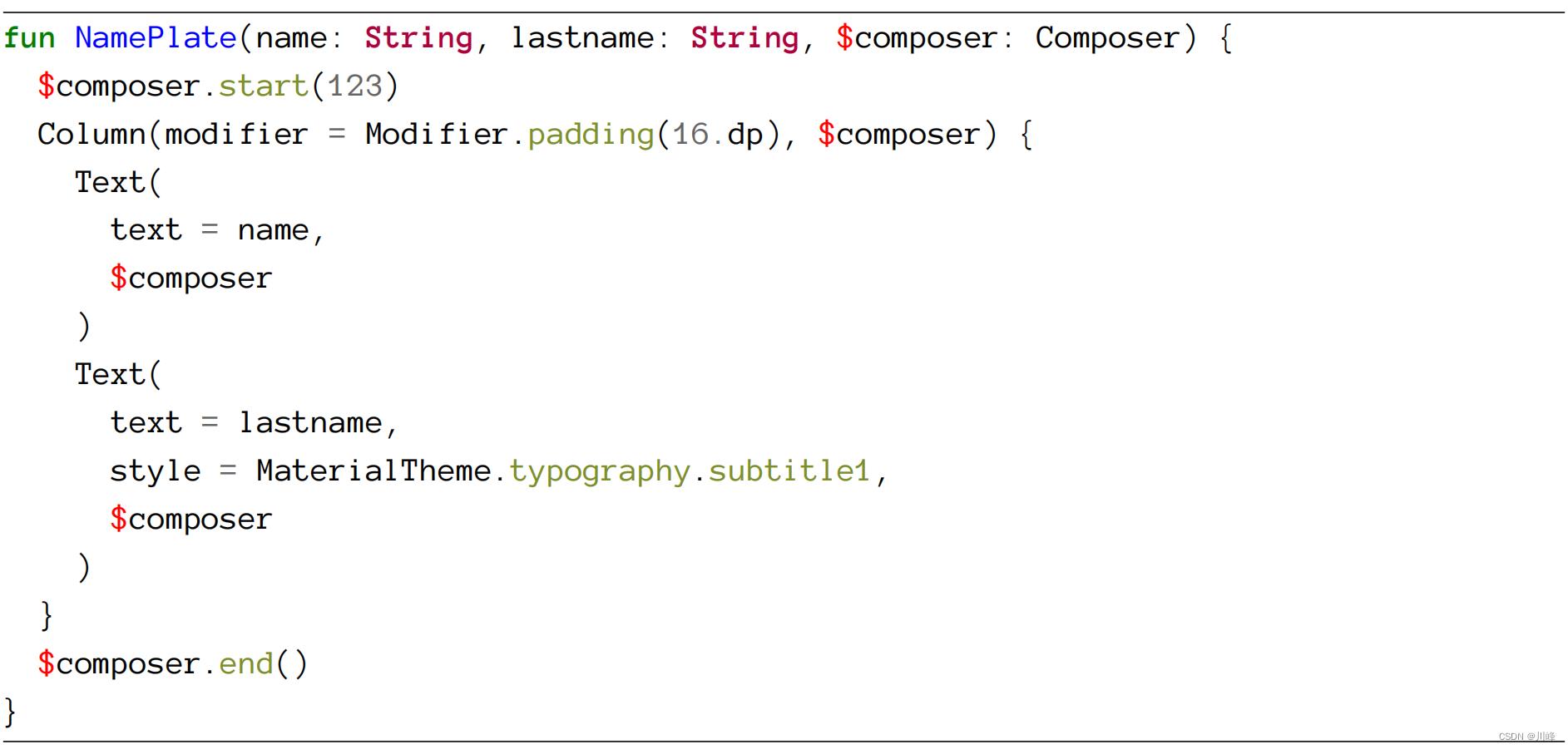
Composer 注入
在这个步骤中,Compose编译器将所有Composable函数替换为新版本,并添加一个额外的Composer合成参数。该参数也会被转发到代码中的每个Composable调用中,以确保它始终在树的任何位置可用。这还包括对Composable lambdas的调用。
这还需要一些类型重映射的工作,因为当编译器插件添加额外参数时,函数类型也会发生变化。
这个步骤使得Composer对于任何子树可用,为具体化可组合树并保持其更新提供了所需的所有信息。
这里有一个例子。
没有被标记为 @Composable 的内联 lambda 函数不会被转换,因为它们在调用者处被内联后会在编译时消失。同样,expect 函数也不会被转换。这些函数在类型解析时被解析为实际函数,这意味着后者在任何情况下都将被转换。
比较传播 (Comparison propagation)
我们已经学习了编译器如何注入 $composer 额外参数并将其转发到所有 Composable 调用。除此之外,还有一些额外的元数据被生成并添加到了每个 Composable 中。其中之一就是 $changed 参数。该参数用于提供有关当前 Composable 的输入参数是否自上次组合以来发生了更改的线索。这将允许跳过重组的能力实现。

这个参数是由代表每个函数输入参数的条件的比特位的组合合成的。每 N 个输入参数(大约是10个)会编码对应一个 $changed 参数,这受到使用的位数的限制。如果 Composable 函数恰好有更多的参数,就会添加2个或更多标志。使用比特位的原因是处理器天生擅长于此。
携带这些信息可以让 runtime 进行某些特定的优化:
-
当输入参数被确定为静态的时候,它可以跳过
equals比较以检查输入参数是否与其最新存储的值不同。$changed参数的位掩码提供了这个信息。例如,如果输入参数是像上面代码片段中的String字面量,或者常量,或其他类似的。那么这个标志上的位将告诉 runtime 它的值在编译时已知,因此它在运行时永远不会改变,因此 runtime 可以避免比较它。 -
还有一些情况,参数的状态从上次组合以来永远不会发生变化,或者如果改变了,它的比较操作已经被树中的父Composable执行过了。这意味着不需要重新比较它。在这种情况下,参数的状态被认为是“确定的”。
-
对于其他任何情况,参数的状态被认为是“不确定的”,因此 runtime 可以直接进行比较(使用
equals),并将其存储在slot table中,以便稍后始终可以找到最新的结果。这种情况下的比特值是0,也就是默认情况。当$changed参数的值为0时,也就是在告诉 runtime 要做应该做的所有的工作(而不是采取任何捷径)。
这是注入了 $changed 参数并添加了处理逻辑后的 Composable 函数体示例:

这里有一些比较技术性的操作,但是我们可以简单解释一下这个 Composable 函数的结构。在函数内部,定义了一个本地变量 $dirty 来存储参数是否发生了变化。这个变量的值是通过比较 $changed 参数和之前储存在 slot table 中的值来决定的。如果该值被认为是“脏”的(即发生了变化),则会调用函数主体进行重新组合。否则,Composable 将跳过重新组合。
由于重新组合可能会发生多次,携带关于输入状态如何演变的信息可以潜在地节省大量计算时间和空间。通常,参数通过许多可组合函数传递,Compose不希望每次都存储和比较它们,因为每次这样做都会占用slot-table空间。
在调用者传递$changed参数给我们的可组合函数时也一样,这个可组合函数也有责任将它所拥有的有关任何参数的信息向下传递。这就是所谓的“比较传播”。在组合期间,我们在函数体中已经有了这些信息,因此如果我们已经知道某个输入参数发生了变化,或者是静态的或其他状态,我们可以将这些信息转发到任何子组合函数的$changed参数中,如果它刚好重用该参数的话。
$changed参数还编码了有关传递到函数中的参数的稳定性的信息。这使得接受更广泛类型(例如List<T>)的函数也能够做到跳过参数比较,如果基于输入参数的推断结果为稳定的话(例如listOf(1, 2))。
默认参数
在编译时,添加到每个 Composable 函数的另一个额外元数据是 $default 参数。
Kotlin提供的默认参数支持对于Composable函数的参数并不可用,因为Composable函数需要在函数的范围内(生成的组)执行其参数的默认表达式。为此,Compose提供了默认参数解析机制的替代实现。
Compose 使用 $default 位掩码参数来表示默认参数,将每个参数索引映射到掩码上的一位。类似于对 $changed 参数所做的操作。每 N 个具有默认值的输入参数对应一个 $default 参数。此位掩码提供有关调用站点是否提供了参数值的信息,以确定是否必须使用默认表达式。
以下示例非常清楚地展示了一个 Composable 函数在
以上是关于Jetpack Compose 深入探索系列二:Compose 编译器的主要内容,如果未能解决你的问题,请参考以下文章