机器学习入门(4~9)
Posted Jozky86
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习入门(4~9)相关的知识,希望对你有一定的参考价值。
文章目录
数学基础(004,005)
线性代数:略
高数:
梯度(Gradient):

概率统计基础知识
常用统计变量

常用概率分布

重要概率公式
p(B|A):A发生的条件下B发生的概率

机器学习概述
机器学习的过程:
海量数据–>获得模型(提炼规律)–>预测未来
主要分类:
无监督学习
只有输入的数据,没有对应的结果
无监督学习算法不是相应反馈,而是要识别数据中的共性特征
分组和聚类
应用:谷歌新闻,将新闻分组,组成有关联的新闻,然后按主题显示给用户
有监督学习
当输出被限制为有限的一组值(离散数值)时使用分类算法;
当输出可以具有范围内的任何数值(连续数值)时使用回归算法
应用:预测房价或房价出售情况
监督学习三要素
模型+策略+算法
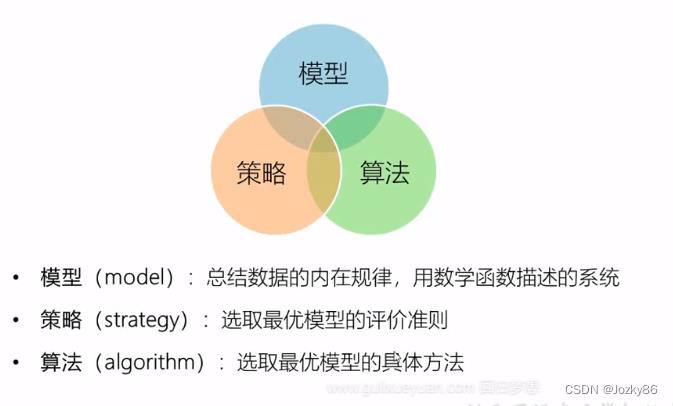
监督学习实验步骤

模型评估策略
训练集和测试集
数据分为:训练集和测试集
损失函数
衡量模型预测误差的大小,记作L(Y,f(X))
损失函数是系数的函数

常见损失函数:

经验风险
模型f(x)关于训练数据集的平均损失称为经验风险(empirial risk),记作Remp

训练误差和测试误差
测试误差更重要,真正反映了模型对未知数据的预测能力,这种能力一般被称为泛化能力

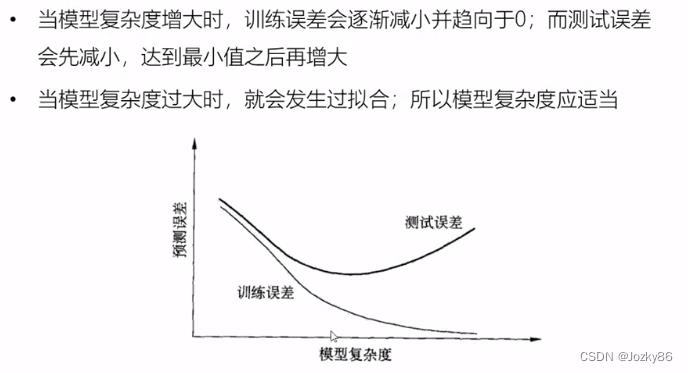
过拟合和欠拟合
欠拟合:模型没有很好捕捉到数据特征,特征集过小,导致模型不能很好地地拟合数据
过拟合:把噪声数据的特征也学习到了,特征集过大,模型泛化能力太差
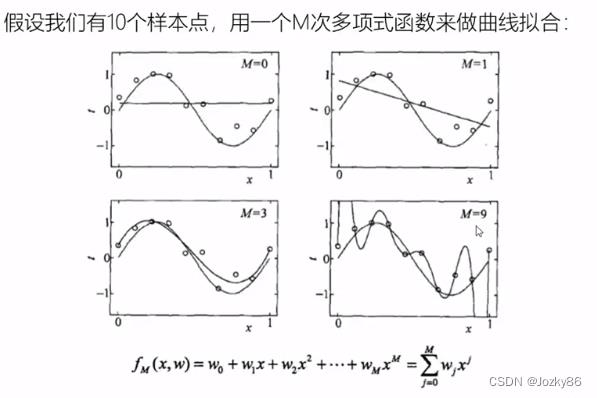
模型的选择
正则化
在经验风险上加上表示模型复杂度的正则化项,或者叫惩罚项

奥卡姆剃刀
原则:如无必要,勿增实体
如果简单的模型已经够用,不应该一味追求更小的训练误差,而把模型变得越来越复杂
交叉验证
样本数据充足:随机将数据集切成三部分:训练集,验证集和测试集
训练集用于训练模型,验证集用于模型选择,测试集用于学习方法评估
数据不充足,可以重复地利用数据–交叉验证:

分类和回归
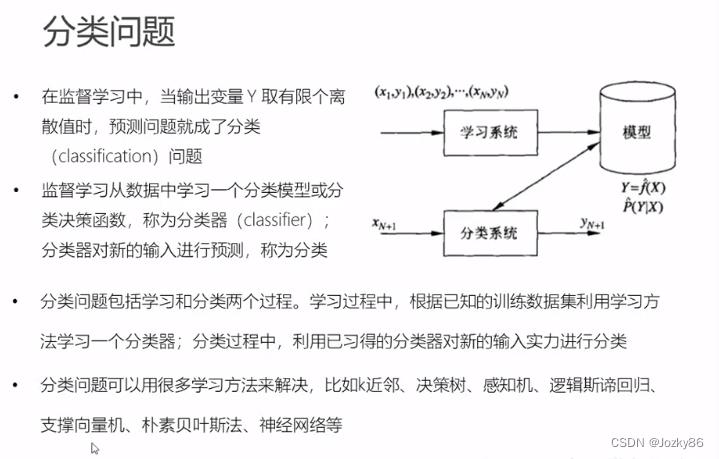
分类问题预测数据属于哪一类别。—离散
回归问题根据数据预测一个数值。–连续
分类问题
精确率和召回率


回归问题
回归问题的学习等价于函数拟合:选择一条函数曲线,使其更好地拟合已知数据,并能够很好地预测未知数据
分类:

模型求解算法(学习算法)
1.梯度下降算法

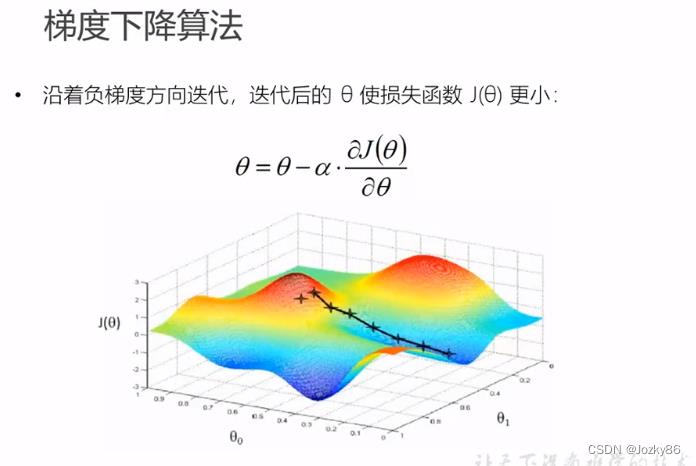
梯度下降不一定是最优解,有可能是局部极小值
如果损失函数是凸函数,梯度下降法得到的解一定是全局最优解
2.牛顿法和拟牛顿法

以上是关于机器学习入门(4~9)的主要内容,如果未能解决你的问题,请参考以下文章