大数据DataX:HBase导入到MySQL
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据DataX:HBase导入到MySQL相关的知识,希望对你有一定的参考价值。

文章目录
三、使用multiVersionFixedColumn模式案例
HBase导入到MySQL
将HBase中的数据导入到mysql中,这里使用到“HBaseReader”和“MySQLWriter”,前面已经介绍过“MySQLWriter”,下面介绍“HBaseReader”。
一、HbaseReader插件
HbaseReader 插件实现了从 Hbase中读取数据。在底层实现上,HbaseReader 通过 HBase 的 Java 客户端连接远程 HBase 服务,并通过 Scan 方式读取你指定 rowkey 范围内的数据,并将读取的数据使用 DataX 自定义的数据类型拼装为抽象的数据集,并传递给下游 Writer 处理。
目前HbaseReader支持的Hbase版本有:Hbase0.94.x和Hbase1.1.x。
若您的hbase版本为Hbase0.94.x,reader端的插件请选择:hbase094xreader,即:
"reader":
"name": "hbase094xreader"
若您的hbase版本为Hbase1.1.x,reader端的插件请选择:hbase11xreader,即:
"reader":
"name": "hbase11xreader"
简而言之,HbaseReader 通过 HBase 的 Java 客户端,通过 HTable, Scan, ResultScanner 等 API,读取你指定 rowkey 范围内的数据,并将读取的数据使用 DataX 自定义的数据类型拼装为抽象的数据集,并传递给下游 Writer 处理。hbase11xreader与hbase094xreader的主要不同在于API的调用不同,Hbase1.1.x废弃了很多Hbase0.94.x的api。
目前HbaseReader支持两模式读取:normal 模式、multiVersionFixedColumn模式:
normal 模式:把HBase中的表,当成普通二维表(横表)进行读取,读取最新版本数据。

multiVersionFixedColumn模式:把HBase中的表,当成竖表进行读取。读出的每条记录一定是四列形式,依次为:rowKey,family:qualifier,timestamp,value。读取时需要明确指定要读取的列,把每一个 cell 中的值,作为一条记录(record),若有多个版本就有多条记录(record)。

二、使用normal模式的案例
案例:将Hbase中表“hbase_person”写入到MySQL表person3(使用normal模式),步骤如下:
1、在mysql中创建“person3”表
CREATE TABLE `person3` (
`id` varchar(255) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2、编写DataX job配置文件
"job":
"setting":
"speed":
"channel": 1
,
"errorLimit":
"record": 0,
"percentage": 0.02
,
"content": [
"reader":
"name": "hbase11xreader",
"parameter":
"hbaseConfig":
"hbase.zookeeper.quorum": "node1:2181,node2:2181,node3:2181"
,
"table": "hbase_person",
"encoding": "utf-8",
"mode": "normal",
"column": [
"name": "cf1: id",
"type": "int"
,
"name": "cf1: name",
"type": "string"
,
"name": "cf1: age",
"type": "int"
],
"range":
"startRowkey": "1_",
"endRowkey": "4_",
"isBinaryRowkey": true
,
"writer":
"name": "mysqlwriter",
"parameter":
"writeMode": "insert",
"username": "root",
"password": "******",
"column": [
"id",
"name",
"age"
],
"connection": [
"jdbcUrl": "jdbc:mysql://node3:3306/mysqldb?useUnicode=true&characterEncoding=utf-8",
"table": [
"person3"
]
]
]
将以上编写好的配置上传到“/software/datax/job”路径下。
3、执行DataX任务,将HDFS数据导入到mysql
cd /software/datax/bin/
python datax.py /software/datax/job/hbasetomysql.json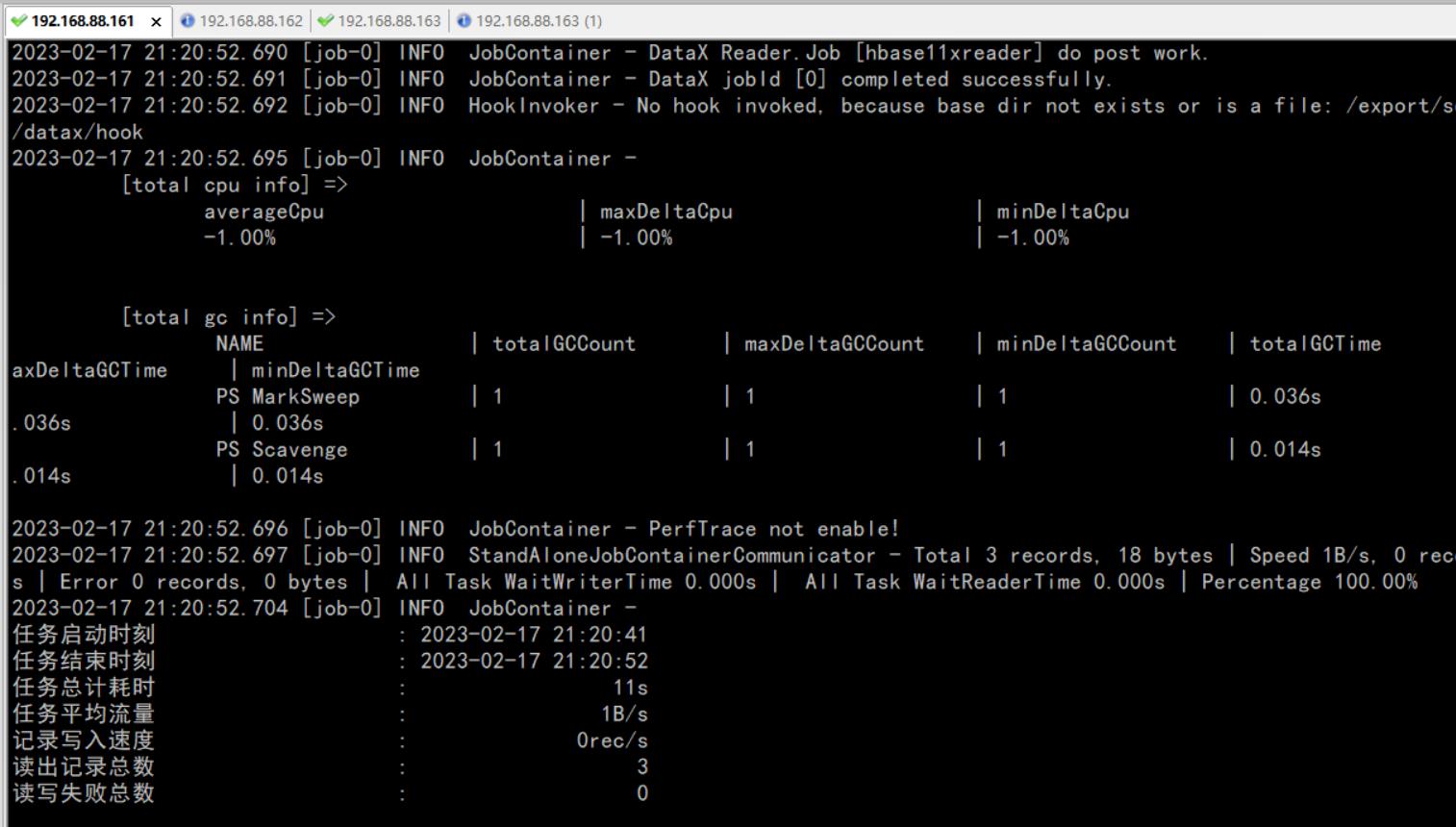
4、查看结果
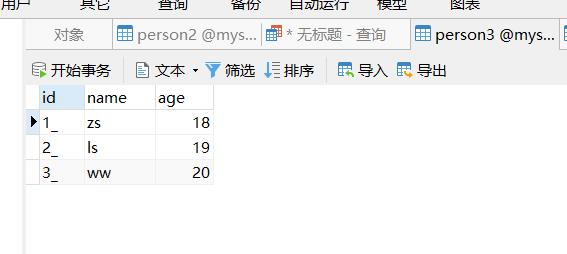
三、使用multiVersionFixedColumn模式案例
案例:将Hbase中表“hbase_person”写入到MySQL表hbase_result(使用multiVersionFixedColumn模式),步骤如下:
1、在mysql中创建表hbase_result
create table hbase_result(rk varchar(255),cf_col varchar(255),tm bigint,value varchar(255));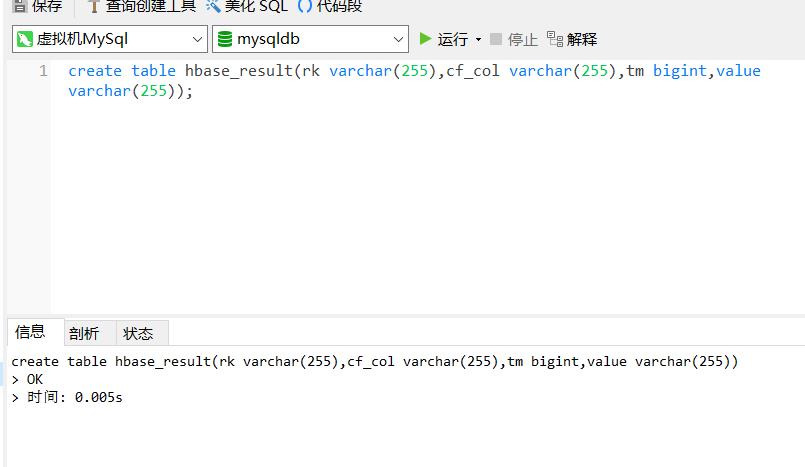
2、编写DataX job配置文件
"job":
"setting":
"speed":
"channel": 1
,
"errorLimit":
"record": 0,
"percentage": 0.02
,
"content": [
"reader":
"name": "hbase11xreader",
"parameter":
"hbaseConfig":
"hbase.zookeeper.quorum": "node1:2181,node2:2181,node3:2181"
,
"table": "hbase_person",
"encoding": "utf-8",
"mode": "multiVersionFixedColumn",
"maxVersion": "-1",
"column": [
"name": "rowkey",
"type": "string"
,
"name": "cf1: id",
"type": "int"
,
"name": "cf1: name",
"type": "string"
,
"name": "cf1: age",
"type": "int"
],
"range":
"startRowkey": "",
"endRowkey": ""
,
"writer":
"name": "mysqlwriter",
"parameter":
"writeMode": "insert",
"username": "root",
"password": "******",
"column": [
"rk",
"cf_col",
"tm",
"value"
],
"connection": [
"jdbcUrl": "jdbc:mysql://node3:3306/mysqldb?useUnicode=true&characterEncoding=utf-8",
"table": [
"hbase_result"
]
]
]
将以上编写好的配置上传到“/software/datax/job”路径下。
3、执行DataX任务,将HBase数据导入到mysql
cd /software/datax/bin/
python datax.py /software/datax/job/hbasetomysql2.json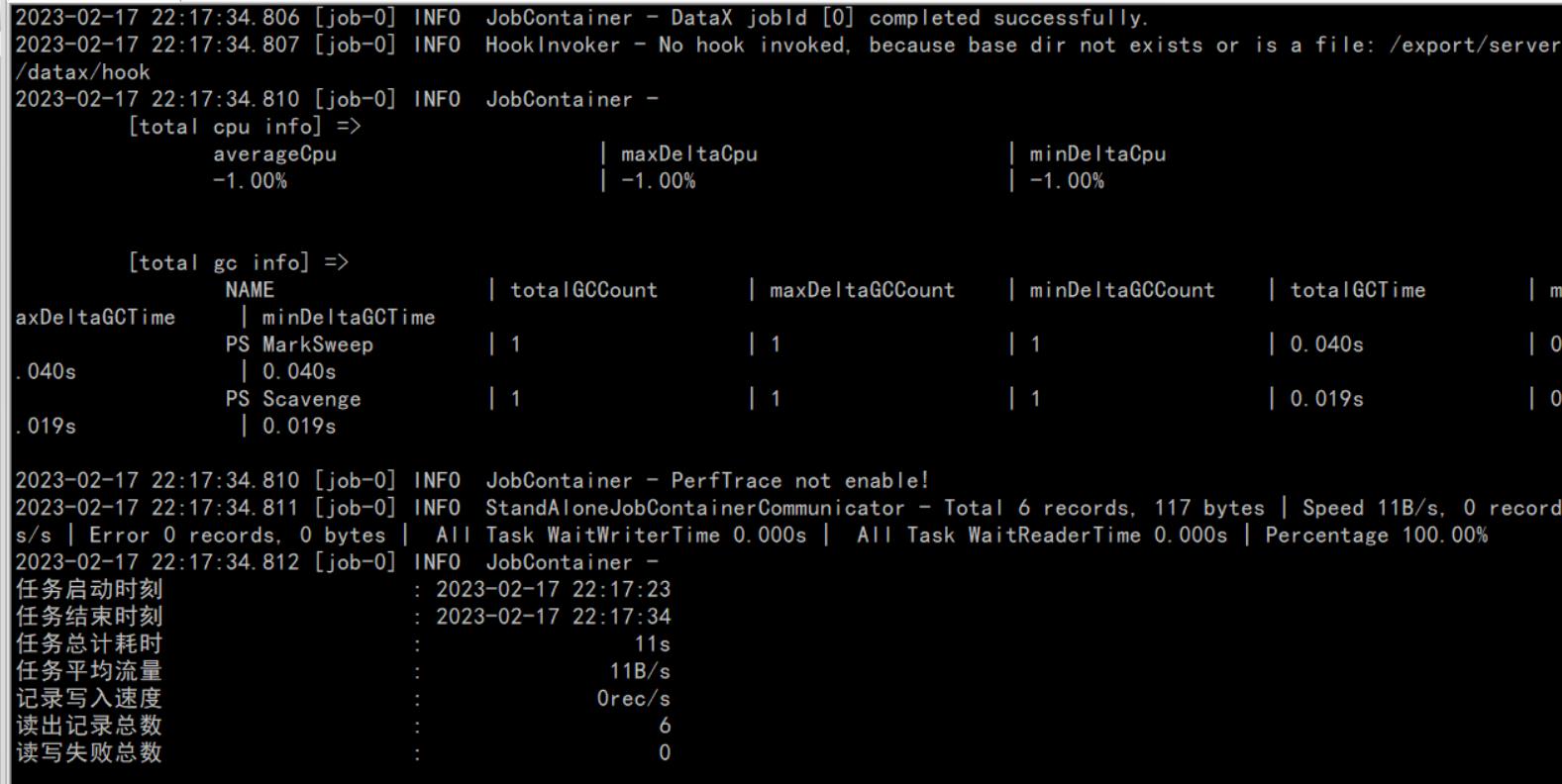
4、查看结果
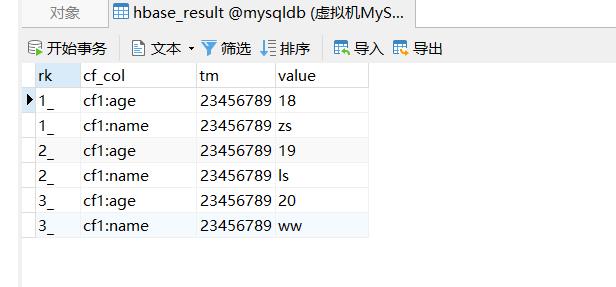
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于大数据DataX:HBase导入到MySQL的主要内容,如果未能解决你的问题,请参考以下文章