推荐一个比 Redis 性能更强的数据库,性能直接飙升一倍!
Posted Java知音_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐一个比 Redis 性能更强的数据库,性能直接飙升一倍!相关的知识,希望对你有一定的参考价值。
1 什么是KeyDB?
KeyDB是Redis的高性能分支,专注于多线程,内存效率和高吞吐量。除了多线程之外,KeyDB还具有仅在Redis Enterprise中可用的功能,例如Active Replication,FLASH存储支持以及一些根本不可用的功能,例如直接备份到AWS S3。
KeyDB与Redis协议,模块和脚本保持完全兼容性。这包括脚本和事务的原子性保证。由于KeyDB与Redis开发保持同步,因此KeyDB是Redis功能的超集,从而使KeyDB取代了现有Redis部署。
在相同的硬件上,KeyDB每秒可以执行的查询数量是Redis的两倍,而延迟却降低了60%。Active-Replication简化了热备用故障转移,使您可以轻松地在副本上分配写操作并使用基于TCP的简单负载平衡/故障转移。KeyDB的高性能可让您在更少的硬件上做更多的事情,从而降低了运营成本和复杂性。
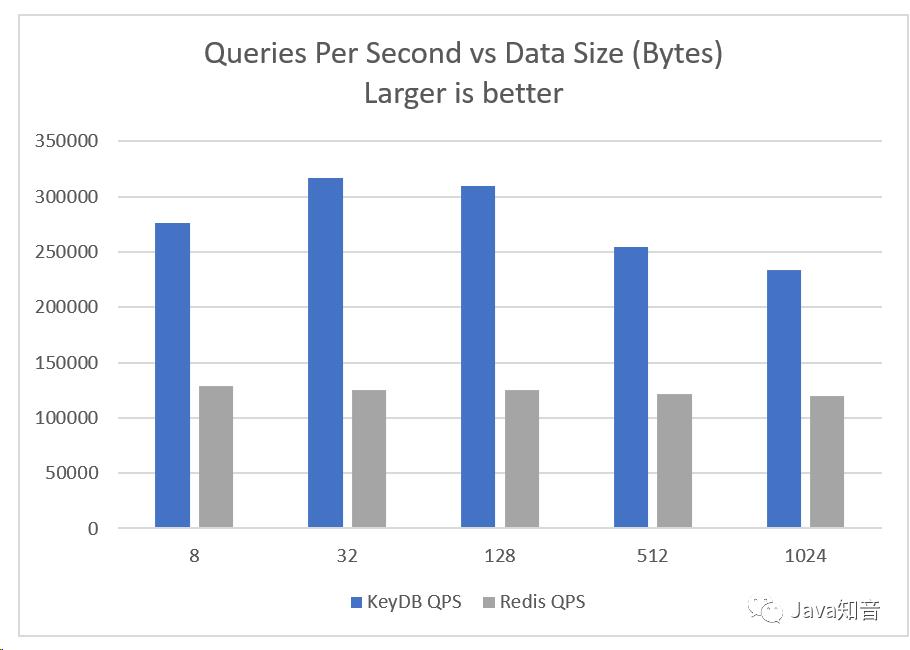
在此处查看完整的基准测试结果和设置信息:
https://docs.keydb.dev/blog/2019/10/07/blog-post/
2 走进KeyDB-- 转载
KeyDB项目是从redis fork出来的分支。众所周知redis是一个单线程的kv内存存储系统,而KeyDB在100%兼容redis API的情况下将redis改造成多线程。
项目git地址:
https://github.com/JohnSully/KeyDB
网上公开的技术细节比较少,本文基本是通过阅读源码总结出来的,如有错漏之处欢迎指正。
多线程架构
线程模型
KeyDB将redis原来的主线程拆分成了主线程和worker线程。每个worker线程都是io线程,负责监听端口,accept请求,读取数据和解析协议。如图所示:

KeyDB使用了SO_REUSEPORT特性,多个线程可以绑定监听同个端口。
每个worker线程做了cpu绑核,读取数据也使用了SO_INCOMING_CPU特性,指定cpu接收数据。
解析协议之后每个线程都会去操作内存中的数据,由一把全局锁来控制多线程访问内存数据。
主线程其实也是一个worker线程,包括了worker线程的工作内容,同时也包括只有主线程才可以完成的工作内容。在worker线程数组中下标为0的就是主线程。
主线程的主要工作在实现serverCron,包括:
处理统计
客户端链接管理
db数据的resize和reshard
处理aof
replication主备同步
cluster模式下的任务
链接管理
在redis中所有链接管理都是在一个线程中完成的。在KeyDB的设计中,每个worker线程负责一组链接,所有的链接插入到本线程的链接列表中维护。链接的产生、工作、销毁必须在同个线程中。每个链接新增一个字段
int iel; /* the event loop index we're registered with */用来表示链接属于哪个线程接管。
KeyDB维护了三个关键的数据结构做链接管理:
clients_pending_write:线程专属的链表,维护同步给客户链接发送数据的队列clients_pending_asyncwrite:线程专属的链表,维护异步给客户链接发送数据的队列clients_to_close:全局链表,维护需要异步关闭的客户链接
分成同步和异步两个队列,是因为redis有些联动api,比如pub/sub,pub之后需要给sub的客户端发送消息,pub执行的线程和sub的客户端所在线程不是同一个线程,为了处理这种情况,KeyDB将需要给非本线程的客户端发送数据维护在异步队列中。
同步发送的逻辑比较简单,都是在本线程中完成,以下图来说明如何同步给客户端发送数据:

如上文所提到的,一个链接的创建、接收数据、发送数据、释放链接都必须在同个线程执行。异步发送涉及到两个线程之间的交互。KeyDB通过管道在两个线程中传递消息:
int fdCmdWrite; //写管道
int fdCmdRead; //读管道本地线程需要异步发送数据时,先检查client是否属于本地线程,非本地线程获取到client专属的线程ID,之后给专属的线程管到发送AE_ASYNC_OP::CreateFileEvent的操作,要求添加写socket事件。专属线程在处理管道消息时将对应的请求添加到写事件中,如图所示:

redis有些关闭客户端的请求并非完全是在链接所在的线程执行关闭,所以在这里维护了一个全局的异步关闭链表。

锁机制
KeyDB实现了一套类似spinlock的锁机制,称之为fastlock。
fastlock的主要数据结构有:
struct ticket
uint16_t m_active; //解锁+1
uint16_t m_avail; //加锁+1
;
struct fastlock
volatile struct ticket m_ticket;
volatile int m_pidOwner; //当前解锁的线程id
volatile int m_depth; //当前线程重复加锁的次数
;使用原子操作__atomic_load_2,__atomic_fetch_add,__atomic_compare_exchange来通过比较m_active=m_avail判断是否可以获取锁。 fastlock提供了两种获取锁的方式:
try_lock:一次获取失败,直接返回
lock:忙等,每
1024 * 1024次忙等后使用sched_yield主动交出cpu,挪到cpu的任务末尾等待执行。
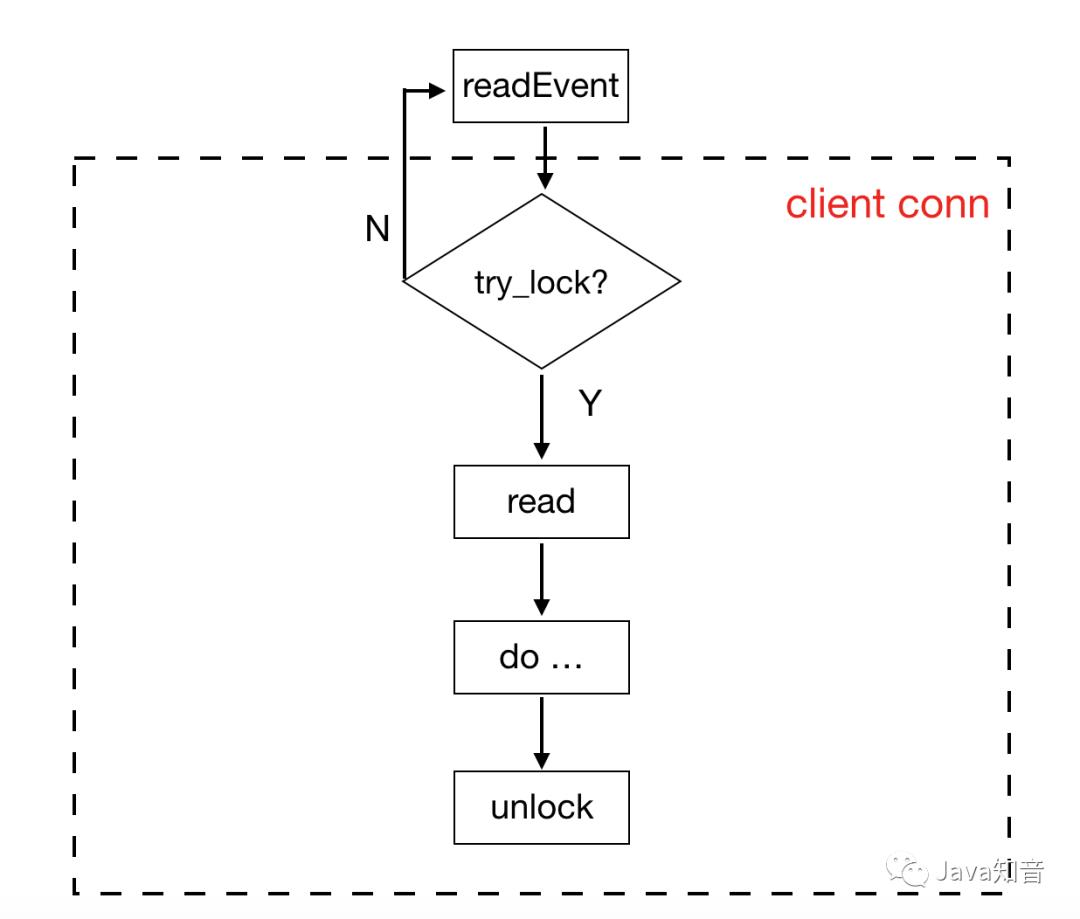
在KeyDB中将try_lock和事件结合起来,来避免忙等的情况发生。每个客户端有一个专属的lock,在读取客户端数据之前会先尝试加锁,如果失败,则退出,因为数据还未读取,所以在下个epoll_wait处理事件循环中可以再次处理。
Active-Replica
KeyDB实现了多活的机制,每个replica可设置成可写非只读,replica之间互相同步数据。主要特性有:
每个replica有个uuid标志,用来去除环形复制
新增加rreplay API,将增量命令打包成rreplay命令,带上本地的uuid
key,value加上时间戳版本号,作为冲突校验,如果本地有相同的key且时间戳版本号大于同步过来的数据,新写入失败。采用当前时间戳向左移20位,再加上后44位自增的方式来获取key的时间戳版本号。
3 文档
https://docs.keydb.dev/docs/commands
感谢阅读,希望对你有所帮助 :)
来源:https://developer.aliyun.com/article/705239
推荐

PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!
以上是关于推荐一个比 Redis 性能更强的数据库,性能直接飙升一倍!的主要内容,如果未能解决你的问题,请参考以下文章