3.mysql之索引
Posted historyofsmile
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3.mysql之索引相关的知识,希望对你有一定的参考价值。
3.mysql之索引
当下说的mysql,单指innoDB引擎。
索引就是为了快速查找而设计的一种搜索结构,innoDB引擎的索引结构为:B+树。那么B+树是什么、为什么选择它?innoDB索引树上都存了什么?索引该怎么使用?索引使用上有哪些坑?
什么是B+树
-
B树
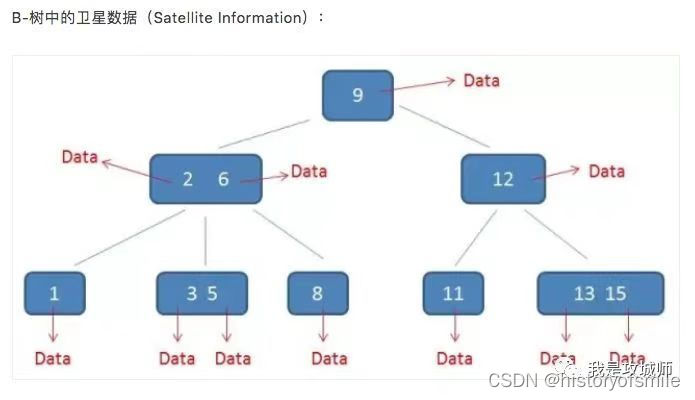
-
B+树
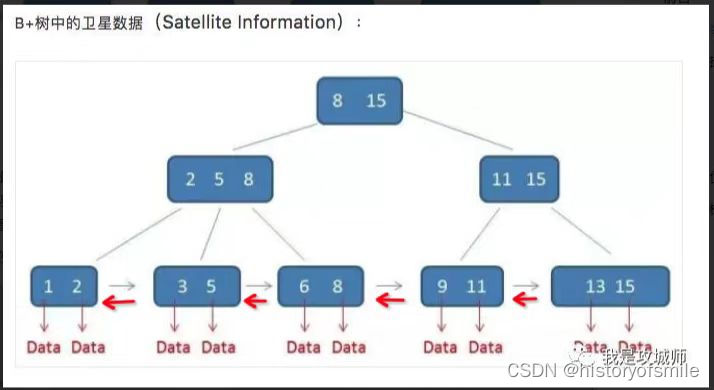
B+树是对B树的一次改造,B树的每个节点都存有数据,而B+树的非叶子节点只保存索引字段的值,而不保存其他数据,完整的数据最终都下沉的叶子节点去,再把存有全部数据的叶子节点前后串联起来做成双向链表,这就是一个B+树。
为什么使用B+树
一个功能实现之前,肯定要调研市场上已经有的技术,能用好用,就直接拿来用,不好用、不满足需求时,就需要自研。这里说为什么使用B+树,不如说B+树是怎么诞生的。
快速查找的数据结构海了去了,比如二叉平衡树,B树……
二叉树的层级负担
二叉平衡树完全按可以满足快速检索的能力,但是层级太深,一次检索需要找好多个节点,1024个数据就需要10层来存储,上下层级不在一个数据页的话,就需要10次磁盘IO,前面写磁盘部分已经交代了,mysql设计之初就在考虑不频繁、随机操作磁盘的问题了,这也是二叉平衡树被放弃的原因。
B树的瓶颈
-
层级负担
B树解决了层级过深的问题,但并没有完全解决,因为B树一个节点存多少数据合适呢?mysql是根据自身数据页大小(16k)来算的,固定的也大小能存多少,取决于节点数据的大小。B树每个节点都存全量数据,这样一个节点页存不了多少,那就只能增加节点,增加节点的结果是 加深的树的层级。 -
区间检索的傻瓜
另外,B树提供的漂亮的单点检索能力,但遇到区间检索问题,就变成了一个傻瓜。例如:参考上面的B树图查找 [8,11]。
B+树的诞生
既然B树已经很接近答案了,那是不是可以容忍它的缺点,蒙着眼接收它呢——不,改造它!给灰姑娘穿上漂亮的水晶鞋,送她住进城堡,还要接受最好的宫廷礼仪……
* 改造
1. 为B树的非叶子节点瘦身,让它们只保存排序字段(索引字段);
2. 数据全部下沉到叶子节点,并把这个有序的叶子节点改造成双向链表。
innoDB的索引
innoDB的索引结构就是B+树,非叶子节点存储索引字段,叶子节点存储数据。
表结构是一棵B+树,每一个索引也是一棵B+树,同样以页为单位保存在磁盘中,也同样以页为单位缓存在buffer pool中,所以——要把索引和缓存的概念分开,各是各。当然,内存是有限的,必不可能所有数据页都缓存在内存中,关于 mysql 缓存的机制,后面再说。
聚簇索引
即主键索引树,非叶子节点存储主键,叶子节点存储全数据,这就是innoDB引擎的表数据,人们常说的回表查询,就是拿主键来查这棵树。
非聚簇索引
普通索引树,非叶子节点为索引字段,叶子节点保存主键。sql使用到非聚簇索引,就是用索引字段查找数据的主键,再拿着主键回表查看完整数据。
索引维护
- 索引是一棵B+树,写入和删除字段有可能会造成也分裂和页合并,这是一个有损性能的操作,一个连续有序的主键,可以减少这种情况;
- 每个非聚簇索引树的叶子节点都存着主键,为了节约空间,建议逐渐字段类型能小一点;
综上所述,建议使用自增的数字类型做主键。当然,建议只是建议。
索引的选择
一张表可以有很多索引,sql查询该查询哪个索引呢?什么时间节点,由谁来选择——Server优化器!
选择索引的原则
选择索引,优化器需要先做一些资源消耗上的评估,当然,用于评估的数据并不是准确数字,而是为了效率,提前缓存好的抽样数据,会导致失败。
- 扫描的行数
- 是否使用临时表
- 是否排序
- ……
选错索引解决方案
优化器自然有一套自己的选择逻辑,但是不一定每次都能选择合适的索引。选错索引的一些解决办法:
- force index,在sql语句中强制使用指定的索引
- 调整sql语句,如:where 语句的顺序、order by字段 等……
- 创建更合适的索引、或删除容易干扰的索引
索引的使用
普通索引和唯一索引的不同
查询
- 普通索引:找到一个值以后,会沿着叶子节点的双向队列向满足条件的方向继续查看,直到找到第一个不满足条件的数据,然后返回满足的结果集;
- 唯一键索引:不会有重复数据,找到目标值后,直接返回,不会多查一个值。
更新
写磁盘那一节已经交代了更新一条数据的问题:
● 如果数据页在内存(buffer)中,就直接修改数据页;
● 如果数据页不在内存(buffer)中,就直接把修改结果保存在change buffer中,而不是直接落盘。
数据表会有一些特别的约束:1、主键;2、默认值;3、唯一;4、外键;5、非空。其中:
- 非空和默认值约束:保存在表结构中,在Server层就已经校验过了,不会传到引擎层来;
- 外键约束:要涉及到另外一张或多张表的问题,修改时,肯定要扫描关联的表,性能极低,所以现在使用外键约束的表结构越来越少了;
- 主键约束:一般我们都使用自增主键,并且也没有修改主键的操作;
- 唯一键约束:唯一键字段发生更新时,需要扫描整张表来做唯一键校验,这时候会把相关的数据页都加载的内存中来,更新操作也就直接修改内存页了,不会用到 change buffer。
发现了吧,修改唯一键字段,会先扫描整张表,根本不会用到change buffer,这样使的频繁更新的表变得性能极低;建议尽量用业务保证唯一数据唯一性,而不是唯一键,尤其是吞吐量高的表。
当然,change buffer 也有弊端:更新的时候,数据页不在内存中,就记录了change buffer;更新后,立即访问该数据,这时候,需要把数据页加载到内存中,然后merge change buffer,再返回数据;要change buffer 的意义就是为了减少IO操作次数,尽量一次IO更新更多的数据,上面的场景会造成频繁IO不说,又多了merge 操作,得不偿失。一般来说,这样频繁更新查看的数据页,应该在内存中,不至于使用到change buffer。
联合索引的奇淫巧技
索引覆盖
前面说查普通索引只能拿到索引字段和id字段,想要获取其他字段的值,只能拿id去回表,这就平白多了IO操作,有什么办法可以不回表就能拿到想要的字段么——索引覆盖。
顾名思义,就是把热点字段放到索引里面,组成联合索引。 比如:
表user 有字段 id,a,b,c,d
select id,a,b from user where a > 10;
- a字段是索引字段,必须回表去找b字段;
- a,b字段为联合索引,a,b在索引上,id页在索引树上,不需要回表
最左前缀原则
索引项是按照索引定义里面出现的字段共同排序的,第一字段优先,第二字段次之……
举例说明:
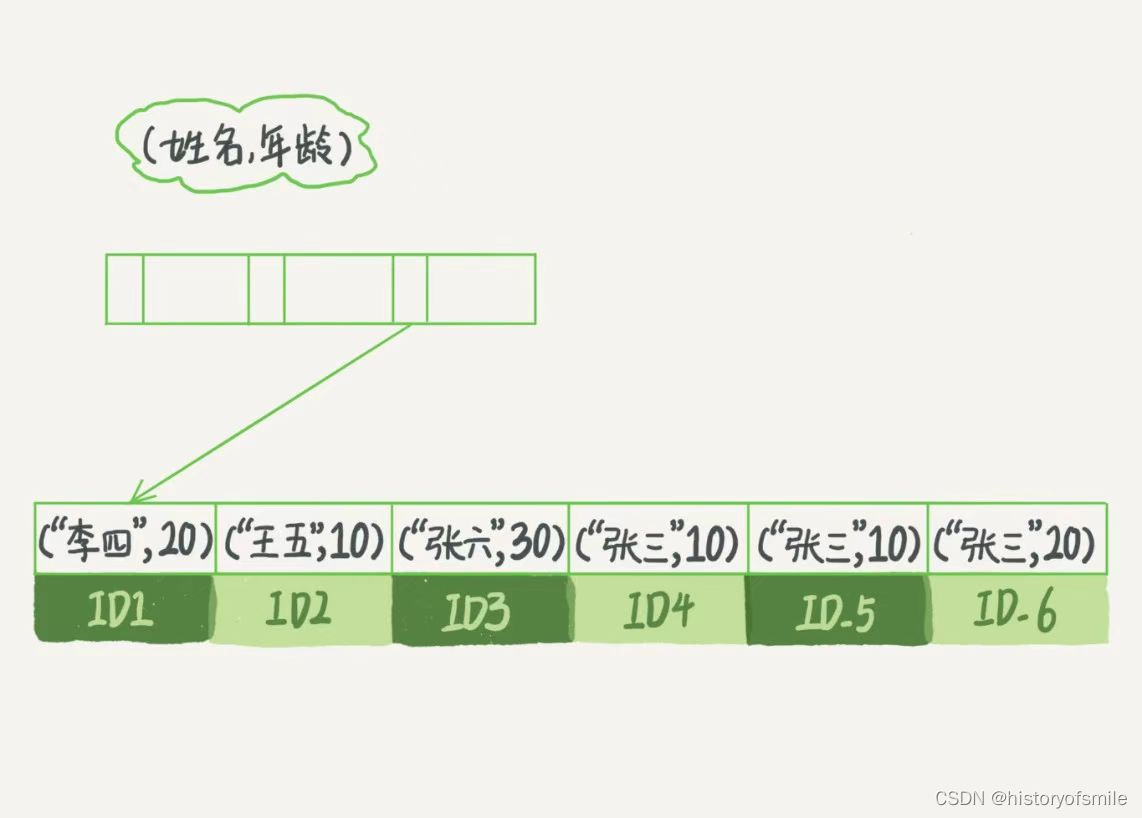
user 表 有字段 id,name,age,其中name,age创建了联合索引
// 可以用到索引的查询
select name,age from user where name = ‘张三’;
select name,age from user where name like ‘张%’;
select name,age from user where name = ‘张三’ and age > 10;
// 不能使用该索引的查询
select name,age from user where age > 20; // 没有使用完整的第一字段
select name,age from user where name like ‘张%’ and age > 20; // 没有使用完整的第一字段
● 根据最左前缀原则,创建联合索引的时候,应该把使用频率越高的字段,越往前排,争取让更多的查询语句能用到该索引,这样可以减少创建不必要的索引,降低索引维护的成本。
索引下推(5.6版本后的一个优化)
使用一个例子:
select name,age from user where name like ‘张%’ and age > 20 and gender = '女';
虽然这个sql不能完整的使用索引,但是可以使用索引的一部分:至少可以把姓张的过滤出来,然后发现条件里面的age字段也包含在索引中,那么用age条件也过滤一下,尽量返回更精确的id(主键)集合,再回表去找 gender = '女’的数据,可以减少回表查询次数。
清理表空间
表结构也是一个B+树, 如果主键非按顺序写入,就会在也分裂时,造成空数据。
● delete 删除数据,也不能释放表空间,只是将表空间对应位置的数据清掉了,空间仍然要留着,给别的数据用;
● 想要真的释放表空间,可以通过创建一个表,按顺序把当前数据迁移走,再drop掉当前表;
● alter table t engine=innodb;这条语句可以完成上面的 create + drop 操作。
以上是关于3.mysql之索引的主要内容,如果未能解决你的问题,请参考以下文章