Pytorch项目实战基于PaddlenHub的口罩检测与语音提示
Posted 胖墩会武术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch项目实战基于PaddlenHub的口罩检测与语音提示相关的知识,希望对你有一定的参考价值。
文章目录
一、项目思路
(1)调用PaddlenHub模块的口罩检测预训练模型,通过PaddlenHub.face_detectionAPI,完成图片检测或实时检测任务。
(2)若未佩戴口罩,则使用PlaySound模块播放录制的MP3文件(一秒钟提示音),完成警告提示。
二、环境配置
1.1、PaddlenHub模块(飞桨预训练模型应用工具)
- PaddleHub 是基于 PaddlePaddle 开发的预训练模型管理工具。PaddlenHub官网
- 配合使用 Fine-tune API,快速完成迁移学习到应用部署的全流程工作。让预训练模型能更好地服务于用户特定场景的应用,也让开发者体验到大规模预训练模型的价值。
- PaddleHub 目前提供的预训练模型覆盖了图像分类、目标检测、词法分析、Transformer、情感分析五大类别。
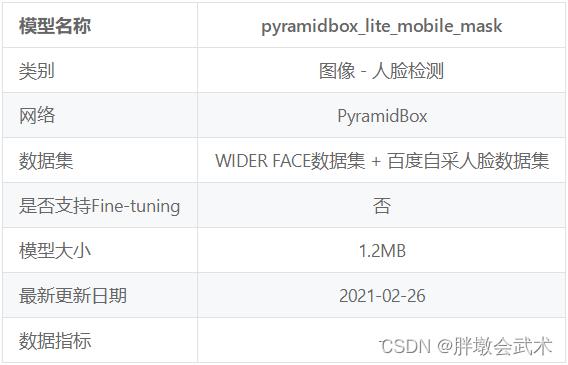
(1)预训练模型:pyramidbox_lite_mobile_mask
PyramidBox-Lite是基于2018年百度发表于计算机视觉顶级会议ECCV 的论文所提出的PyramidBox网络而研发的轻量级模型。
- 模型基于主干网络FaceBoxes,对于光照、口罩遮挡、表情变化、尺度变化等常见问题具有很强的鲁棒性。
- 该PaddleHub Module是针对于移动端优化过的模型,适合部署于移动端或者边缘检测等算力受限的设备上。
- 可用于检测人脸是否佩戴口罩。
(2)face_detection人脸检测模型(默认为 pyramidbox_lite_mobile)
作用:识别输入图片中的所有的人脸,并判断有无戴口罩。
def face_detection(images=None, paths=None, batch_size=1, use_gpu=False,
visualization=False, output_dir='detection_result',
use_multi_scale=False, shrink=0.5, confs_threshold=0.6)
"""
输入参数:
(1)images (list[numpy.ndarray]): 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
(2)paths (list[str]): 图片的路径;
(3)batch_size (int): batch 的大小;
(4)use_gpu (bool): 是否使用 GPU;
(5)visualization (bool): 是否将识别结果保存为图片文件;
(6)output_dir (str): 图片的保存路径,默认设为 detection_result;
(7)use_multi_scale (bool) : 用于设置是否开启多尺度的人脸检测,开启多尺度人脸检测能够更好的检测到输入图像中不同尺寸的人脸,但是会增加模型计算量,降低预测速度;
(8)shrink (float): 用于设置图片的缩放比例,该值越大,则对于输入图片中的小尺寸人脸有更好的检测效果(模型计算成本越高),反之则对于大尺寸人脸有更好的检测效果;
(9)confs_threshold (float): 置信度的阈值。
输出参数:res (list[dict]): 识别结果的列表,列表中每一个元素为 dict,各字段为:
(1)path (str): 原输入图片的路径
(2)data (list): 检测结果,list的每一个元素为 dict,各字段为:
11、label (str): 识别标签,为 'NO MASK' 或者 'MASK';
22、confidence (float): 识别的置信度
33、left (int): 边界框的左上角x坐标
44、top (int): 边界框的左上角y坐标
55、right (int): 边界框的右下角x坐标
66、bottom (int): 边界框的右下角y坐标
"""
(3)PaddleHub与PytorchHub的区别
PytorchHub 目前支持18个模型,PaddleHub支持29个。60分钟教你上手PaddleHub
- PytorchHub涉及的方向更多,但是每个方向的模型并不多,对CV的支持更多;
- PaddleHub涉及的方向只有两个,CV和NLP,但是对NLP的支持尤其多,高达22个,不仅包括目前最潮的BERT,还有百度自己研发的知识增强语义表示模型Ernie,在多个中文NLP任务中表现超过BERT,除此之外还有对话系统的一系列模型,做智能客服、智能音箱的同学可以使用一下。
对于迁移学习来说,Fine-tune(微调)是必不可少的,虽然我们有预训练的模型,但是新任务的场景和数据都不相同,直接使用预训练模型其实很难得到很好的效果。

(4)安装(paddlehub + paddlepaddle)
- 第一步:paddlehub安装
pip install paddlehub
安装后若提示:
ModuleNotFoundError: No module named ‘paddle‘,则需要安装paddlepaddle。

- 第二步:paddlepaddle安装
cpu: pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
gpu: pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple
1.2、PlaySound模块(音频播放)
PlaySound是Windows用于播放音乐的API函数。添加模块后,检测速度会有所延迟。
函数:
BOOL PlaySound(LPCSTR pszSound, HMODULE hmod, DWORD fdwSound)。
- 参数
pszSound是指定了要播放声音的字符串。(1)该参数可以是WAVE文件的名字(2)或是WAV资源的名字(3)或是内存中声音数据的指针(4)或是在系统注册表WIN.INI中定义的系统事件声音(5)如果该参数为NULL,则停止正在播放的声音。- 参数
hmod是应用程序的实例句柄,当播放WAV资源时要用到该参数,否则它必须为NULL。- 参数
fdwSound是播放标志的组合。(1)SND_APPLICATION:用应用程序指定的关联来播放声音。(2)SND_ALIAS:pszSound参数指定了注册表或WIN.INI中的系统事件的别名。(3)SND_ALIAS_ID:pszSound参数指定了预定义的声音标识符。(4)SND_ASYNC:用异步方式播放声音,PlaySound函数在开始播放后立即返回。(5)SND_FILENAME:pszSound参数指定了WAVE文件名。(6)SND_LOOP:重复播放声音,必须与SND_ASYNC标志一块使用。(7)SND_MEMORY:播放载入到内存中的声音,此时pszSound是指向声音数据的指针。(8)SND_NODEFAULT:不播放缺省声音,若无此标志,则PlaySound在没找到声音时会播放缺省声音。(9)SND_NOSTOP:PlaySound不打断原来的声音播出并立即返回FALSE。(10)SND_NOWAIT:如果驱动程序正忙则函数就不播放声音并立即返回。(11)SND_PURGE:停止所有与调用任务有关的声音。若参数pszSound为NULL,就停止所有的声音,否则,停止pszSound指定的声音。(12)SND_RESOURCE:pszSound参数是WAVE资源的标识符,这时要用到hmod参数。(13)SND_SYNC:同步播放声音,在播放完后PlaySound函数才返回。
(1)playsound安装:WIN +R + cmd + 运行 + pip install playsound。**
(2)playsound功能演示:一秒提示音下载地址
# 注意不能写成:import playsound, 将导致报错。
from playsound import playsound
playsound('path/play.mp3')
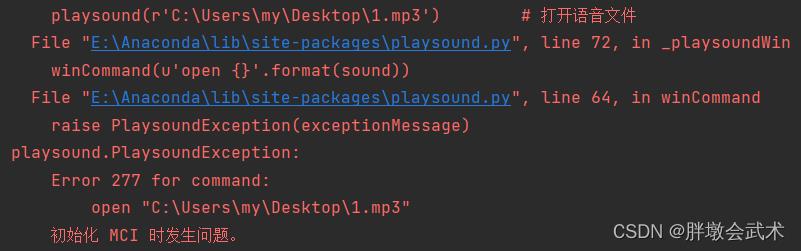
运行后若出现以下报错:
报错原因:直接更改语音包的后缀进行格式转换,将导致报错。
解决方法:音频格式转换地址
三、项目实战:基于PaddlenHub的口罩检测与语音提示(Opencv)

import paddlehub
from playsound import playsound
import cv2
################################################################################################
module = paddlehub.Module(name="pyramidbox_lite_mobile_mask") # 调用paddlehub模块中的口罩检测模型:pyramidbox_lite_mobile_mask。
cap = cv2.VideoCapture(0) # 调用本机摄像头
# 循环判断面部区域位置
while cap.isOpened():
frame = cap.read()[1] # 读取帧图像
input_dict = 'data': [frame] # 字典的形式存储
results = module.face_detection(data=input_dict) # face_detection:人脸检测模型
result = results[0] # 获取识别后的:标签、置信度、四元数组(位置)
# waitKey可以控制视频的播放速度,数值越小,播放速度越快
k = cv2.waitKey(1) & 0xFF # 0xFF == 27 表示退出键(Esc)
# 若检测结果存在(即当前图像中是否有人脸)
if result['data'] != []: # 判断字典中的某个键对应的值是否为空
label = result['data'][0]['label'] # label(str): 识别标签:'NO MASK' 或者 'MASK';
left = result['data'][0]['left'] # left(int): 边界框的左上角x坐标
right = result['data'][0]['right'] # top(int): 边界框的左上角y坐标
top = result['data'][0]['top'] # right(int): 边界框的右下角x坐标
bottom = result['data'][0]['bottom'] # bottom(int): 边界框的右下角y坐标
# 当判断为肯定时,绘制绿色矩形及文字
if label == 'MASK':
color = (0, 255, 0)
color2 = (0, 255, 0)
# 当判断为否定时,绘制红色矩形及文字
if label == 'NO MASK':
color = (0, 0, 255)
color2 = (0, 0, 255)
playsound(r'C:\\Users\\my\\Desktop\\output.mp3') # 打开语音文件
# 绘制矩形框 + 添加文本内容
cv2.rectangle(frame, (left, top), (right, bottom), color, 3)
cv2.putText(frame, label, (left, top - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.8, color2, 2)
cv2.imshow('martial art', frame)
# 监听键盘事件: 按空格键退出.
if k == ord(' '):
break
cap.release() # 释放摄像头
cv2.destroyAllWindows() # 释放内存
以上是关于Pytorch项目实战基于PaddlenHub的口罩检测与语音提示的主要内容,如果未能解决你的问题,请参考以下文章