MongoDB 4.0支持事务了,还有多少人想用MySQL呢?
Posted 哪 吒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB 4.0支持事务了,还有多少人想用MySQL呢?相关的知识,希望对你有一定的参考价值。

目录
大家好,我是哪吒,最近项目在使用MongoDB作为图片和文档的存储数据库,为啥不直接存mysql里,还要搭个MongoDB集群,麻不麻烦?
让我们一起,一探究竟,继续学习MongoDB的事务、连接池以及聚合框架,实现快速入门,丰富个人简历,提高面试level,给自己增加一点谈资,秒变面试小达人,BAT不是梦。
一、MongoDB 不支持事务?
一些第三方文章将 MongoDB 描述成 BASE 数据库。BASE 是指“基本可用、软状态、最终一致”。
但这不是真的,从来都不是!MongoDB 从来都不是“最终一致”的。对主文档的读写是强一致性的,对单个文档的更新始终是原子的。软状态是指需要持续不断的更新数据,否则数据就会过期,但 MongoDB 并非如此。
最后,如果太多的节点不可用,无法达成仲裁,MongoDB 将进入只读状态(降低可用性)。这是有意这么设计的,因为这样可以确保在出现问题时保持一致性。
MongoDB 是一个 ACID 数据库。它支持原子性、一致性、隔离性和持久性。
对单个文档的更新始终是原子的,从 4.0 版本开始,MongoDB 也支持跨多个文档和集合的事务。从 4.2 开始,甚至支持分片集群的跨分片事务。
虽然 MongoDB 支持事务,但在使用它时仍然要谨慎。事务是以性能为代价的,而且由于 MongoDB 支持丰富的分层文档,如果你的模式设计正确,就没有必要经常跨多个文档更新数据。

二、什么是事务?
事务是数据库中处理的逻辑单元,包括一个或多个数据库操作,既可以是读操作,也可以是写操作,MongoDB支持跨个多操作、集合、数据库、文档和分片的ACID事务。
事务的关键:它要么都成功,要么都失败。
三、ACID的定义
ACID是一个事务所需要具备的一组属性集合。
ACID是原子性atomicity、一致性consistency、隔离性isolation、持久性durability的缩写。
ACID事务可以确保数据和数据库状态的有效性,即使在出现断电或其它错误的情况下也是如此。
原子性确保了事务中的所有操作要么都被执行、要么都不被执行。
一致性确保可如果事务成功,那么数据库将从一个一致性状态转移到下一个一致性状态。
隔离性是允许多个事务同时在数据库中运行的属性。它保证了一个事务不会查看到任何其它事务的部分结果,这意味着多个事务并行运行于依次运行每个事务所获得的结果都相同。
持久性确保了在提交事务时,即使系统发生故障,所有数据也都会保持持久化。
当数据库满足所有这些属性并且只有成功的事务才会被处理时,它就被称为符合ACID的数据库。如果在事务完成之前发生故障,ACID确保不会更改任何数据。
MongoDB是一个分布式数据库,它支持跨副本集和跨分片的ACID事务。网络层增加了额外的复杂性。
四、如何使用事务
MongoDB提供了两种API来使用事务。
- 第一种与关系型数据库类似(如start_transaction和commit_transaction),称为核心API;
- 第二种称为回调API,一般推荐使用这种;
核心API不会为大多数错误提供重试逻辑,它要求开发人员为操作、事务提交函数以及所需的任何重试和错误逻辑手动编写代码。
与核心API不同,回调API提供了一个简单的函数,该函数封装了大量的功能,包括启动与指定逻辑会话关联的事务、执行作为回调函数提供的函数以及提交事务。回调API还提供了处理提交错误的重试逻辑。在MongoDB4.2中添加回调API是为了简化使用事务的应用程序开发,也便于添加处理事务错误的应用程序重试逻辑。
核心API和回调API的比较
| 核心API | 回调API |
|---|---|
| 需要显示调用才能启动和提交事务 | 启动事务、执行指定操作,然后提交(可在发生错误前终止) |
| 不包含TransientTransactionError和UnknowTransactionCommitResult的错误处理逻辑,而是提供了为这些错误进行自定义处理的灵活性 | 自动为TransientTransactionError和UnknowTransactionCommitResult提供错误处理逻辑 |
| 要求为特定事务将显式的逻辑会话传递给API | 要求为特定事务将显式的逻辑会话传递给API |
五、重要参数简介
在MongoDB事务中有两种限制,第一种是时间,控制事务的运行时间、事务等待获取锁的时间以及所有事务运行的最长时间;第二种是MongoDB的oplog条目和单个条目大大小限制;
1、时间限制
事务的默认最大运行时间是1分钟。可以通过修改transactionLifetimeLimitSeconds的限制来增加。对于分片集群,必须在所有分片副本集成员上设置该参数。超过此时间后,事务将被视为已过期,并由定期运行的清理进程终止。清理进程每60秒或transactionLifetimeLimitSeconds/2运行一次,以较小的值为准。
要显式设置事务的时间限制,建议在提交事务时指定maxTimeMS参数。如果maxTimeMS没有设置,那么将使用transactionLifetimeLimitSeconds;如果设置了maxTimeMS,但这个值超过了transactionLifetimeLimitSeconds,那么还是会使用transactionLifetimeLimitSeconds。
事务等待获取其操作所需锁的默认最大时间是 5 毫秒。可以通过修改maxTransactionLockRequestTimeoutMillis参数来控制。如果事务在此期间无法获取锁,则该事务会被终止。
maxTransactionLockRequestTimeoutMillis可以被设置为0、-1或大于0的数字。
- 设置为0,表示如果事务无法立即获得所需的所有锁,则该事务会被终止;
- 设置为-1,将使用由maxTimeMS参数所指定的超时时间;
- 设置为大于0的其它数字,将等待时间配置为该时间,尝试获取锁的等待时间也是该时间,单位秒;
2、oplog大小限制
MongoDB会创建出与事务中写操作数量相同的oplog数目。但是,每个oplog条目必须在16MB的BSON文档大小限制之内。
六、连接池 = 数据库连接的缓存
在最开始接触MongoDB的时候,是通过 MongoDatabase database = new MongoClient("localhost", 27017).getDatabase("test");的方式连接MongoDB。
它会为每个请求创建一个新的连接,然后销毁,一般数据库的连接都是TCP连接,TCP是长连接,如果不断开,就会一直连着。
众所周知,新建一个数据库连接的代价是很大的,复用现有连接才是首选,连接池就是干这个的。
因此当需要新的连接时,就可以复用连接池中缓存的连接了。如果使用得当,连接池可以最大程度的降低数据库的新连接数量、创建频率。
可以通过Mongo.get方法获得DB对象,表示MongoDB数据库的一个连接。默认情况下,当执行完数据库的查询操作后,连接将自动回到连接池中,通过api中的finally方法,将连接归还给连接池,不需要手动调用。
1、MongoDB查询数据五步走
- MongoDB Client需要找到可用的MongoDB;
- Server MongoDB Client需要和 MongoDB Server建立 Connection;
- 应用程序处理线程从 Connection Pool中获取 Connection;
- 数据传输(获取连接后,进行 Socket 通信,获取数据);
- 断开 Collection;

2、MongoDB连接池的参数配置
#线程池允许的最大连接数
connectionsPerHost: 40
#线程池中连接的最大空闲时间
threadsAllowedToBlockForConnectionMultiplier: 20
#1、MongoDB Client需要找到可用的MongoDB Server所需要的等待时间
serverSelectionTimeout: 40000
#2、MongoDB Client需要和MongoDB Server建立(new)Connection
connectTimeout: 60000
#3、应用程序处理线程从Connection Pool中获取Connection
maxWaitTime: 120000
#自动重连
autoConnectRetry: true
#socket是否保活
socketKeepAlive: true
#4、数据传输(获取连接后,进行Socket通信,获取数据)
socketTimeout: 30000
slaveOk: true
dbName: ngo
#是否进行权限验证
auth: false
#用户名
username: ngo
#密码
password: 12345678
七、聚合框架
聚合框架是MongoDB中的一组分析工具,可以对一个或多个集合中的文档进行分析。
聚合框架基于管道的概念,使用聚合管道可以从MongoDB集合获取输入,并将该集合中的文档传递到一个或多个阶段,每个阶段对输入执行不同的操作。每个阶段都将之前阶段输出的内容作为输入。所有阶段的输入和输出都是文档,可以称为文档流。
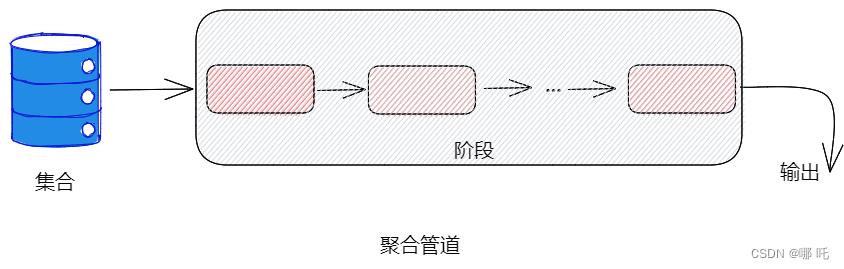
每个阶段都会提供一组按钮或可调参数,可以通过控制它们来设置该阶段的参数,以执行各种任务。
这些可调参数通常采用运算符的形式,可以使用这些运算符来修改字段、执行算术运算、调整文档形状、执行各种累加任务或其它各种操作。
常见的聚合管道包括匹配match、投射project、排序sort、跳过skip、限制limit。
八、MongoDB文档格式设计
文档中表示数据的方式,在进行文档格式设计时,首先需要了解查询和数据访问的方式。
1、限制条件
比如最大文档大小为16MB。
2、查询和写入的访问模式
通过了解查询的运行时间和频率,识别出最常见的查询,一旦确定了这些查询,就应该尽量减少查询的数量,并在文档设计中确保一起查询的数据存储在同一个文档中。
这些查询中未使用的数据应该存放在不同的集合中。需要考虑是否可以将动态数据(读/写)和静态数据(读)分离开。在进行文档格式设计时,提高最常见查询的优先级会获得最佳的性能。
3、关系类型
根据业务逻辑、文档之间的关系来考虑哪些数据是相关的,确定使用嵌入还是引用。需要弄清楚如何在不执行其它查询的情况下引用文档,以及当关系发生变化时需要更新几个文档。还要考虑数据结构是否易于查询。
4、范式化与反范式化
- 范式化是指数据分散在多个集合中,在集合之间进行数据的引用;
- 反范式化会将所有数据嵌入单个文档中;
如何选择范式化与反范式化,范式化的写入速度更快,而反范式化的读取速度更快,因此需要根据应用程序的实际需求进行权衡。
5、内嵌数据和引用数据对比
| 更适合内嵌数据 | 更适合引用数据 |
|---|---|
| 较小子文档 | 较大子文档 |
| 数据不经常变更 | 数据经常变更 |
| 数据最终一致即可 | 必须保证强一致性 |
| 数据通常需要二次查询才能获得 | 数据通常不包含在结果中 |
| 快速读取 | 快速写入 |
6、优化数据操作
优化读操作通常包括正确的索引和单个文档中返回尽可能多的数据;
优化写操作通常包括减少索引数量、尽可能的提高更新效率;
通过删除旧数据进行优化:
第一种方式是通过固定集合实现;
第二种是使用TTL集合。
TTL集合可以更精确的控制删除文档的时间,但在写入量过大的集合中操作速度不够快,通过遍历TTL索引来删除文档。
第三种方式是分库分表。
每个月的文档单独使用一个集合。这种方式实现起来更加复杂,因为需要使用动态集合或数据库名称,可能需要查询多个数据库。
九、小结
- MongoDB从4.0开始支持事务了,MongoDB 是一个 ACID 数据库。它支持原子性、一致性、隔离性和持久性。虽然 MongoDB 支持事务,但在使用它时仍然要谨慎。事务是以性能为代价的;
- 了解MongoDB了如何使用事务以及它的参数配置方案,达到即插即用的效果;
- 对MongoDB查询数据的过程,有了更深层次的理解;
- 领悟了MongoDB连接池的意义;
- 深刻理解了MongoDB文档格式设计思想;
- 总结了MongoDB读写的优化方式;

以上是关于MongoDB 4.0支持事务了,还有多少人想用MySQL呢?的主要内容,如果未能解决你的问题,请参考以下文章