Elasticsearch:使用 rescore 来为过滤后的搜索结果重新打分
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:使用 rescore 来为过滤后的搜索结果重新打分相关的知识,希望对你有一定的参考价值。
Rescore 可以帮助提高精度,方法是仅对 query 和 post_filter 阶段返回的顶部(例如 100 - 500)文档进行重新排序,使用辅助(通常成本更高)算法,而不是将成本算法应用于索引中的所有文档。Rescore 将是一个新查询,它将根据你定义的条件对结果重新排序。 这里的重点是 rescore 仅应用于你的查询首先返回的结果。
在每个分片返回其结果以由处理整个搜索请求的节点排序之前,在每个分片上执行 rescore 请求。
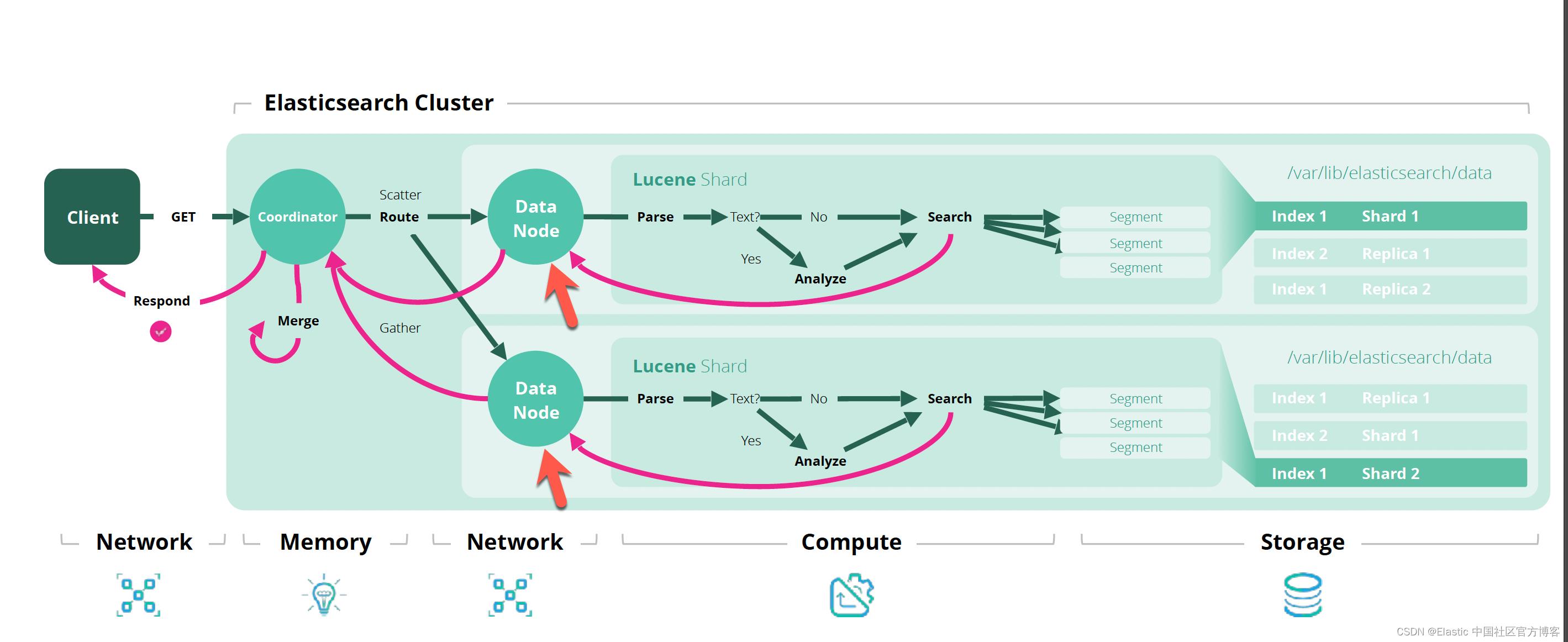
如果你想了解整个搜索流是如何工作的,请详细阅读之前的文章 “Elasticsearch:彻底理解 Elasticsearch 数据操作”。
目前,rescore API 只有一种实现:query rescorer,它使用 query 来调整评分。 将来,可能会提供替代的 rescorer,例如,成对的 rescorer。
注意:如果 rescore 查询提供了显式排序 sort(降序的 _score 除外),则会抛出错误。
注意:当向用户展示分页时,你不应在浏览每个页面时更改 window_size(通过传递不同 from 的值),因为这会改变 top hits 值,导致结果在用户浏览页面时发生混乱的变化。
Query rescorer
Query rescorer 仅对 query 和 post_filter 阶段返回的 Top-K 结果执行第二个查询。 将在每个分片上检查的文档数量可以通过 window_size 参数控制,默认为 10。
默认情况下,原始查询和 rescore 查询的分数线性组合以生成每个文档的最终 _score。 原始查询和 rescore 查询的相对重要性可以分别用 query_weight 和 rescore_query_weight 控制。 两者都默认为 1。比如:
POST /_search
"query" :
"match" :
"message" :
"operator" : "or",
"query" : "the quick brown"
,
"rescore" :
"window_size" : 50,
"query" :
"rescore_query" :
"match_phrase" :
"message" :
"query" : "the quick brown",
"slop" : 2
,
"query_weight" : 0.7,
"rescore_query_weight" : 1.2
分数的组合方式可以通过 score_mode 来控制:
| Score mode | 描述 |
|---|---|
| total | 添加原始分数和重新分数查询分数。 默认值。 |
| multiply | 将原始分数乘以 rescore 查询分数。 对 function query 重新评分很有用。 |
| avg | 平均原始分数和 rescore 查询分数。 |
| max | 取原始分数和 rescore 查询分数的最大值。 |
| min | 取原始分数和 rescore 查询分数的最小值。 |
多个 rescore
也可以按顺序执行多个重新评分:
POST /_search
"query" :
"match" :
"message" :
"operator" : "or",
"query" : "the quick brown"
,
"rescore" : [
"window_size" : 100,
"query" :
"rescore_query" :
"match_phrase" :
"message" :
"query" : "the quick brown",
"slop" : 2
,
"query_weight" : 0.7,
"rescore_query_weight" : 1.2
,
"window_size" : 10,
"query" :
"score_mode": "multiply",
"rescore_query" :
"function_score" :
"script_score":
"script":
"source": "Math.log10(doc.count.value + 2)"
]
第一个获取查询结果,然后第二个获取第一个的结果,依此类推。 第二个分数将 “看到” 第一个分数完成的排序,因此可以在第一个分数上使用大窗口将文档拉入第二个分数的较小窗口。
例子
我们首先来说使用如下命令来创建一个叫做 movies 的索引:
PUT movies
"settings":
"analysis":
"analyzer":
"en_analyzer":
"tokenizer": "standard",
"filter": [
"lowercase",
"stop"
]
,
"shingle_analyzer":
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"shingle_filter"
]
,
"filter":
"shingle_filter":
"type": "shingle",
"min_shingle_size": 2,
"max_shingle_size": 3
,
"mappings":
"properties":
"title":
"type": "text",
"analyzer": "en_analyzer",
"fields":
"suggest":
"type": "text",
"analyzer": "shingle_analyzer"
,
"actors":
"type": "text",
"analyzer": "en_analyzer",
"fields":
"keyword":
"type": "keyword",
"ignore_above": 256
,
"description":
"type": "text",
"analyzer": "en_analyzer",
"fields":
"keyword":
"type": "keyword",
"ignore_above": 256
,
"director":
"type": "text",
"fields":
"keyword":
"type": "keyword",
"ignore_above": 256
,
"genre":
"type": "text",
"fields":
"keyword":
"type": "keyword",
"ignore_above": 256
,
"metascore":
"type": "long"
,
"rating":
"type": "float"
,
"revenue":
"type": "float"
,
"runtime":
"type": "long"
,
"votes":
"type": "long"
,
"year":
"type": "long"
,
"title_suggest":
"type": "completion",
"analyzer": "simple",
"preserve_separators": true,
"preserve_position_increments": true,
"max_input_length": 50
我们接下来使用 _bulk 命令来写入一些文档到这个索引中去。我们使用这个链接中的内容。我们使用如下的方法:
POST movies/_bulk
"index":
"title": "Guardians of the Galaxy", "genre": "Action,Adventure,Sci-Fi", "director": "James Gunn", "actors": "Chris Pratt, Vin Diesel, Bradley Cooper, Zoe Saldana", "description": "A group of intergalactic criminals are forced to work together to stop a fanatical warrior from taking control of the universe.", "year": 2014, "runtime": 121, "rating": 8.1, "votes": 757074, "revenue": 333.13, "metascore": 76
"index":
"title": "Prometheus", "genre": "Adventure,Mystery,Sci-Fi", "director": "Ridley Scott", "actors": "Noomi Rapace, Logan Marshall-Green, Michael Fassbender, Charlize Theron", "description": "Following clues to the origin of mankind, a team finds a structure on a distant moon, but they soon realize they are not alone.", "year": 2012, "runtime": 124, "rating": 7, "votes": 485820, "revenue": 126.46, "metascore": 65
....在上面,为了说明的方便,我省去了其它的文档。你需要把整个 movies.txt 的文件拷贝过来,并全部写入到 Elasticsearch 中。它共有1000 个文档。
现在让我们运行一些测试。 我的第一个查询将没有 rescore,让我们分析结果。
GET movies/_search
"_source": ["title","year"],
"query":
"match":
"title": "hunger games"
上面命令运行的结果为:
"took": 3,
"timed_out": false,
"_shards":
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
,
"hits":
"total":
"value": 6,
"relation": "eq"
,
"max_score": 10.52117,
"hits": [
"_index": "movies",
"_id": "sJBkU4YBE_j_JbcsK5n0",
"_score": 10.52117,
"_source":
"title": "The Hunger Games",
"year": 2012
,
"_index": "movies",
"_id": "W5BkU4YBE_j_JbcsK5v0",
"_score": 7.5008345,
"_source":
"title": "The Hunger Games: Catching Fire",
"year": 2013
,
"_index": "movies",
"_id": "x5BkU4YBE_j_JbcsK5v0",
"_score": 6.5867085,
"_source":
"title": "Hunger",
"year": 2008
,
"_index": "movies",
"_id": "sZBkU4YBE_j_JbcsK5r0",
"_score": 6.559334,
"_source":
"title": "The Hunger Games: Mockingjay - Part 2",
"year": 2015
,
"_index": "movies",
"_id": "wZBkU4YBE_j_JbcsK5v0",
"_score": 6.559334,
"_source":
"title": "The Hunger Games: Mockingjay - Part 1",
"year": 2014
,
"_index": "movies",
"_id": "1ZBkU4YBE_j_JbcsK5v0",
"_score": 5.260585,
"_source":
"title": "Funny Games",
"year": 2007
]
请注意,我们只有默认的 Elasticsearch 排序。 看到对于我们的搜索条件,“ hunger games” 的结果是较旧的电影。得分最高的电影是 2012 年发布的 “The Hunger Games”。我们希望对于这组结果,较新的电影有一个提升,使它们变得比旧电影更相关。为此,我们将使用 rescorer 查询并添加一个标准,即对于 2013 年以上的任何电影都会添加提升值。 注意 score_query_weight = 5 代表我们想要的。为了降低主要查询文档的分数,让我们将提升更改为 0.5 (query_weight = 0.5)。
GET movies/_search
"_source": [
"title",
"year"
],
"query":
"match":
"title": "hunger games"
,
"rescore":
"query":
"rescore_query":
"range":
"year":
"gte": 2013
,
"score_mode": "total",
"query_weight": 0.5,
"rescore_query_weight": 5
,
"window_size": 50
上面命令运行的结果为:
"took": 3,
"timed_out": false,
"_shards":
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
,
"hits":
"total":
"value": 6,
"relation": "eq"
,
"max_score": 8.750418,
"hits": [
"_index": "movies",
"_id": "W5BkU4YBE_j_JbcsK5v0",
"_score": 8.750418,
"_source":
"title": "The Hunger Games: Catching Fire",
"year": 2013
,
"_index": "movies",
"_id": "sZBkU4YBE_j_JbcsK5r0",
"_score": 8.279667,
"_source":
"title": "The Hunger Games: Mockingjay - Part 2",
"year": 2015
,
"_index": "movies",
"_id": "wZBkU4YBE_j_JbcsK5v0",
"_score": 8.279667,
"_source":
"title": "The Hunger Games: Mockingjay - Part 1",
"year": 2014
,
"_index": "movies",
"_id": "sJBkU4YBE_j_JbcsK5n0",
"_score": 5.260585,
"_source":
"title": "The Hunger Games",
"year": 2012
,
"_index": "movies",
"_id": "x5BkU4YBE_j_JbcsK5v0",
"_score": 3.2933543,
"_source":
"title": "Hunger",
"year": 2008
,
"_index": "movies",
"_id": "1ZBkU4YBE_j_JbcsK5v0",
"_score": 2.6302924,
"_source":
"title": "Funny Games",
"year": 2007
]
从上面的搜索结果我们可以看出来 2013 的电影 “The Hunger Games: Catching Fire” 现在排在第一名的位置,而之前的那个 2012 年的电影现在排名在第四的位置。也就是说我们对 2013 后的电影的搜索结果进行了加分。
Rescore 是一个很好的重新排序资源,可以根据你定义的最佳排序标准帮助你提高结果列表的效率。
以上是关于Elasticsearch:使用 rescore 来为过滤后的搜索结果重新打分的主要内容,如果未能解决你的问题,请参考以下文章