面试官:简单说下 okHttp原理分析~
Posted 初一十五啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官:简单说下 okHttp原理分析~相关的知识,希望对你有一定的参考价值。
面试可能会问到的问题
- 简单说一下okhttp
- okhttp的核心类有哪些?
- okhttp对于网络请求做了哪些优化,如何实现的?
- okhttp架构中用到了哪些设计模式?
- okhttp拦截器的执行顺序
okhttp请求过程
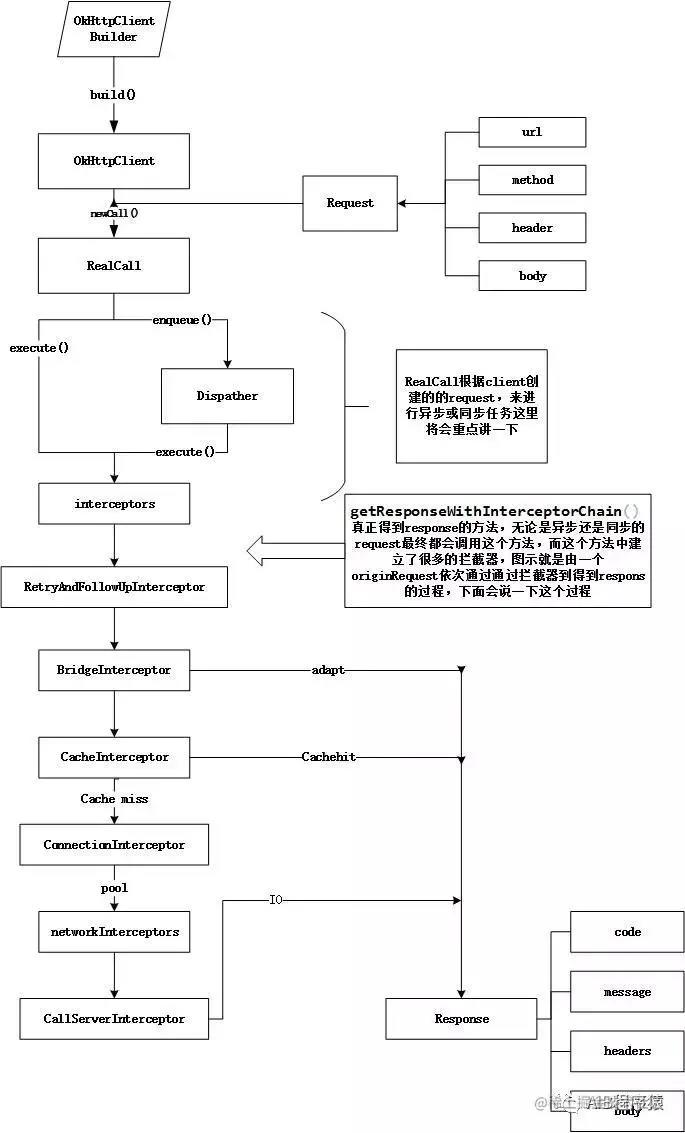
这种图四okhttp请求的全部过程
先看看正常代码里怎么使用
/**
* 异步get请求
*/
public static void get()
//1.创建OkHttpClient对象
OkHttpClient okHttpClient =new OkHttpClient.Builder().retryOnConnectionFailure(true).connectTimeout(3000, TimeUnit.SECONDS).build();
//2.创建Request对象,设置一个url地址,设置请求方式。
Request request = new Request.Builder().url("http://xxxx")
.method("GET", null)
.build();
//3.创建一个call对象,参数就是Request请求对象
Call call = okHttpClient.newCall(request);
//4.请求加入调度,重写回调方法
call.enqueue(new Callback()
//请求失败执行的方法
@Override
public void onFailure(Call call, IOException e)
Log.d(TAG, "onFailure: 失败===》" + e.getMessage());
//请求成功执行的方法
@Override
public void onResponse(Call call, Response response) throws IOException
Log.d(TAG, "onResponse: " + response.body().string());
);
无论什么请求都需要用到okhttpclient,我们可以通过new的方式也可以通过Builder(建造者模式)的方式获取。显然这个方法也是用来初始化一些配置参数的。为了不占空间就不贴源码了。 接着okhttpClient会调用newCall方法,这个方法把请求的参数传入。下面开始时源码
/**
* Prepares the @code request to be executed at some point in the future.
*/
@Override public Call newCall(Request request)
return RealCall.newRealCall(this, request, false /* for web socket */);
返回一个RealCall 这个类把okhttpclient和请求参数做了封装,执行execute或者enqueue真正开始执行请求。
enqueque()
@Override public void enqueue(Callback responseCallback)
synchronized (this)
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
captureCallStackTrace();
eventListener.callStart(this);
client.dispatcher().enqueue(new AsyncCall(responseCallback));
先看看我们用的比较多的异步请求enqueue,实际上在enqueque方法中把请求交给了okhttpClient里面封装的dispatch(任务调度器) 的enqueue。所以看看Dispatch这个类
Dispatch 任务调度器
成员变量如下.
/**最大并发数**/
private int maxRequests = 64;
/**每个主机最大请求数**/
private int maxRequestsPerHost = 5;
private @Nullable Runnable idleCallback;
/** 线程池 Executes calls. Created lazily. */
private @Nullable ExecutorService executorService;
/**正在等待的异步双端队列 Ready async calls in the order they'll be run. */
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>();
/** 正在运行的异步双端队列 Running asynchronous calls. Includes canceled calls that haven't finished yet. */
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();
/** 正在运行的同步双端队列 Running synchronous calls. Includes canceled calls that haven't finished yet. */
private final Deque<RealCall> runningSyncCalls = new ArrayDeque<>();
再看看构造方法
public Dispatcher(ExecutorService executorService)
this.executorService = executorService;
public Dispatcher()
public synchronized ExecutorService executorService()
if (executorService == null)
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue<>(), Util.threadFactory("OkHttp Dispatcher", false));
return executorService;
如果有配置线程池就用配置的,如果没有就用默认的。这里感觉跟系统的Asynctask差不多。默认的适合执行大量耗时比较少的操作,提供自定义线程池一般看需求,不过一般用默认的就够了。回到Dispatch的enqueue方法
void enqueue(AsyncCall call)
synchronized (this)
readyAsyncCalls.add(call);
promoteAndExecute();
/**
* Promotes eligible calls from @link #readyAsyncCalls to @link #runningAsyncCalls and runs
* them on the executor service. Must not be called with synchronization because executing calls
* can call into user code.
*
* @return true if the dispatcher is currently running calls.
*/
private boolean promoteAndExecute()
assert (!Thread.holdsLock(this));
List<AsyncCall> executableCalls = new ArrayList<>();
boolean isRunning;
synchronized (this)
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); )
AsyncCall asyncCall = i.next();
if (runningAsyncCalls.size() >= maxRequests) break; // Max capacity.
if (runningCallsForHost(asyncCall) >= maxRequestsPerHost) continue; // Host max capacity.
i.remove();
executableCalls.add(asyncCall);
runningAsyncCalls.add(asyncCall);
isRunning = runningCallsCount() > 0;
for (int i = 0, size = executableCalls.size(); i < size; i++)
AsyncCall asyncCall = executableCalls.get(i);
asyncCall.executeOn(executorService());
return isRunning;
这里的代码跟之前的版本不一样了,看了篇博客以前的代码是这样的。
synchronized void enqueue(AsyncCall call)
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost)
runningAsyncCalls.add(call);
executorService().execute(call);
else
readyAsyncCalls.add(call);
为什么改成这样,我们来问问ChatGPT😁

不得不说,ChatGPT真的很强,非常推荐使用
简单的说手动变变成自动了,总归enqueue这个方法的判断是没有变的,最后都调用到了asyncCall.executeOn(executorService()); 最后调用的也是executorService().execute(call);
再来看看的aysncCalls源码
final class AsyncCall extends NamedRunnable
private final Callback responseCallback;
AsyncCall(Callback responseCallback)
super("OkHttp %s", redactedUrl());
this.responseCallback = responseCallback;
String host()
return originalRequest.url().host();
Request request()
return originalRequest;
RealCall get()
return RealCall.this;
/**
* Attempt to enqueue this async call on @code executorService. This will attempt to clean up
* if the executor has been shut down by reporting the call as failed.
*/
void executeOn(ExecutorService executorService)
assert (!Thread.holdsLock(client.dispatcher()));
boolean success = false;
try
executorService.execute(this);
success = true;
catch (RejectedExecutionException e)
InterruptedIOException ioException = new InterruptedIOException("executor rejected");
ioException.initCause(e);
eventListener.callFailed(RealCall.this, ioException);
responseCallback.onFailure(RealCall.this, ioException);
finally
if (!success)
client.dispatcher().finished(this); // This call is no longer running!
@Override protected void execute()
boolean signalledCallback = false;
timeout.enter();
try
Response response = getResponseWithInterceptorChain();
if (retryAndFollowUpInterceptor.isCanceled())
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
else
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
catch (IOException e)
e = timeoutExit(e);
if (signalledCallback)
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
else
eventListener.callFailed(RealCall.this, e);
responseCallback.onFailure(RealCall.this, e);
finally
client.dispatcher().finished(this);
其实我们还有一个地方没有看,同步请求,结合一起看可能会更好理解
@Override public Response execute() throws IOException
if (originalRequest.body instanceof DuplexRequestBody)
DuplexRequestBody duplexRequestBody = (DuplexRequestBody) originalRequest.body;
return duplexRequestBody.awaitExecute();
synchronized (this)
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
captureCallStackTrace();
timeout.enter();
eventListener.callStart(this);
try
client.dispatcher().executed(this);
Response result = getResponseWithInterceptorChain();
if (result == null) throw new IOException("Canceled");
return result;
catch (IOException e)
e = timeoutExit(e);
eventListener.callFailed(this, e);
throw e;
finally
client.dispatcher().finished(this);
同步执行的excute方法是RellCall里面的方法,和AsyncCall里面的excute都句关键的代码。
Response response = getResponseWithInterceptorChain()
这里的代码先不看,这个是同步和异步后续要执行的动作。同样的同步执行的excute也会经过调度器,但是通过源码发现,这里只是单纯的添加到容器和从容器中删除。这样做目的是为了方便统一取消请求以及需要记录请求数量(异步+同步)。
来到这里 可以发现,Dispatcher的作用跟它的命名一样是用来调度的,如果是异步请求会在这里创建线程池、把异步同步的任务分配到asyncCalls执行。如果是同步把请求添加到双端队列中。而RellCall则是封装了okhttpclient以及请求request(请求参数)的请求的发起类。
接着看
Response getResponseWithInterceptorChain() throws IOException
// 添加一系列拦截器,注意添加的顺序
List<Interceptor> interceptors = new ArrayList<>();
interceptors.addAll(client.interceptors());
interceptors.add(retryAndFollowUpInterceptor);
// 桥拦截器
interceptors.add(new BridgeInterceptor(client.cookieJar()));
// 缓存拦截器:从缓存中拿数据
interceptors.add(new CacheInterceptor(client.internalCache()));
// 网络连接拦截器:建立网络连接
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket)
interceptors.addAll(client.networkInterceptors());
// 服务器请求拦截器:向服务器发起请求获取数据
interceptors.add(new CallServerInterceptor(forWebSocket));
// 构建一条责任链
Interceptor.Chain chain = new RealInterceptorChain(interceptors, null, null, null, 0,
originalRequest, this, eventListener, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
// 处理责任链
return chain.proceed(originalRequest);
这个方法添加了一堆拦截器,并且可以看到有Chain,这里是一个责任链模式。
再看看proceed方法到底做了什么
public Response proceed(Request request, StreamAllocation streamAllocation, HttpCodec httpCodec,
RealConnection connection) throws IOException
...
// Call the next interceptor in the chain.
RealInterceptorChain next = new RealInterceptorChain(interceptors, streamAllocation, httpCodec,
connection, index + 1, request, call, eventListener, connectTimeout, readTimeout,
writeTimeout);
Interceptor interceptor = interceptors.get(index);
Response response = interceptor.intercept(next);
...
return response;
会发现其实调用了proceed时因为index每次+1会经过下一个拦截器,当下一个拦截器内部调用proceed时会以此类推的往下执行。回想一下我们自定义拦截器时,最后必然会返回的就是proceed方法。
return chain.proceed(builder.build());
如果不再深入拦截器的话到这里其实已经可以结束了,因为通过拦截器我们已经拿到了要返回的Response。下面是开头调用的例子
responseCallback.onResponse(RealCall.this, response);
分析到这里的大概流程
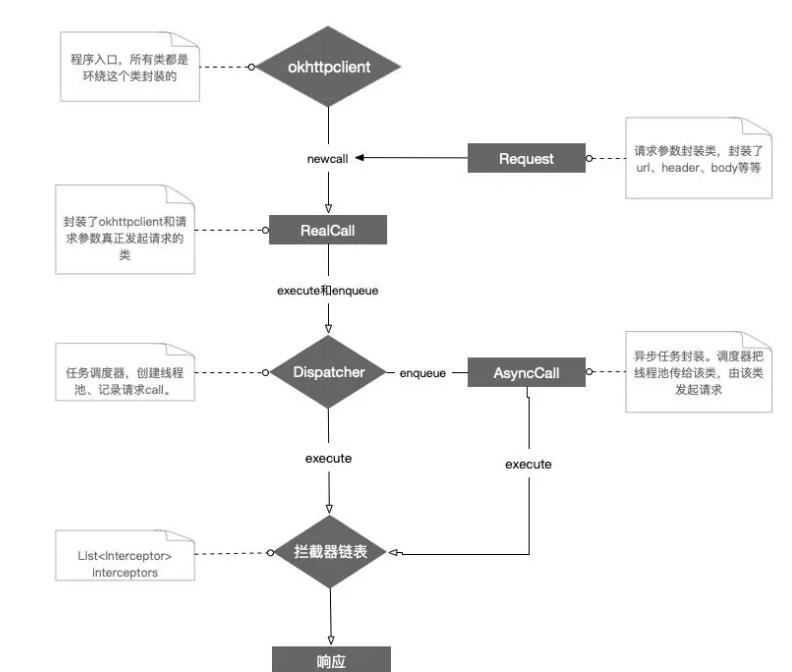
拦截器
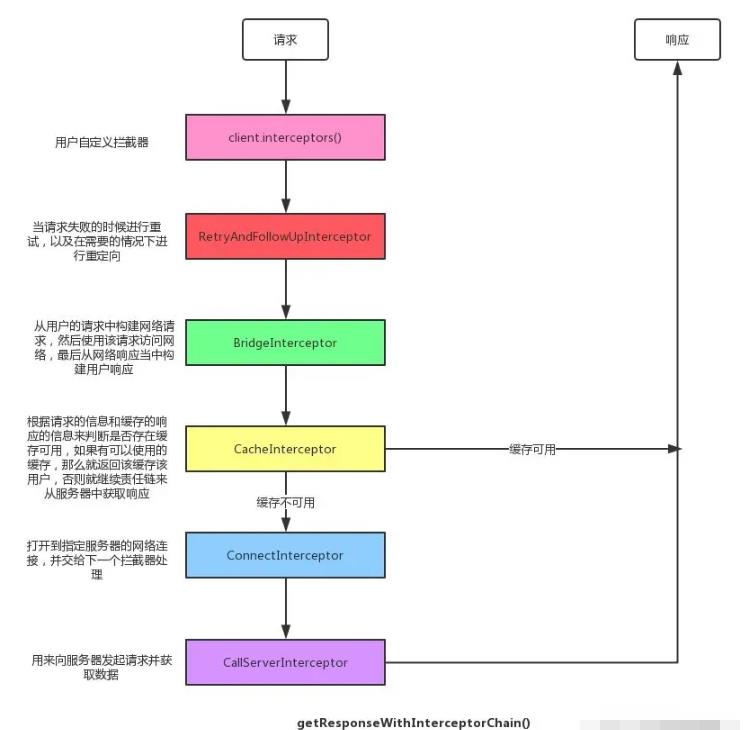
别人博客的一张图,对应源码其实可以知道,一开始添加的是自定义intercept的list。而随后依次添加的拦截器依次的作用是:重连重定向–>构建请求参数–>缓存(如果有则事件在这里消耗)–>网络请求
失败重连:RetryAndFollowUpInterceptor
@Override public Response intercept(Chain chain) throws IOException
// ...
// 注意这里我们初始化了一个 StreamAllocation 并赋值给全局变量,它的作用我们后面会提到
StreamAllocation streamAllocation = new StreamAllocation(client.connectionPool(),
createAddress(request.url()), call, eventListener, callStackTrace);
this.streamAllocation = streamAllocation;
// 用来记录重定向的次数
int followUpCount = 0;
Response priorResponse = null;
while (true)
if (canceled)
streamAllocation.release();
throw new IOException("Canceled");
Response response;
boolean releaseConnection = true;
try
// 这里从当前的责任链开始执行一遍责任链,是一种重试的逻辑
response = realChain.proceed(request, streamAllocation, null, null);
releaseConnection = false;
catch (RouteException e)
// 调用 recover 方法从失败中进行恢复,如果可以恢复就返回true,否则返回false
if (!recover(e.getLastConnectException(), streamAllocation, false, request))
throw e.getLastConnectException();
releaseConnection = false;
continue;
catch (IOException e)
// 重试与服务器进行连接
boolean requestSendStarted = !(e instanceof ConnectionShutdownException);
if (!recover(e, streamAllocation, requestSendStarted, request)) throw e;
releaseConnection = false;
continue;
finally
// 如果 releaseConnection 为 true 则表明中间出现了异常,需要释放资源
if (releaseConnection)
streamAllocation.streamFailed(null);
streamAllocation.release();
// 使用之前的响应 priorResponse 构建一个响应,这种响应的响应体 body 为空
if (priorResponse != null)
response = response.newBuilder()
.priorResponse(priorResponse.newBuilder().body(null).build())
.build();
// 根据得到的响应进行处理,可能会增加一些认证信息、重定向或者处理超时请求
// 如果该请求无法继续被处理或者出现的错误不需要继续处理,将会返回 null
Request followUp = followUpRequest(response, streamAllocation.route());
// 无法重定向,直接返回之前的响应
if (followUp == null)
if (!forWebSocket)
streamAllocation.release();
return response;
// 关闭资源
closeQuietly(response.body());
// 达到了重定向的最大次数,就抛出一个异常
if (++followUpCount > MAX_FOLLOW_UPS)
streamAllocation.release();
throw new ProtocolException("Too many follow-up requests: " + followUpCount);
if (followUp.body() instanceof UnrepeatableRequestBody)
streamAllocation.release();
throw new HttpRetryException("Cannot retry streamed HTTP body", response.code());
// 这里判断新的请求是否能够复用之前的连接,如果无法复用,则创建一个新的连接
if (!sameConnection(response, followUp.url()))
streamAllocation.release();
streamAllocation = new StreamAllocation(client.connectionPool(),
createAddress(followUp.url()), call, eventListener, callStackTrace);
this.streamAllocation = streamAllocation;
else if (streamAllocation.codec() != null)
throw new IllegalStateException("Closing the body of " + response
+ " didn't close its backing stream. Bad interceptor?");
request = followUp;
priorResponse = response;
intercept方法是每个拦截器的核心方法,重连主要做的事情是,重连超过默认次数MAX_FOLLOW_UPS(20)抛出异常,连接成功则将请求和重连结果一并传给下一个拦截器。
桥接拦截器: BridgeInterceptor
...
requestBuilder.header("Content-Type", contentType.toString())
requestBuilder.header("Content-Length", contentLength.toString())
...
桥接拦截器主要做的事情是构建请求参数,以前我们会有个疑问就是都说okhttp是基于socket的而不是基于http的,答案就在这里,它手动构建了请求。socket只是一个通讯的通道类,可以理解为公路,而http跟udp这些可以理解为国道、省道、高速公路,他们有自己的规则,而这里构建的就是http的规则。
使用缓存:CacheInterceptor
public final class CacheInterceptor implements Interceptor
@Override public Response intercept(Chain chain) throws IOException
Response cacheCandidate = cache != null ? cache.get(chain.request()) : null;
long now = System.currentTimeMillis();
// 根据请求和缓存的响应中的信息来判断是否存在缓存可用
CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();
Request networkRequest = strategy.networkRequest; // 如果该请求没有使用网络就为空
Response cacheResponse = strategy.cacheResponse; // 如果该请求没有使用缓存就为空
if (cache != null)
cache.trackResponse(strategy);
if (cacheCandidate != null && cacheResponse == null)
closeQuietly(cacheCandidate.body());
// 请求不使用网络并且不使用缓存,相当于在这里就拦截了,没必要交给下一级(网络请求拦截器)来执行
if (networkRequest == null && cacheResponse == null)
return new Response.Builder()
.request(chain.request())
.protocol(Protocol.HTTP_1_1)
.code(504)
.message("Unsatisfiable Request (only-if-cached)")
.body(Util.EMPTY_RESPONSE)
.sentRequestAtMillis(-1L)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
// 该请求使用缓存,但是不使用网络:从缓存中拿结果,没必要交给下一级(网络请求拦截器)执行
if (networkRequest == null)
return cacheResponse.newBuilder().cacheResponse(stripBody(cacheResponse)).build();
Response networkResponse = null;
try
// 这里调用了执行链的处理方法,实际就是交给自己的下一级来执行了
networkResponse = chain.proceed(networkRequest);
finally
if (networkResponse == null && cacheCandidate != null)
closeQuietly(cacheCandidate.body());
// 这里当拿到了网络请求之后调用,下一级执行完毕会交给它继续执行,如果使用了缓存就把请求结果更新到缓存里
if (cacheResponse != null)
// 服务器返回的结果是304,返回缓存中的结果
if (networkResponse.code() == HTTP_NOT_MODIFIED)
Response response = cacheResponse.newBuilder()
.headers(combine(cacheResponse.headers(), networkResponse.headers()))
.sentRequestAtMillis(networkResponse.sentRequestAtMillis())
.receivedResponseAtMillis(networkResponse.receivedResponseAtMillis())
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
networkResponse.body().close();
cache.trackConditionalCacheHit();
// 更新缓存
cache.update(cacheResponse, response);
return response;
else
closeQuietly(cacheResponse.body());
Response response = networkResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
// 把请求的结果放进缓存里
if (cache != null)
if (HttpHeaders.hasBody(response) && CacheStrategy.isCacheable(response, networkRequest))
CacheRequest cacheRequest = cache.put(response);
return cacheWritingResponse(cacheRequest, response);
if (HttpMethod.invalidatesCache(networkRequest.method()))
try
cache.remove(networkRequest);
catch (IOException ignored)
// The cache cannot be written.
return response;
缓存拦截器会根据请求的信息和缓存的响应的信息来判断是否存在缓存可用,如果有可以使用的缓存,那么就返回该缓存给用户,否则就继续使用责任链模式来从服务器中获取响应。当获取到响应的时候,又会把响应缓存到磁盘上面。 缓存均基于map来缓存,key是请求中url的md5,value是文件中查询到的缓存,页面基于LRU算法。cacheCandidate是一个可以读取到Header和Response的类。总结做了以下几件事情
- cache若不为空则赋给cacheCandidate对象
- 获取缓存策略可以自己定义,默认为
Cachecontrol.FORCE_NETWORK强制使用网络,也可以设置为FORCE_CACHE强制使用本地缓存,如果没有缓存可用返回504 - 在不为空且有缓存策略时,若返回304则直接响应缓存创建Response返回
- 若无网无缓存返回504
- 在有缓存策略但没有缓存时调用cache的put方法进行缓存
连接:ConnectInterceptor
public Response intercept(Chain chain) throws IOException
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
StreamAllocation streamAllocation = realChain.streamAllocation();
// We need the network to satisfy this request. Possibly for validating a conditional GET.
boolean doExtensiveHealthChecks = !request.method().equals("GET");
HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
return realChain.proceed(request, streamAllocation, httpCodec, connection);
连接拦截器主要做了两件事情
- 加上url生成一个真正的请求的流
RealConnection - 将流和httpCode一并交给下一层拦截器进行请求,并返回Response 所以这里只是向服务器发起连接,而且真正的连接只是在RealConnection里面。
请求: CallServerInterceptor
public final class CallServerInterceptor implements Interceptor
@Override public Response intercept(Chain chain) throws IOException
RealInterceptorChain realChain = (RealInterceptorChain) chain;
// 获取 ConnectInterceptor 中初始化的 HttpCodec
HttpCodec httpCodec = realChain.httpStream();
// 获取 RetryAndFollowUpInterceptor 中初始化的 StreamAllocation
StreamAllocation streamAllocation = realChain.streamAllocation();
// 获取 ConnectInterceptor 中初始化的 RealConnection
RealConnection connection = (RealConnection) realChain.connection();
Request request = realChain.request();
long sentRequestMillis = System.currentTimeMillis();
realChain.eventListener().requestHeadersStart(realChain.call());
// 在这里写入请求头
httpCodec.writeRequestHeaders(request);
realChain.eventListener().requestHeadersEnd(realChain.call(), request);
Response.Builder responseBuilder = null;
if (HttpMethod.permitsRequestBody(request.method()) && request.body() != null)
if ("100-continue".equalsIgnoreCase(request.header("Expect")))
httpCodec.flushRequest();
realChain.eventListener().responseHeadersStart(realChain.call());
responseBuilder = httpCodec.readResponseHeaders(true);
// 在这里写入请求体
if (responseBuilder == null)
realChain.eventListener().requestBodyStart(realChain.call());
long contentLength = request.body().contentLength();
CountingSink requestBodyOut =
new CountingSink(httpCodec.createRequestBody(request, contentLength));
BufferedSink bufferedRequestBody = Okio.buffer(requestBodyOut);
// 写入请求体
request.body().writeTo(bufferedRequestBody);
bufferedRequestBody.close();
realChain.eventListener()
.requestBodyEnd(realChain.call(), requestBodyOut.successfulCount);
else if (!connection.isMultiplexed())
streamAllocation.noNewStreams();
httpCodec.finishRequest();
if (responseBuilder == null)
realChain.eventListener().responseHeadersStart(realChain.call());
// 读取响应头
responseBuilder = httpCodec.readResponseHeaders(false);
Response response = responseBuilder
.request(request)
.handshake(streamAllocation.connection().handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
// 读取响应体
int code = response.code();
if (code == 100)
responseBuilder = httpCodec.readResponseHeaders(false);
response = responseBuilder
.request(request)
.handshake(streamAllocation.connection().handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
code = response.code();
realChain.eventListener().responseHeadersEnd(realChain.call(), response);
if (forWebSocket && code == 101)
response = response.newBuilder()
.body(Util.EMPTY_RESPONSE)
.build();
else
response = response.newBuilder()
.body(httpCodec.openResponseBody(response))
.build();
// ...
return response;
主要做的事情1.发起请求2.完成读写3.根据返回码处理结果4.关闭连接。
责任链最后一个拦截器,拿到请求结果后返回给上一级。
复用连接池
private final ConnectionPool connectionPool;
里面有个复用连接池,其实就是类似于线程池。就是我们想知道的连接复用的最核心的地方了。
public final class ConnectionPool
/**
* Background threads are used to cleanup expired connections. There will be at most a single
* thread running per connection pool. The thread pool executor permits the pool itself to be
* garbage collected.
*/
private static final Executor executor = new ThreadPoolExecutor(0 /* corePoolSize */,
Integer.MAX_VALUE /* maximumPoolSize */, 60L /* keepAliveTime */, TimeUnit.SECONDS,
new SynchronousQueue<>(), Util.threadFactory("OkHttp ConnectionPool", true));
/** The maximum number of idle connections for each address. */
private final int maxIdleConnections;
private final long keepAliveDurationNs;
private final Runnable cleanupRunnable = () ->
while (true)
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -1) return;
if (waitNanos > 0)
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
synchronized (ConnectionPool.this)
try
ConnectionPool.this.wait(waitMillis, (int) waitNanos);
catch (InterruptedException ignored)
;
private final Deque<RealConnection> connections = new ArrayDeque<>();
final RouteDatabase routeDatabase = new RouteDatabase();
boolean cleanupRunning;
/**
* Create a new connection pool with tuning parameters appropriate for a single-user application.
* The tuning parameters in this pool are subject to change in future OkHttp releases. Currently
* this pool holds up to 5 idle connections which will be evicted after 5 minutes of inactivity.
*/
public ConnectionPool()
this(5, 5, TimeUnit.MINUTES);
public ConnectionPool(int maxIdleConnections, long keepAliveDuration, TimeUnit timeUnit)
this.maxIdleConnections = maxIdleConnections;
this.keepAliveDurationNs = timeUnit.toNanos(keepAliveDuration);
// Put a floor on the keep alive duration, otherwise cleanup will spin loop.
if (keepAliveDuration <= 0)
throw new IllegalArgumentException("keepAliveDuration <= 0: " + keepAliveDuration);
/** Returns the number of idle connections in the pool. */
public synchronized int idleConnectionCount()
int total = 0;
for (RealConnection connection : connections)
if (connection.allocations.isEmpty()) total++;
return total;
/** Returns total number of connections in the pool. */
public synchronized int connectionCount()
return connections.size();
/**
* Acquires a recycled connection to @code address for @code streamAllocation. If non-null
* @code route is the resolved route for a connection.
*/
void acquire(Address address, StreamAllocation streamAllocation, @Nullable Route route)
assert (Thread.holdsLock(this));
for (RealConnection connection : connections)
if (connection.isEligible(address, route))
streamAllocation.acquire(connection, true);
return;
/**
* Replaces the connection held by @code streamAllocation with a shared connection if possible.
* This recovers when multiple multiplexed connections are created concurrently.
*/
@Nullable Socket deduplicate(Address address, StreamAllocation streamAllocation)
assert (Thread.holdsLock(this));
for (RealConnection connection : connections)
if (connection.isEligible(address, null)
&& connection.isMultiplexed()
&& connection != streamAllocation.connection())
return streamAllocation.releaseAndAcquire(connection);
return null;
void put(RealConnection connection)
assert (Thread.holdsLock(this));
if (!cleanupRunning)
cleanupRunning = true;
executor.execute(cleanupRunnable);
connections.add(connection);
/**
* Notify this pool that @code connection has become idle. Returns true if the connection has
* been removed from the pool and should be closed.
*/
boolean connectionBecameIdle(RealConnection connection)
assert (Thread.holdsLock(this));
if (connection.noNewStreams || maxIdleConnections == 0)
connections.remove(connection);
return true;
else
notifyAll(); // Awake the cleanup thread: we may have exceeded the idle connection limit.
return false;
/** Close and remove all idle connections in the pool. */
public void evictAll()
List<RealConnection> evictedConnections = new ArrayList<>();
synchronized (this)
for (Iterator<RealConnection> i = connections.iterator(); i.hasNext(); )
RealConnection connection = i.next();
if (connection.allocations.isEmpty())
connection.noNewStreams = true;
evictedConnections.add(connection);
i.remove();
for (RealConnection connection : evictedConnections)
closeQuietly(connection.socket());
/**
* Performs maintenance on this pool, evicting the connection that has been idle the longest if
* either it has exceeded the keep alive limit or the idle connections limit.
*
* <p>Returns the duration in nanos to sleep until the next scheduled call to this method. Returns
* -1 if no further cleanups are required.
*/
long cleanup(long now)
int inUseConnectionCount = 0;
int idleConnectionCount = 0;
RealConnection longestIdleConnection = null;
long longestIdleDurationNs = Long.MIN_VALUE;
// Find either a connection to evict, or the time that the next eviction is due.
synchronized (this)
for (Iterator<RealConnection> i = connections.iterator(); i.hasNext(); )
RealConnection connection = i.next();
// If the connection is in use, keep searching.
if (pruneAndGetAllocationCount(connection, now) > 0)
inUseConnectionCount++;
continue;
idleConnectionCount++;
// If the connection is ready to be evicted, we're done.
long idleDurationNs = now - connection.idleAtNanos;
if (idleDurationNs > longestIdleDurationNs)
longestIdleDurationNs = idleDurationNs;
longestIdleConnection = connection;
if (longestIdleDurationNs >= this.keepAliveDurationNs
|| idleConnectionCount > this.maxIdleConnections)
// We've found a connection to evict. Remove it from the list, then close it below (outside
// of the synchronized block).
connections.remove(longestIdleConnection);
else if (idleConnectionCount > 0)
// A connection will be ready to evict soon.
return keepAliveDurationNs - longestIdleDurationNs;
else if (inUseConnectionCount > 0)
// All connections are in use. It'll be at least the keep alive duration 'til we run again.
return keepAliveDurationNs;
else
// No connections, idle or in use.
cleanupRunning = false;
return -1;
closeQuietly(longestIdleConnection.socket());
// Cleanup again immediately.
return 0;
/**
* Prunes any leaked allocations and then returns the number of remaining live allocations on
* @code connection. Allocations are leaked if the connection is tracking them but the
* application code has abandoned them. Leak detection is imprecise and relies on garbage
* collection.
*/
private int pruneAndGetAllocationCount(RealConnection connection, long now)
List<Reference<StreamAllocation>> references = connection.allocations;
for (int i = 0; i < references.size(); )
Reference<StreamAllocation> reference = references.get(i);
if (reference.get() != null)
i++;
continue;
// We've discovered a leaked allocation. This is an application bug.
StreamAllocation.StreamAllocationReference streamAllocRef =
(StreamAllocation.StreamAllocationReference) reference;
String message = "A connection to " + connection.route().address().url()
+ " was leaked. Did you forget to close a response body?";
Platform.get().logCloseableLeak(message, streamAllocRef.callStackTrace);
references.remove(i);
connection.noNewStreams = true;
// If this was the last allocation, the connection is eligible for immediate eviction.
if (references.isEmpty())
connection.idleAtNanos = now - keepAliveDurationNs;
return 0;
return references.size();
- 核心参数:
executor线程池、Deque双向队列维护RealConnect。也就是Socket的包装、RounteDatabase记录连接失败时的的路线名单
- 构造方法中的参数:
最大连接数默认为5个、保活时间为5分钟
- 判断当前的连接是否可以使用:流是否已经被关闭,并且已经被限制创建新的流;
- 如果当前的连接无法使用,就从连接池中获取一个连接;
- 连接池中也没有发现可用的连接,创建一个新的连接,并进行握手,然后将其放到连接池中。
总结
okhttp的核心类有哪些?
Dispatch
- Dispatch通过维护一个线程池,来维护、管理、执行okhttp的请求。整体可以看成是生成者与消费者模型
- Dispatch维护着三个队列分别是同步请求队列
runningSyncCalls、异步请求队列runningAsyn,异步缓存队列readyAsynCalls和一个线程池executorService
2.Intercept
- 拦截器是okhttp一种强大的机制,它可以实现网络监听、请求、以及响应重写、请求失败重试等功能。比如开发过程中我们打印log、添加公共请求头都是用拦截器做的
- 不算自定义的拦截器一共有5个,分别执行的顺序是
1. 重连重定向拦截器
2. 桥接拦截器(封装请求头,让socket支持http)
3. 缓存拦截器(判断有没有缓存,有缓存可以设置不往下走)
4. 连接拦截器(判断没有缓存就要连接服务器)
5. 网络拦截器(真正发起请求)
okhttp对于网络请求做了哪些优化,如何实现的?
- 通过连接池来减少求延时(有5分钟保活的长连接)
- 缓存响应减少重复的网络请求
okhttp架构中用到了哪些设计模式?
建造者模式、工厂模式、单例模式、责任链模式 前面三个基本上所有框架或多或少都有 真正比较有特点的是拦截器里面的责任链模式
-
责任链模式的定义:使多个对象都有机会处理请求,从而避免请求的发送者和接受者之间的耦合关系, 将这个对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理他为止。
-
责任链模式应用场景:
1、对多个对象都可以处理同一请求,但具体由哪一个处理则在运行时决定。
2、在请求处理者不明确的情况下向多个对象中的一个提交一个请求
3、需要动态指定一组对象处理请求时
上述中讲解的是有关OkHttp面试相关内容,其实这也只是面试中可能会问到的其中一个方向,往往在面试中面试官不会问你一个问题,更何况有二面、三面等等,而我们能做的就是全方面的复习,于是我这整理份《Android 面试题锦大全》,如下图所示:
以上是关于面试官:简单说下 okHttp原理分析~的主要内容,如果未能解决你的问题,请参考以下文章