sharding-jdbc结合mybatis实现分库分表功能
Posted 等待九月
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sharding-jdbc结合mybatis实现分库分表功能相关的知识,希望对你有一定的参考价值。
最近忙于项目已经好久几天没写博客了,前2篇文章我给大家介绍了搭建基础springMvc+mybatis的maven工程,这个简单框架已经可以对付一般的小型项目。但是我们实际项目中会碰到很多复杂的场景,比如数据量很大的情况下如何保证性能。今天我就给大家介绍数据库分库分表的优化,本文介绍mybatis结合当当网的sharding-jdbc分库分表技术(原理这里不做介绍)
首先在pom文件中引入需要的依赖
<dependency> <groupId>com.dangdang</groupId> <artifactId>sharding-jdbc-core</artifactId> <version>1.4.2</version> </dependency> <dependency> <groupId>com.dangdang</groupId> <artifactId>sharding-jdbc-config-spring</artifactId> <version>1.4.0</version> </dependency>
二、新建一个sharding-jdbc.xml文件,实现分库分表的配置
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx" xmlns:rdb="http://www.dangdang.com/schema/ddframe/rdb" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.dangdang.com/schema/ddframe/rdb http://www.dangdang.com/schema/ddframe/rdb/rdb.xsd"> <rdb:strategy id="tableShardingStrategy" sharding-columns="user_id" algorithm-class="com.meiren.member.common.sharding.MemberSingleKeyTableShardingAlgorithm"/> <rdb:data-source id="shardingDataSource"> <rdb:sharding-rule data-sources="dataSource"> <rdb:table-rules> <rdb:table-rule logic-table="member_index" actual-tables="member_index_tbl_${[0,1,2,3,4,5,6,7,8,9]}${0..9}" table-strategy="tableShardingStrategy"/> <rdb:table-rule logic-table="member_details" actual-tables="member_details_tbl_${[0,1,2,3,4,5,6,7,8,9]}${0..9}" table-strategy="tableShardingStrategy"/> </rdb:table-rules> </rdb:sharding-rule> </rdb:data-source> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="shardingDataSource" /> </bean> </beans>
这里我简单介绍下一些属性的含义,
<rdb:strategy id="tableShardingStrategy" sharding-columns="user_id" algorithm-class="com.meiren.member.common.sharding.MemberSingleKeyTableShardingAlgorithm"/> 配置分表规则器 sharding-columns:分表规 则
依赖的名(根据user_id取模分表),algorithm-class:分表规则的实现类
<rdb:sharding-rule data-sources="dataSource"> 这里填写关联数据源(多个数据源用逗号隔开),
<rdb:table-rule logic-table="member_index" actual-tables="member_index_tbl_${[0,1,2,3,4,5,6,7,8,9]}${0..9}" table-strategy="tableShardingStrategy"/> logic-table:逻辑表名(mybatis中代替的表名)actual-tables:
数据库实际的表名,这里支持inline表达式,比如:member_index_tbl_${0..2}会解析成member_index_tbl_0,member_index_tbl_1,member_index_tbl_2;member_index_tbl_${[a,b,c]}会被解析成
member_index_tbl_a,member_index_tbl_b和member_index_tbl_c,两种表达式一起使用的时候,会采取笛卡尔积的方式:member_index_tbl_${[a,b]}${0..2}解析为member_index_tbl_a0,member_index_tbl_a1 member_index_tbl_a2,member_index_tbl_b0,member_index_tbl_b1,member_index_tbl_b2;table-strategy:前面定义的分表规则器;
三、配置好改文件后,需要修改之前我们的spring-dataSource的几个地方,把sqlSessionFactory和transactionManager原来关联的dataSource统一修改为shardingDataSource(这一步作用就是把数据源全部托管给sharding去管理)
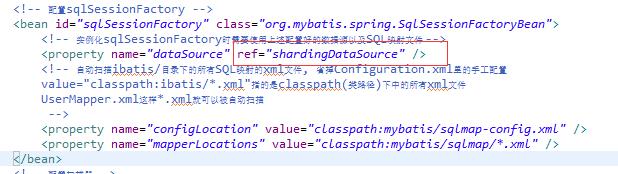
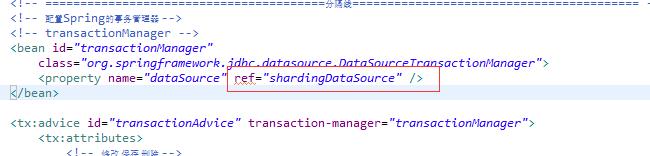
四、实现分表(分库)逻辑,我们的分表逻辑类需要实现SingleKeyTableShardingAlgorithm接口的三个方法doBetweenSharding、doEqualSharding、doInSharding
/** * 分表逻辑 * @author zhangwentao * */ public class MemberSingleKeyTableShardingAlgorithm implements SingleKeyTableShardingAlgorithm<Long> { /** * sql between 规则 */ public Collection<String> doBetweenSharding(Collection<String> tableNames, ShardingValue<Long> shardingValue) { Collection<String> result = new LinkedHashSet<String>(tableNames.size()); Range<Long> range = (Range<Long>) shardingValue.getValueRange(); for (long i = range.lowerEndpoint(); i <= range.upperEndpoint(); i++) { Long modValue = i % 100; String modStr = modValue < 10 ? "0" + modValue : modValue.toString(); for (String each : tableNames) { if (each.endsWith(modStr)) { result.add(each); } } } return result; } /** * sql == 规则 */ public String doEqualSharding(Collection<String> tableNames, ShardingValue<Long> shardingValue) { Long modValue = shardingValue.getValue() % 100; String modStr = modValue < 10 ? "0" + modValue : modValue.toString(); for (String each : tableNames) { if (each.endsWith(modStr)) { return each; } } throw new IllegalArgumentException(); } /** * sql in 规则 */ public Collection<String> doInSharding(Collection<String> tableNames, ShardingValue<Long> shardingValue) { Collection<String> result = new LinkedHashSet<String>(tableNames.size()); for (long value : shardingValue.getValues()) { Long modValue = value % 100; String modStr = modValue < 10 ? "0" + modValue : modValue.toString(); for (String tableName : tableNames) { if (tableName.endsWith(modStr)) { result.add(tableName); } } } return result; } }
五、以上四步,我们就完成了sharding-jdbc的搭建,我们可以写一个测试demo来检查我们的成果
<select id="getDetailsById" resultType="com.meiren.member.dataobject.MemberDetailsDO" parameterType="java.lang.Long"> select user_id userId ,qq,email from member_details where user_id =#{userId} limit 1 </select>
private static final String SERVICE_PROVIDER_XML = "/spring/member-service.xml";
private static final String BEAN_NAME = "idcacheService";
private ClassPathXmlApplicationContext context = null;
IdcacheServiceImpl bean = null;
IdcacheDao idcacheDao;
@Before
public void before() {
context= new ClassPathXmlApplicationContext(
new String[] {SERVICE_PROVIDER_XML});
idcacheDao=context.getBean("IdcacheDao", IdcacheDao.class);
}
@Test
public void getAllCreditActionTest() {
// int id = bean.insertIdcache();
Long s=100l;
MemberDetailsDO memberDetailsDO=idcacheDao.getDetailsById(s);
System.out.println("QQ---------------------"+memberDetailsDO.getQq());
}
打印sql语句,输出结果:QQ-------------------------------------100,证明成功!

注意点:这次搭建过程中,我有碰到一个小坑,就是执行的时候会报错:,官方文档是有解决方案:引入 <context:property-placeholder location="classpath:/member_service.properties" ignore-unresolvable="true" /> ,引入这行代码的时候,·必须要要把这边管理配配置文件的bean删除,换句话说,即Spring容器仅允许最多定义一个PropertyPlaceholderConfigurer(或<context:property-placeholder/>),其余的会被Spring忽略掉(当时搞了半天啊)
小结:这次给大家分享了sharding-jdbc的配置是为了解决大数据量进行分库分表的架构,下一张,我将介绍拆分业务所需的duboo+zookeeper的配置(分布式),欢迎关注!
以上是关于sharding-jdbc结合mybatis实现分库分表功能的主要内容,如果未能解决你的问题,请参考以下文章
mybatis-mapper 示例 sharding-jdbc
mybatis-mapper 示例 sharding-jdbc
sharding-jdbc+mybatis-plus 快速实现分库分表
springboot结合Mybatis和mybatis-plus实现分页查询的四种使用方式