Hadoop集群搭建详细步骤
Posted 雷神乐乐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop集群搭建详细步骤相关的知识,希望对你有一定的参考价值。
目录
5. 配置普通用户具有root权限,方便后期加sudo执行root权限的命令
2.xftp上传JDK8压缩包至/opt/software目录下
1.xftp上传Hadoop压缩包至/opt/software目录下
1.在/opt/module/hadoop-3.1.3目录下新建wcinput文件夹
2.wcinput文件夹下新建word.txt文件并输入内容
8.hadoop102尝试免密登录102、103、104三台机器
1.进入/opt/module/hadoop-3.1.3/etc/hadoop/目录下
一、模板虚拟机环境准备
1.新建一台虚拟机hadoop100,并且配置好网络
虚拟机参数参考:
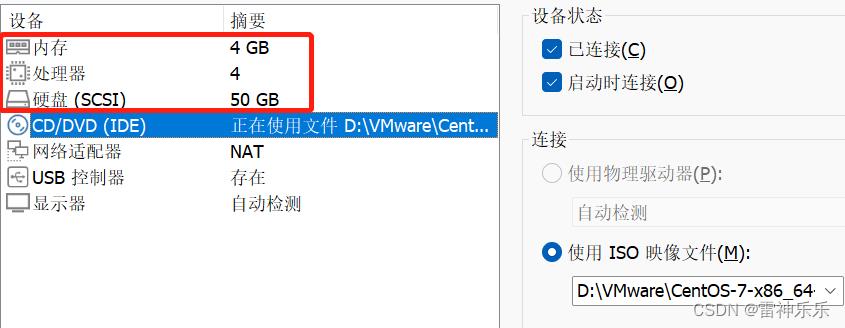
新建虚拟机参考博文《CentOS7中新建虚拟机详细步骤》
注意:1.选择桌面版安装
2.设置普通用户
虚拟机网络配置参考博文《Linux网关设置》
3.安装 epel-release
[root@hadoop100 ~]# yum install -y epel-release4.其他工具
如果你是最小化安装要执行以下命令,桌面版不需要
[root@hadoop100 ~]# yum install -y net-tools
[root@hadoop100 ~]# yum install -y vim5. 配置普通用户具有root权限,方便后期加sudo执行root权限的命令
[root@hadoop100 ~]# vim /etc/sudoers在%wheel下面添加命令如下图:
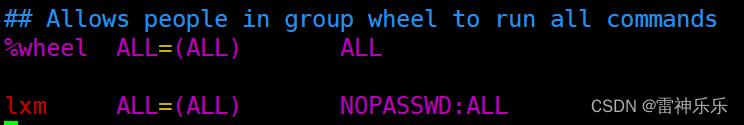
6.删除/opt/目录下的所有文件
[root@hadoop100 ~]# rm -rf /opt/*7.在/opt/目录下创建文件夹,并修改所属主和所属组
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software
[root@hadoop100 ~]# chown atguigu:atguigu /opt/module
[root@hadoop100 ~]# chown atguigu:atguigu /opt/software
8. 卸载虚拟机自带的JDK
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
# 检查是否删除干净
[root@hadoop100 ~]# rpm -qa | grep -i javarpm -qa :查询所安装的所有 rpm 软件包 grep -i :忽略大小写 xargs -n1 :表示每次只传递一个参数 rpm -e –nodeps :强制卸载软件
9.重启虚拟机
[root@hadoop100 ~]# reboot二、克隆虚拟机
1.关闭模板虚拟机
2.克隆三台虚拟机
模板虚拟机右键→管理→克隆
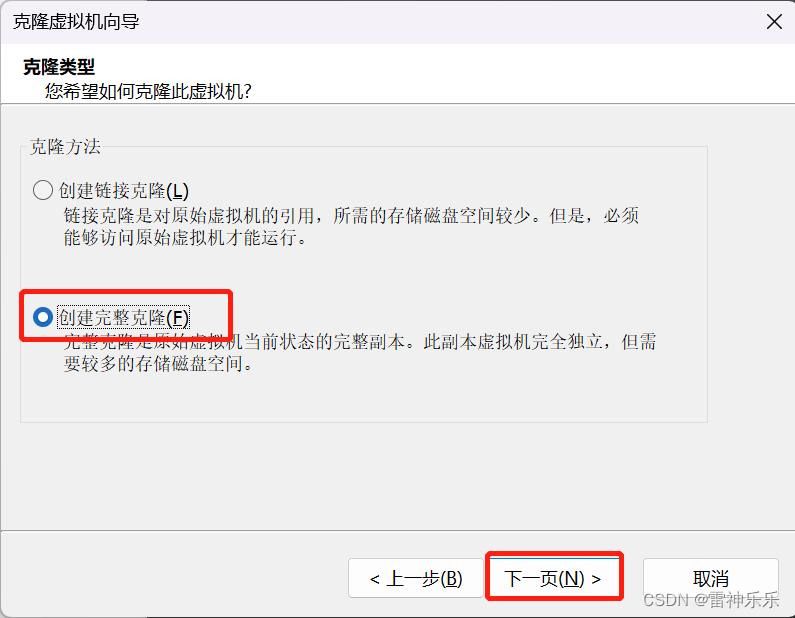
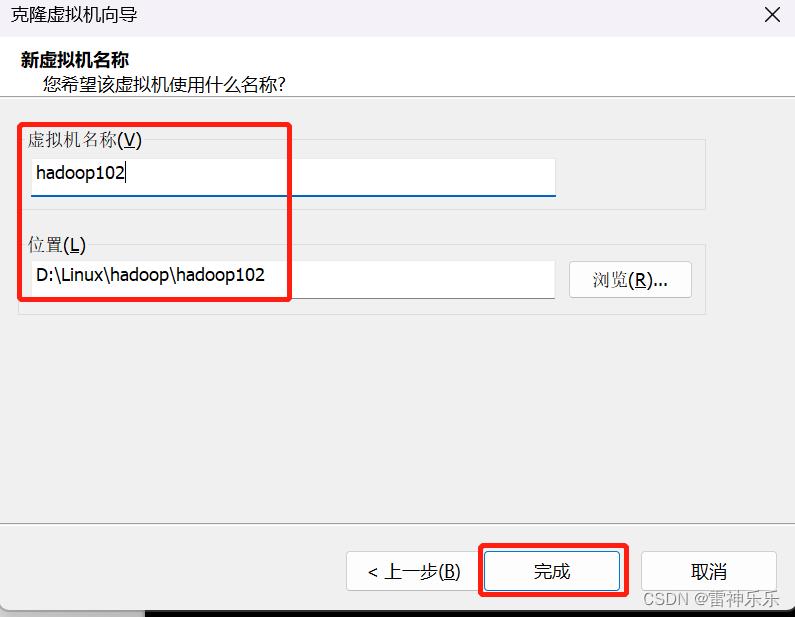

再克隆两台虚拟机hadoop103和hadoop104
3.修改三台克隆机的ip和主机名后重启
(1)开启这四台虚拟机
(2)修改ip地址
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33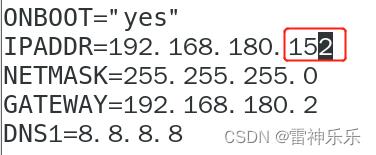
(3)修改主机名
[root@hadoop100 ~]# vim /etc/hostname
(4)重启hadoop102
(5)关闭hadoop102的防火墙
[root@hadoop102 ~]# systemctl stop firewalld
[root@hadoop102 ~]# systemctl disable firewalld.service
[root@hadoop102 ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
(6)开启network,测试网络连接
[root@hadoop102 network-scripts]# systemctl stop NetworkManager
[root@hadoop102 network-scripts]# systemctl disable NetworkManager
Removed symlink /etc/systemd/system/multi-user.target.wants/NetworkManager.service.
Removed symlink /etc/systemd/system/dbus-org.freedesktop.NetworkManager.service.
Removed symlink /etc/systemd/system/dbus-org.freedesktop.nm-dispatcher.service.
[root@hadoop102 network-scripts]# systemctl restart network
[root@hadoop102 network-scripts]# ping www.baidu.com
[root@hadoop102 network-scripts]# hostname
hadoop102
[root@hadoop102 network-scripts]# ifconfig
[root@hadoop102 network-scripts]# systemctl stop NetworkManager
[root@hadoop102 network-scripts]# systemctl disable NetworkManager
Removed symlink /etc/systemd/system/multi-user.target.wants/NetworkManager.service.
Removed symlink /etc/systemd/system/dbus-org.freedesktop.NetworkManager.service.
Removed symlink /etc/systemd/system/dbus-org.freedesktop.nm-dispatcher.service.
[root@hadoop102 network-scripts]# systemctl restart network
[root@hadoop102 network-scripts]# ping www.baidu.com
PING www.a.shifen.com (180.101.50.242) 56(84) bytes of data.
64 bytes from 180.101.50.242 (180.101.50.242): icmp_seq=1 ttl=128 time=2.99 ms
64 bytes from 180.101.50.242 (180.101.50.242): icmp_seq=2 ttl=128 time=3.26 ms
^C
--- www.a.shifen.com ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 2.999/3.134/3.269/0.135 ms
[root@hadoop102 network-scripts]# hostname
hadoop102
[root@hadoop102 network-scripts]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.180.152 netmask 255.255.255.0 broadcast 192.168.180.255
inet6 fe80::20c:29ff:fec5:2a4e prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:c5:2a:4e txqueuelen 1000 (Ethernet)
RX packets 5 bytes 524 (524.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 30 bytes 4235 (4.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
virbr0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255
ether 52:54:00:55:4e:cf txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
(7)另外两台虚拟机hadoop103和hadoop104重复(1)~(6)操作
(8)《关于Job for network.service failed because the control process exited with error code.》
4.Windows主机host文件下配置集群的ip地址映射
进入 C:\\Windows\\System32\\drivers\\etc 路径,添加下面的ip映射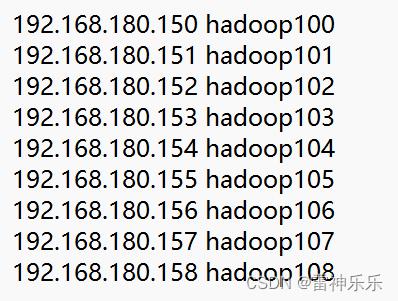
三、hadoop102安装JDK
1.检查hadoop102是否有JDK
注意:安装 JDK 前,一定确保提前删除了虚拟机自带的 JDK 。参考一、8
[lxm@hadoop102 ~]$ rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
rpm:未给出要擦除的软件包2.xftp上传JDK8压缩包至/opt/software目录下
3.解压JDK至/opt/software目录下
[lxm@hadoop102 module]$ tar -zxvf /opt/software/jdk-8u321-linux-x64.tar.gz -C /opt/module/
[lxm@hadoop102 module]$ ll
总用量 0
drwxr-xr-x. 8 lxm lxm 273 12月 16 2021 jdk1.8.0_321
4.配置JDK环境变量
[lxm@hadoop102 module]$ sudo vim /etc/profile.d/my_env.sh
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_321
export PATH=$PATH:$JAVA_HOME/bin
5.重启环境变量并测试JDK是否安装成功
[lxm@hadoop102 module]$ source /etc/profile
[lxm@hadoop102 module]$ javac
[lxm@hadoop102 module]$ java -version
java version "1.8.0_321"
Java(TM) SE Runtime Environment (build 1.8.0_321-b07)
Java HotSpot(TM) 64-Bit Server VM (build 25.321-b07, mixed mode)四、hadoop102安装Hadoop
1.xftp上传Hadoop压缩包至/opt/software目录下
2.解压Hadoop压缩包至/opt/module
[lxm@hadoop102 module]$ sudo vim /etc/profile.d/my_env.sh
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
3.重启环境变量并检查Hadoop是否配置成功
[lxm@hadoop102 module]$ source /etc/profile
[lxm@hadoop102 module]$ hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar五、测试Hadoop官方WordCount
1.在/opt/module/hadoop-3.1.3目录下新建wcinput文件夹
[lxm@hadoop102 hadoop-3.1.3]$ mkdir wcinput
2.wcinput文件夹下新建word.txt文件并输入内容
[lxm@hadoop102 hadoop-3.1.3]$ cd ./wcinput/
[lxm@hadoop102 wcinput]$ vim word.txt
hello world
hello java
hello hadoop
3.执行wordcount命令
[lxm@hadoop102 wcinput]$ hadoop jar /opt/module/hadoop-3.1.3/share/haadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /opt/module/hadoop-3.1.3/wcinput/ /opt/module/hadoop-3.1.3/wcoutput/4.检查结果
[lxm@hadoop102 hadoop-3.1.3]$ cat ./wcoutput/part-r-00000
hadoop 1
hello 3
java 1
world 1注意:如果第二次提交wordcount命令就要删除/opt/module/hadoop-3.1.3目录下的wcoutput文件。
六、SSH免密登录
免密登录就是从一台虚拟机登录另一台虚拟机不需要输入密码
1.在hadoop102上登录hadoop103
[lxm@hadoop102 ~]$ ssh hadoop103
2.输入yes
Are you sure you want to continue connecting (yes/no)? yes
3.输入hadoop103密码
lxm@hadoop103's password: 4.退出登录
[lxm@hadoop103 ~]# exit
登出
Connection to hadoop103 closed.
[lxm@hadoop102 ~]5.查看/home目录下生成的ssh文件
[lxm@hadoop102 ~]$ ll -al
[lxm@hadoop102 ~]$ cd .ssh
6.生成私钥和公钥
[lxm@hadoop102 .ssh]$ ssh-keygen -t rsa回车三次
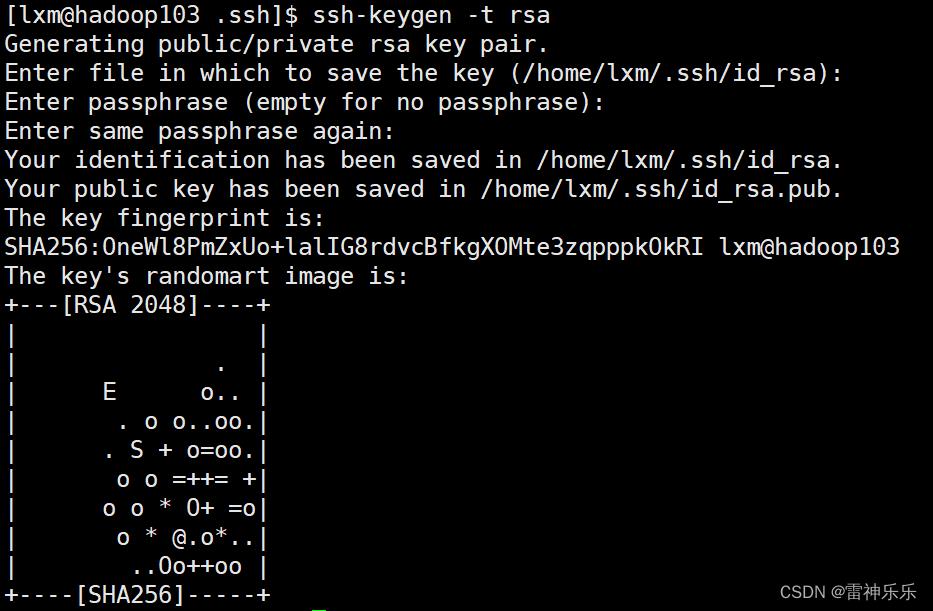
[lxm@hadoop102 .ssh]$ ll
-rw-------. 1 lxm lxm 1675 2月 12 11:10 id_rsa
-rw-r--r--. 1 lxm lxm 395 2月 12 11:10 id_rsa.pub
-rw-r--r--. 1 lxm lxm 561 2月 12 11:11 known_hosts
7.将公钥拷贝到要免密登录的目标机器上
[lxm@hadoop102 .ssh]$ ssh-copy-id hadoop102
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/lxm/.ssh/id_rsa.pub"
The authenticity of host 'hadoop102 (192.168.180.152)' can't be established.
ECDSA key fingerprint is SHA256:GFkoioPRq02rdq9bMm4L+OWi08ZceOxyBAaKGj4pObQ.
ECDSA key fingerprint is MD5:8f:f8:55:6a:f6:ba:13:a4:81:3e:04:d2:3c:07:1c:a5.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
lxm@hadoop102's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop102'"
and check to make sure that only the key(s) you wanted were added.
[lxm@hadoop102 .ssh]$ ssh-copy-id hadoop103
[lxm@hadoop102 .ssh]$ ssh-copy-id hadoop1048.hadoop102尝试免密登录102、103、104三台机器
[lxm@hadoop102 .ssh]$ ssh hadoop102
Last login: Sun Feb 12 10:11:45 2023 from 192.168.180.1
[lxm@hadoop102 ~]$ exit
登出
Connection to hadoop102 closed.
[lxm@hadoop102 .ssh]$ ssh hadoop103
Last login: Sun Feb 12 11:10:15 2023 from 192.168.180.152
[lxm@hadoop103 ~]$ exit
登出
Connection to hadoop103 closed.
[lxm@hadoop102 .ssh]$ ssh hadoop104
Last login: Sun Feb 12 09:57:31 2023 from 192.168.180.1
[lxm@hadoop104 ~]$ exit
登出
Connection to hadoop104 closed.9.在hadoop103和hadoop104重复步骤6~8
七、配置集群
1.进入/opt/module/hadoop-3.1.3/etc/hadoop/目录下
[lxm@hadoop102 hadoop]$ pwd
/opt/module/hadoop-3.1.3/etc/hadoop在下面四个xml文件的<configuration></configuration>标签内插入以下内容,注意根据你的主机名更改对应的localhost
2.配置core-site.xml
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>3.配置hdfs-site.xml
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>4.配置mapred-site.xml
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>5.配置yarn-site.xml
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>八、xsync分发脚本
1.编写一个xsync脚本,期望脚本全局调用
脚本放在声明了全局环境变量的路径

2. 在根目录下创建bin文件夹
[lxm@hadoop102 ~]$ cd /home/lxm
[lxm@hadoop102 ~]$ mkdir bin
[lxm@hadoop102 ~]$ cd bin
[lxm@hadoop102 ~]$ vim xsync3.xsync脚本内容,注意主机名
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
4.赋予xsync脚本执行权限
[lxm@hadoop102 bin]$ chmod 777 xsync5.测试脚本
[lxm@hadoop102 ~]$ xsync /home/lxm/bin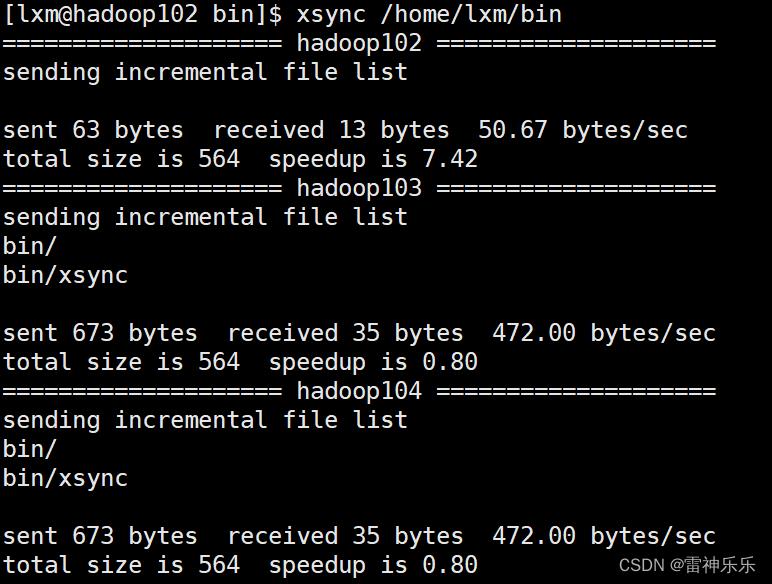
执行成功
6.将脚本复制到/bin 中,以便全局调用
[lxm@hadoop102 ~]$ sudo cp xsync /bin/7.分发/opt/module
[lxm@hadoop102 ~]$ xsync /opt/module/8.同步环境变量配置
[lxm@hadoop103 ~]$ source /etc/profile
[lxm@hadoop104 ~]$ source /etc/profile九、时间同步
参考博文《Linux中CentOS7时间与网络时间orWindows同步的方法》
十、配置workers
1.输入主机名
[lxm@hadoop102 ~]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
hadoop102
hadoop103
hadoop1042.分发workers
[lxm@hadoop102 ~]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/workers十一、启动集群
1.初次启动集群要进行初始化
[lxm@hadoop102 ~]$ hdfs namenode -format2.hadoop102开启dfs
[lxm@hadoop102 ~]$ start-dfs.sh3.hadoop103开启yarn
[lxm@hadoop103 ~]$ start-yarn.sh4.jps命令查看
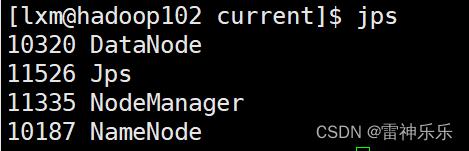
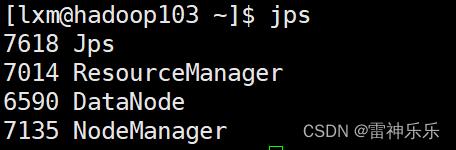
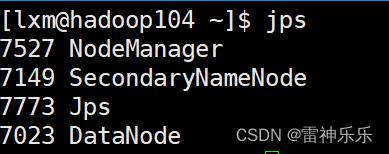
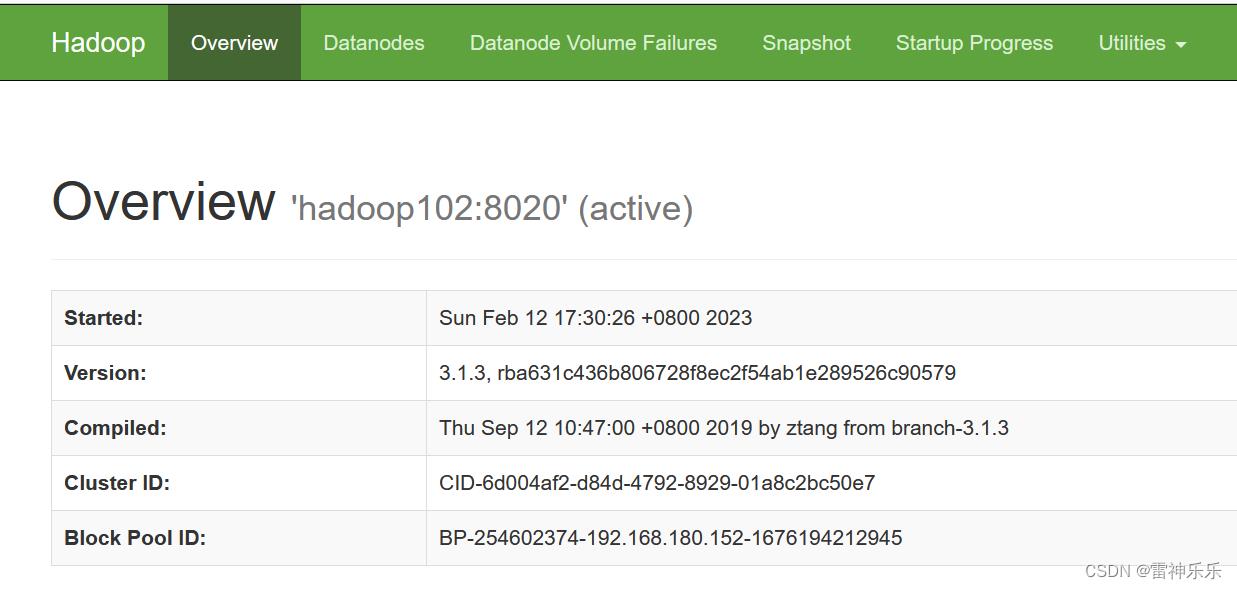
5.浏览器测试
http://hadoop102:9870
十二、配置历史服务器与日志聚集
为了查看程序的历史运行情况,需要配置一下历史服务器。1.配置mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>2.配置yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>3.分发
[lxm@hadoop102 ~]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/4.重启Hadoop集群
[lxm@hadoop102 ~]$ stop-dfs.sh
[lxm@hadoop103 ~]$ stop-yarn.sh
[lxm@hadoop102 ~]$ start-dfs.sh
[lxm@hadoop103 ~]$ start-yarn.sh5.hadoop102启动历史服务器
[lxm@hadoop102 hadoop]$ mapred --daemon start historyserver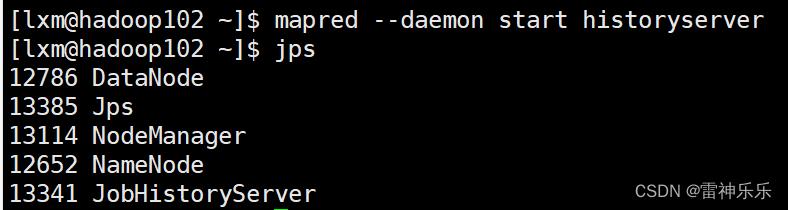
十三、执行wordcount
参考博文《Hadoop之——WordCount案例与执行本地jar包》
十四、Hadoop 集群启停脚本
1.myhadoop.sh脚本
[lxm@hadoop102 bin]$ vim myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start
historyserver"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop
historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
2.赋予权限
[lxm@hadoop102 bin]$ chmod +x myhadoop.sh3.分发脚本
[lxm@hadoop102 ~]$ sudo ./bin/xsync /home/lxm/bin/
十五、jspall脚本
1.jpsall脚本
[lxm@hadoop102 bin]$ vim jpsall
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done
2.赋予权限
[lxm@hadoop102 bin]$ chmod +x jpsall3.分发脚本
[lxm@hadoop102 ~]$ sudo ./bin/xsync /home/lxm/bin/
以上是关于Hadoop集群搭建详细步骤的主要内容,如果未能解决你的问题,请参考以下文章