java词频统计——改进后的单元测试
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java词频统计——改进后的单元测试相关的知识,希望对你有一定的参考价值。
测试项目
博客文章地址:[http://www.cnblogs.com/jx8zjs/p/5862269.html]
工程地址:https://coding.net/u/jx8zjs/p/wordCount/git
ssh://[email protected]:jx8zjs/wordCount.git
测试用例:
1.
1 My English is very very pool
2.地址 [http://www.gutenberg.org/files/2600/2600-0.txt]
待测单元1:统计输入文件的词频到目标文件
前四行代码为输入文件和输出文件地址,文件1是测试用例1,文件2是测试用例2.
1 String filename1 = "D://text/pool.txt"; 2 String filename2 = "D://text/2600-0.txt"; 3 String filenamedes1 = "D://pooltest.txt"; 4 String filenamedes2 = "D://2600-0test.txt"; 5 private static FileWordUtil fu = new FileWordUtil(); 6 7 public void testPrintSortedWordGroupCountToFileBufferedStringString() { 8 fu.printSortedWordGroupCountToFile(filename1, filenamedes1); 9 fu.printSortedWordGroupCountToFile(filename2, filenamedes2); 10 } 11 12 public void printSortedWordGroupCountToFile(String filename, String destinationFilename) { 13 List<String[]> result = getSortedWordGroupCount(filename); 14 if (result == null) { 15 System.out.println("no result"); 16 return; 17 } 18 try { 19 FileWriter fr = new FileWriter(destinationFilename); 20 for (String[] sa : result) { 21 fr.write(sa[1] + ": " + sa[0] + "\r\n"); 22 } 23 fr.close(); 24 } catch (IOException e) { 25 e.printStackTrace(); 26 return; 27 } 28 29 }
核心词频统计代码(2016.9.26优化版):
1 public Map<String, Integer> getWordGroupCountBuffered(String filename) { 2 try { 3 FileReader fr = new FileReader(filename); 4 BufferedReader br = new BufferedReader(fr); 5 StringBuffer content = new StringBuffer(""); 6 Map<String, Integer> result = new HashMap<String, Integer>(); 7 char[] ch = new char[128]; 8 int bs = 0; 9 int idx; 10 boolean added = false; 11 boolean split = false; 12 total = 0; 13 while ((bs = br.read(ch)) > 0) { 14 for (idx = 0; idx < bs; idx++) { // char 15 if (isCharacter(ch[idx]) == 1) { 16 if (split == false) { 17 content.append(ch[idx]); 18 added = false; 19 } else { 20 String key = content.toString().toLowerCase(); 21 split = false; 22 total++; 23 added = true; 24 content = new StringBuffer(""); 25 content.append(ch[idx]); 26 if (result.containsKey(key)) { 27 result.put(key, result.get(key) + 1); 28 continue; 29 } else { 30 result.put(key, 1); 31 continue; 32 } 33 } 34 } else if (isCharacter(ch[idx]) == 2) { // digital 35 if (added == true) { 36 continue; 37 } else { 38 content.append(ch[idx]); 39 } 40 } else { // not char or digital 41 split = true; 42 continue; 43 } 44 } 45 } 46 String key = content.toString().toLowerCase(); 47 if (result.containsKey(key)) { 48 result.put(key, result.get(key) + 1); 49 } else { 50 result.put(key, 1); 51 } 52 total++; 53 br.close(); 54 fr.close(); 55 return result; 56 } catch ( 57 58 FileNotFoundException e) { 59 System.out.println("failed to open file:" + filename); 60 e.printStackTrace(); 61 } catch (Exception e) { 62 System.out.println("some expection occured"); 63 e.printStackTrace(); 64 } 65 return null; 66 }
测试结果:
pooltest.txt
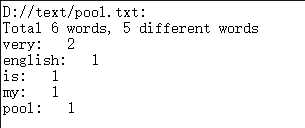
2600-0test.txt
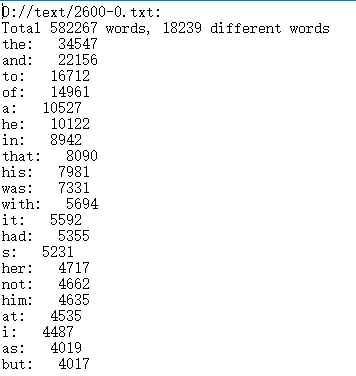
待测单元2:统计输入文件的词频到控制台或终端
测试用例1结果:

单元测试总结:
在单元测试的时候偶然间发现了在上文提到的连接中的分词核心函数在某些情况下回遗漏文章最后一个单词,经过反复改进和思考后重写了分析读出字符的逻辑,使测试结果也能满足于预期结果,更令我意外的是算法的效率也提升了近40%(原版本在本机的执行时间平均在490-550ms,新版本运行时间在276-343ms),原因也是引入了新的boolean变量帮助优化逻辑,也减少了一些判定条件。
工程地址:https://coding.net/u/jx8zjs/p/wordCount/git
ssh://[email protected]:jx8zjs/wordCount.git
以上是关于java词频统计——改进后的单元测试的主要内容,如果未能解决你的问题,请参考以下文章