python自动化与文档处理(word, excel, html)3个小程序
Posted 小哈里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python自动化与文档处理(word, excel, html)3个小程序相关的知识,希望对你有一定的参考价值。
文章目录
python自动化办公常用库
- pandas 数据处理
- os 文件处理
- bs4 爬虫
- office 文档处理
1、将word试卷转为excel表格导入考试宝
题目长这样:

代码:
import pandas as pd
import re
from docx import Document
from collections import OrderedDict
doc = Document("1.docx")
black_char = re.compile("[\\s\\u3000\\xa0]+")
chinese_nums_rule = re.compile("[一二三四]、(.+?)\\(")
title_rule = re.compile("\\d+.")
option_rule = re.compile("\\([ABCDEF]\\)")
option_rule_search = re.compile("\\([ABCDEF]\\)[^(]+")
# 保存最终的结构化数据
question_type2data = OrderedDict()
# 从word文档的“一、单项选择题”开始遍历数据
title2options = OrderedDict()
for paragraph in doc.paragraphs[1:]:
# 去除空白字符,将全角字符转半角字符,并给括号之间调整为中间一个空格
line = black_char.sub("", paragraph.text).replace(
"(", "(").replace(")", ")").replace(".", ".").replace("()", "( )")
# 对于空白行就直接跳过
if not line:
continue
if title_rule.match(line):
print("题目", line)
options = title2options.setdefault(line, [])
elif option_rule.match(line):
print("选项", option_rule_search.findall(line))
options.extend(option_rule_search.findall(line))
else:
chinese_nums_match = chinese_nums_rule.match(line)
if chinese_nums_match:
# print("题型", chinese_nums_match.group(1))
question_type = chinese_nums_match.group(1)
title2options = question_type2data.setdefault(
question_type, OrderedDict())
result = []
max_options_len = 0
for question_type, title2options in question_type2data.items():
for title, options in title2options.items():
result.append([question_type, title, *options])
options_len = len(options)
if options_len > max_options_len:
max_options_len = options_len
# print(result)
df = pd.DataFrame(result, columns=["题型", "题目"]+[f"选项i" for i in range(1, max_options_len+1)])
# 题型可以简化下,去掉选择两个字
df['题型'] = df['题型'].str.replace("选择", "")
df.to_excel("result.xlsx", index=False)
运行结果:

附:手动word复制粘贴到txt,替换规则
替换操作(全词匹配):
正确答案:^p
答案:
答案:C、
答案:C^p解析:

2、bs4处理下载的html文本
from bs4 import BeautifulSoup
import pandas as pd
html = open('activity_show.html',encoding='utf-8')
soup = BeautifulSoup(html,'html.parser')
# 获取所有题目
lst = soup.find_all('div',
class_= ["testpaper-question", "testpaper-question-choice", "js-testpaper-question"]
)
all = []
for timu in lst :
tt = []
name = timu.find_all('div', class_ = ["testpaper-question-stem","test001"])
name = name[0].find('p').contents[0]
tt.append(name)
# print(name)
choice = timu.find_all('ul', class_ = ["testpaper-question-choices","js-testpaper-question-list"])[0]
choice = choice.find_all('li')
choice2 = []
for ch in choice:
tt.append(ch.find('p').contents[0])
choice2.append(ch.contents[0])
# print(choice2)
ans = timu.find('strong',class_=["color-success"])
ans = ans.contents[0]
tt.append(ans)
# print(ans)
all.append(tt)
print(tt)
# print(all)
df = pd.DataFrame(all, columns=['timu', 'A', 'B', 'C', 'D', 'ans'])
print(df.head())
df.to_excel('benci.xlsx',index=False)
# -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
# conda activate pytorch
# python html_deal.py
结果如下:
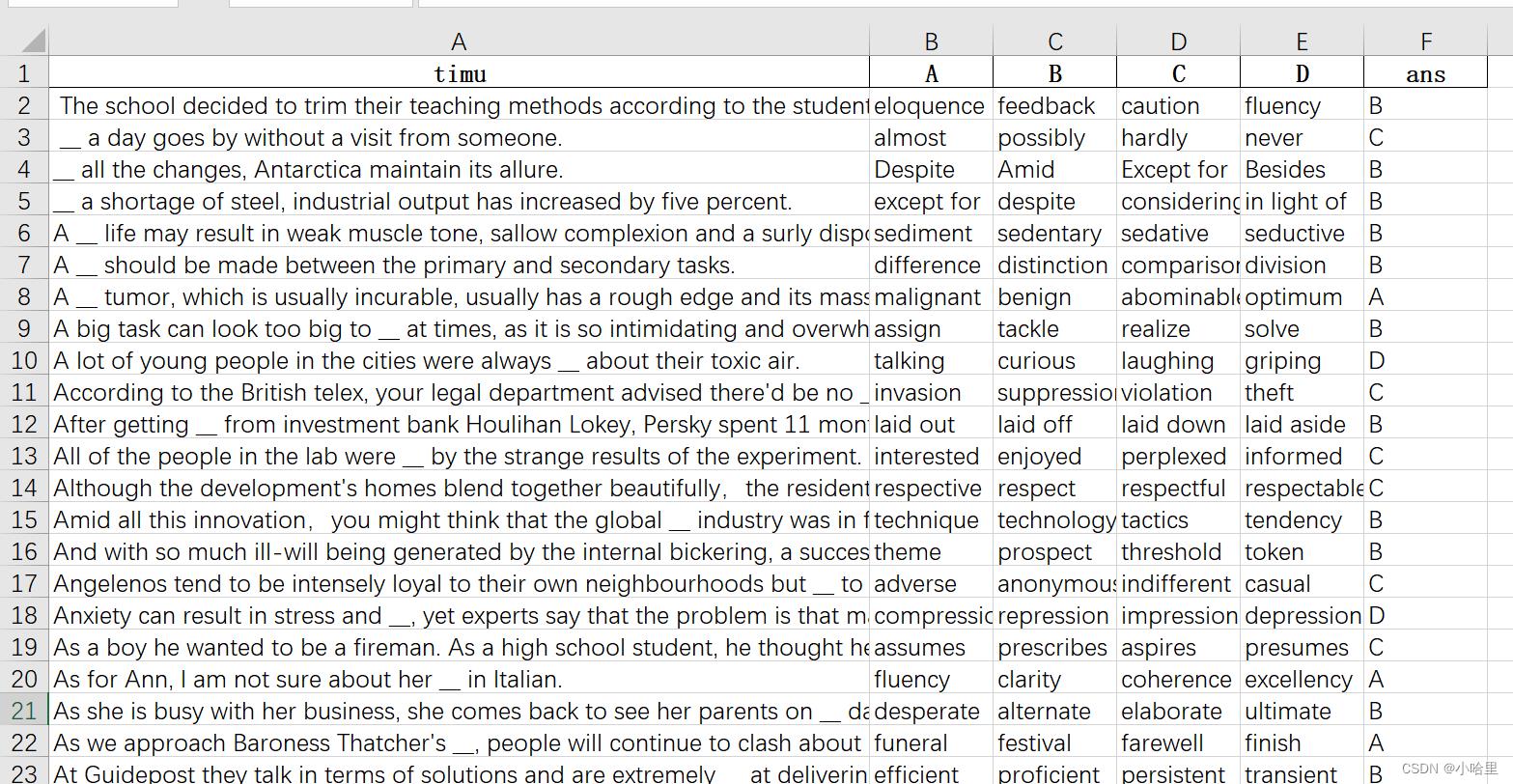
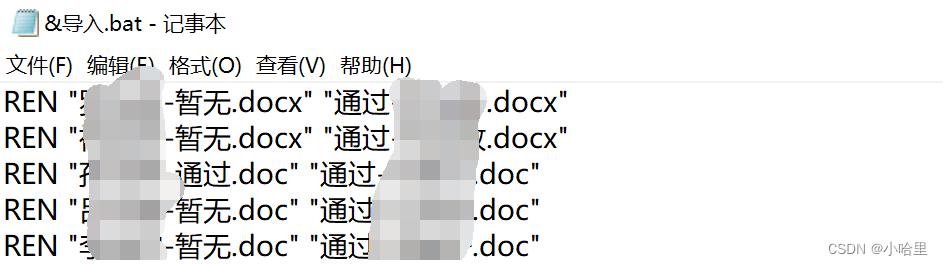
3、将大量word表格导出为excel
1、先新建bat得到当前目录所有文件名
dir /b > rename.txt
2、excel处理后得到重命名.bat,运行即可重命名
3、将word表格导出到excel
import docx
import pandas as pd
import os
# from win32com import client as wc
# 安装 python-docx, docx
# conda activate pytorch
# cd C:/XXX/例子/测试/
# python To_excel.py
def Todocx():
# word = wc.Dispatch('Word.Application')
path_list = os.listdir(path)
doc_list = [os.path.join(path,str(i)) for i in path_list if str(i).endswith('doc')]
word = wc.Dispatch('Word.Application')
print(doc_list)
for path in doc_list:
print(path)
save_path = str(path).replace('doc','docx')
doc = word.Documents.Open(path)
doc.SaveAs(save_path,12, False, "", True, "", False, False, False, False)
doc.Close()
print(' Save sucessfully '.format(save_path))
word.Quit()
word_paths = "C:/XXX/例子/测试/"
# convertdoc_docx(word_paths)
wordlist_path = [os.path.join(word_paths,i) for i in os.listdir(word_paths) if str(i).endswith('.docx')]
def GetData_frompath(doc_path):
'''
Generate Data form doc_path of word path
:param doc_path:
:return: col_keys 列键;
col_values 列名;
'''
document = docx.Document(doc_path)
col_keys = [] # 获取列名
col_values = [] # 获取列值
index_num = 0
# 添加一个去重机制
fore_str = ''
for table in document.tables:
for row_index,row in enumerate(table.rows):
for col_index,cell in enumerate(row.cells):
if fore_str != cell.text:
if index_num % 2==0:
col_keys.append(cell.text)
else:
col_values.append(cell.text)
fore_str = cell.text
index_num +=1
# col_values[7] = '\\t'+col_values[7]
# col_values[8] = '\\t'+col_values[8]
print(f'col keys is col_keys')
print(f'col values is col_values')
return col_keys,col_values
pd_data = []
for index,single_path in enumerate(wordlist_path):
try:
col_names,col_values = GetData_frompath(single_path)
except:
pass
if index == 0:
pd_data.append(col_names)
pd_data.append(col_values)
else:
pd_data.append(col_values)
df = pd.DataFrame(pd_data)
df.to_csv(word_paths+'/result.csv', encoding='utf_8_sig',index=False)
以上是关于python自动化与文档处理(word, excel, html)3个小程序的主要内容,如果未能解决你的问题,请参考以下文章