C/C++:预处理(下)
Posted 摆烂小青菜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C/C++:预处理(下)相关的知识,希望对你有一定的参考价值。
目录
一.回顾程序的编译链接过程
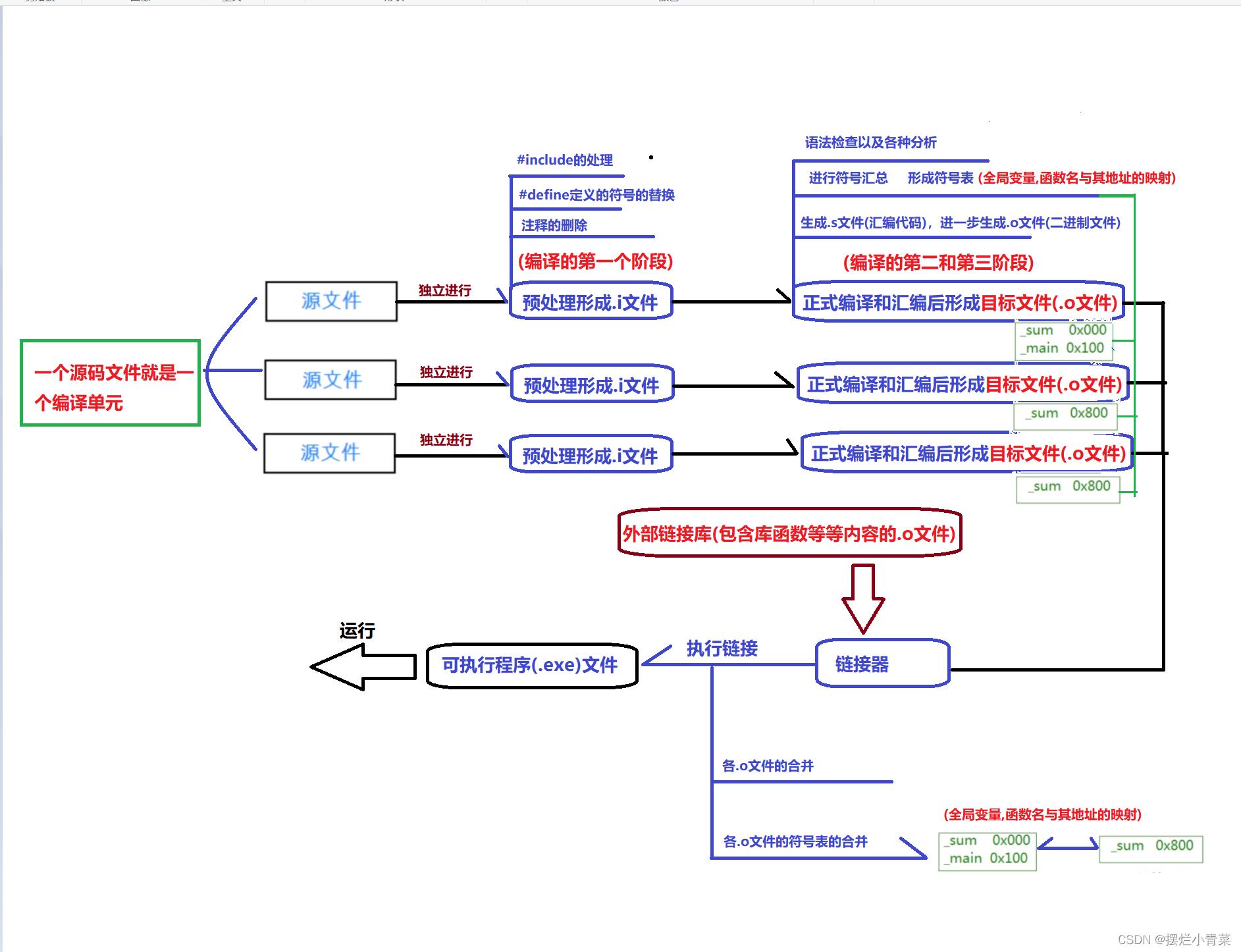
二. 预处理之预定义#define
1.#define定义的标识符
#define定义的标识符在源码文件的预处理阶段会以文本替换的方式被替换为定义的内容
比如:
#define MAX 1000 //MAX 是被宏定义的标识符 //MAX空格后的所有内容是其定义的内容注意:
- 标识符是以空格为结尾的(也就是说#define定义的标识符中不含有空格)
- #define语句最后不要加上; 不然分号也会被替换到代码段中造成一些bug
2.#define定义的宏
#define定义的标识符可以带参数(和函数有点类似),#define定义的带参标识符称为宏
比如:
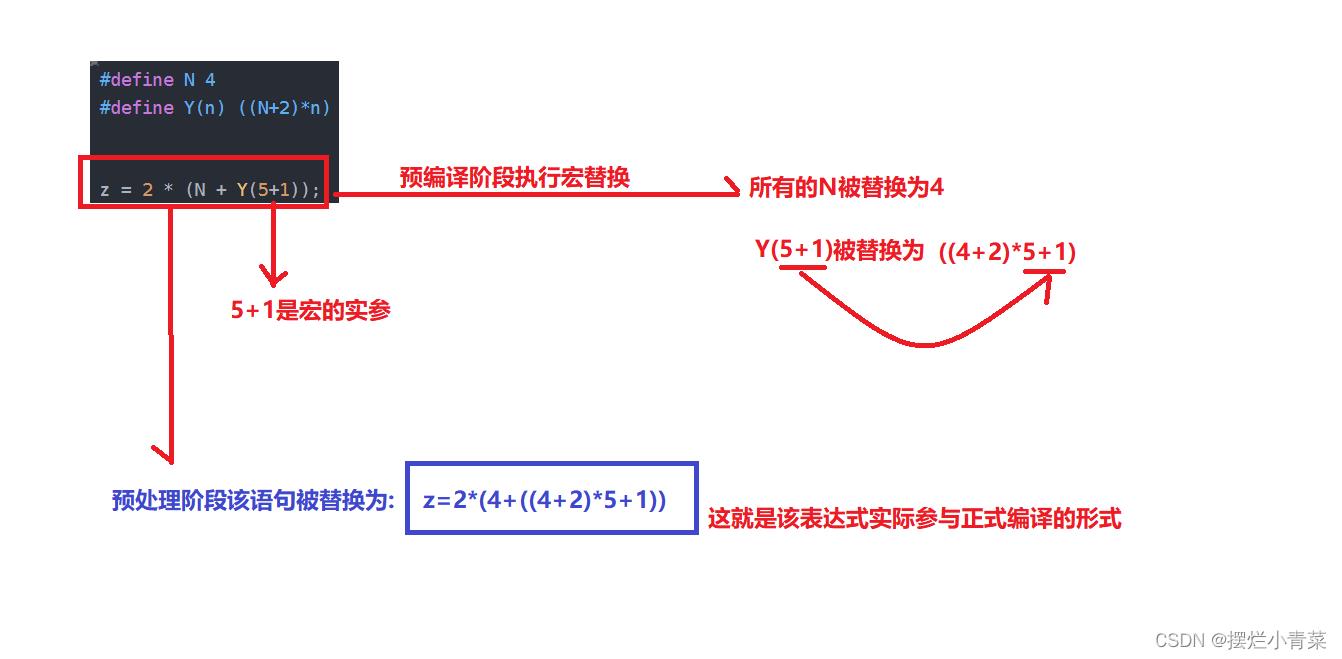
#define N 4 #define Y(n) ((N+2)*n) z = 2 * (N + Y(5+1)); //z最后的结果是多少?
- Y(n)就是一个宏,Y是宏名,n是宏的参数
- z的结果分析:
因此z最后算出来的结果为70,可见该式子中5+1并没有优先被计算,所以用于对数值表达式进行求值的宏定义一定要注意将宏参数和宏体都用括号括起来避免因为运算符优先级问题而导致运算结果不符合预期,因此宏Y(n)更严谨的写法应该是:
#define Y(n) (((N)+2)*(n))
3.带副作用的表达式作为宏实参
#define MAX(a, b) ( (a) > (b) ? (a) : (b) ) ... x = 5; y = 8; z = MAX(x++, y++); printf("x=%d y=%d z=%d\\n", x, y, z);//输出的结果是什么?
因此最终:z=9,x=6,y=10.(x自增了两次,y自增了一次)
- 可见带副作用的表达式(副作用就是表达式求值的时候相关变量的值被改变)作为宏实参是十分危险的

4.两个经典的宏
- 百度工程师笔试题:写一个宏,计算结构体中某变量相对于首地址的偏移(
offsetof宏的实现)(宏的实参可以是变量类型名)#define OFFSETOF(structname,numbername) (size_t)&(((structname *)0)->numbername)
#define OFFSETOF(structname,numbername) (size_t)&(((structname *)0)->numbername) //宏的测试 typedef struct Node int i; char c; short d; Node; int main () printf("%u\\n",OFFSETOF(Node,i)); printf("%u\\n",OFFSETOF(Node,c)); printf("%u\\n",OFFSETOF(Node,d)); return 0;
这是类型名作为宏参数的一个典型应用。
关于结构体成员偏移量参见结构体内存对齐: http://t.csdn.cn/Vd6ix


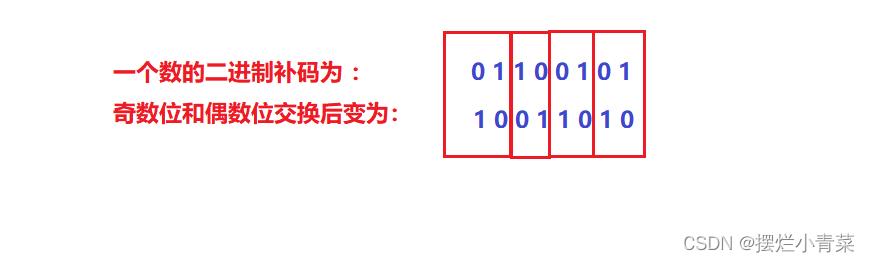
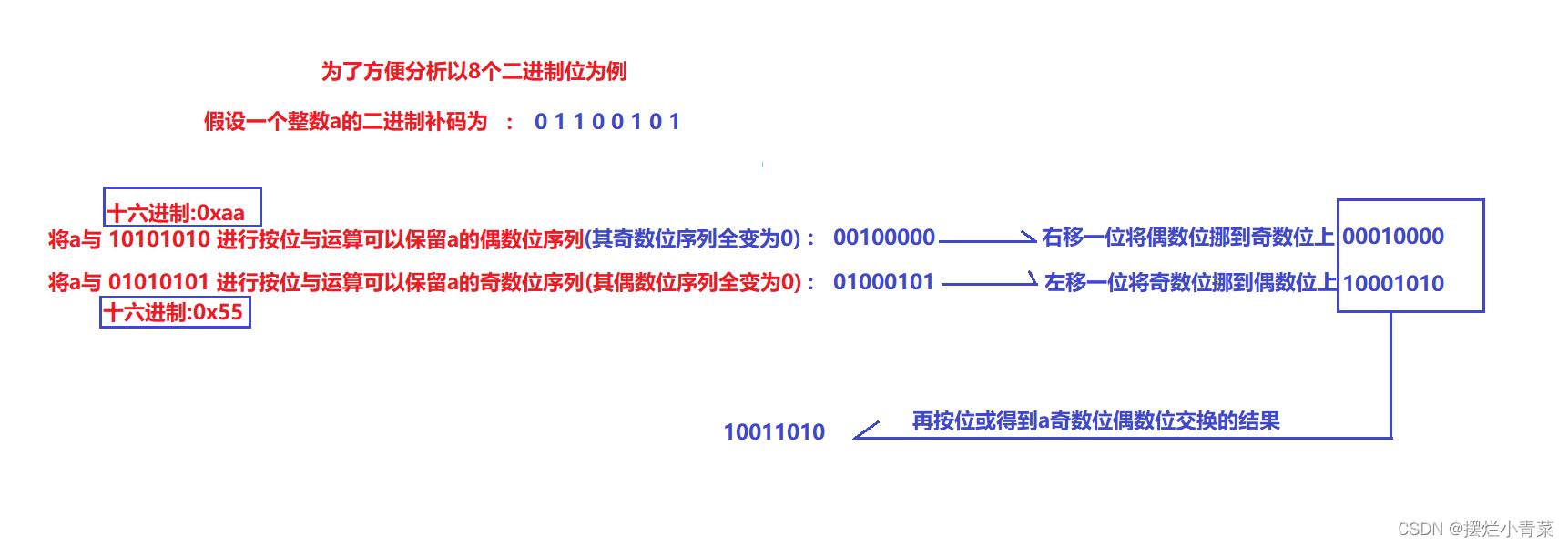
- 一个经典算法宏:写一个宏,可以将一个正整数(32比特位)的二进制补码的奇数位和偶数位交换
比如:
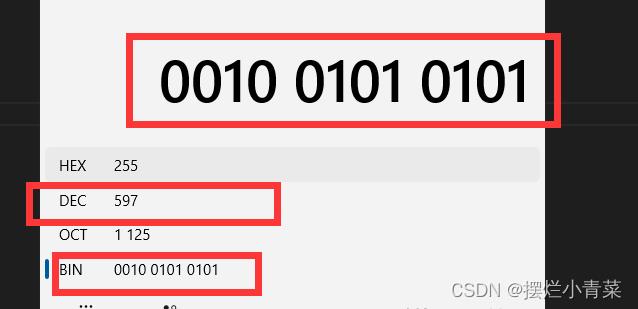
#define EXCHANGEBIN(NUM) (((NUM)&(0x55555555))<<1)|(((NUM)&(0xaaaaaaaa))>>1)算法解析:
#include <stdio.h> #define EXCHANGEBIN(NUM) (((NUM)&(0x55555555))<<1)|(((NUM)&(0xaaaaaaaa))>>1) //宏测试 int main() int num = 426; //二进制补码为:0000 0000 0000 0000 0000 0001 1010 1010 printf("%u\\n",EXCHANGEBIN(num)); //转换后补码为:0000 0000 0000 0000 0000 0010 0101 0101 return 0;

5.#define使用的一些注意事项小结
- 带有副作用的表达式(会改变变量的值)作为宏的实参时要注意其在宏体中出现的次数带来的影响
- 宏体的定义中要多使用括号来清楚地表示运算的结合性
- 宏的参数可以是任意类型的变量甚至可以是类型名,使用时要注意合理的类型匹配
- 宏的文本替换机制会使代码的可维护性降低(被替换到源码文本中的宏体会与源码的上下文环境产生难以预料的相互作用),比较复杂的过程避免使用宏来封装。
- 宏体在预编译阶段被替换到源码文本中,代码执行调试时,用户看到的源码段和实际被调试的代码段有所差异
- 当预处理器搜索#define定义的符号的时候,字符串常量的内容并不被搜索
比如:
#define N 4 char arr[]="N"; //arr中的N不会被替换
6.宏与函数的比较
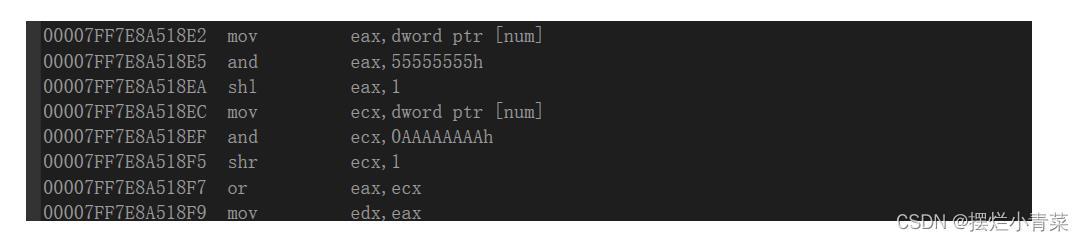
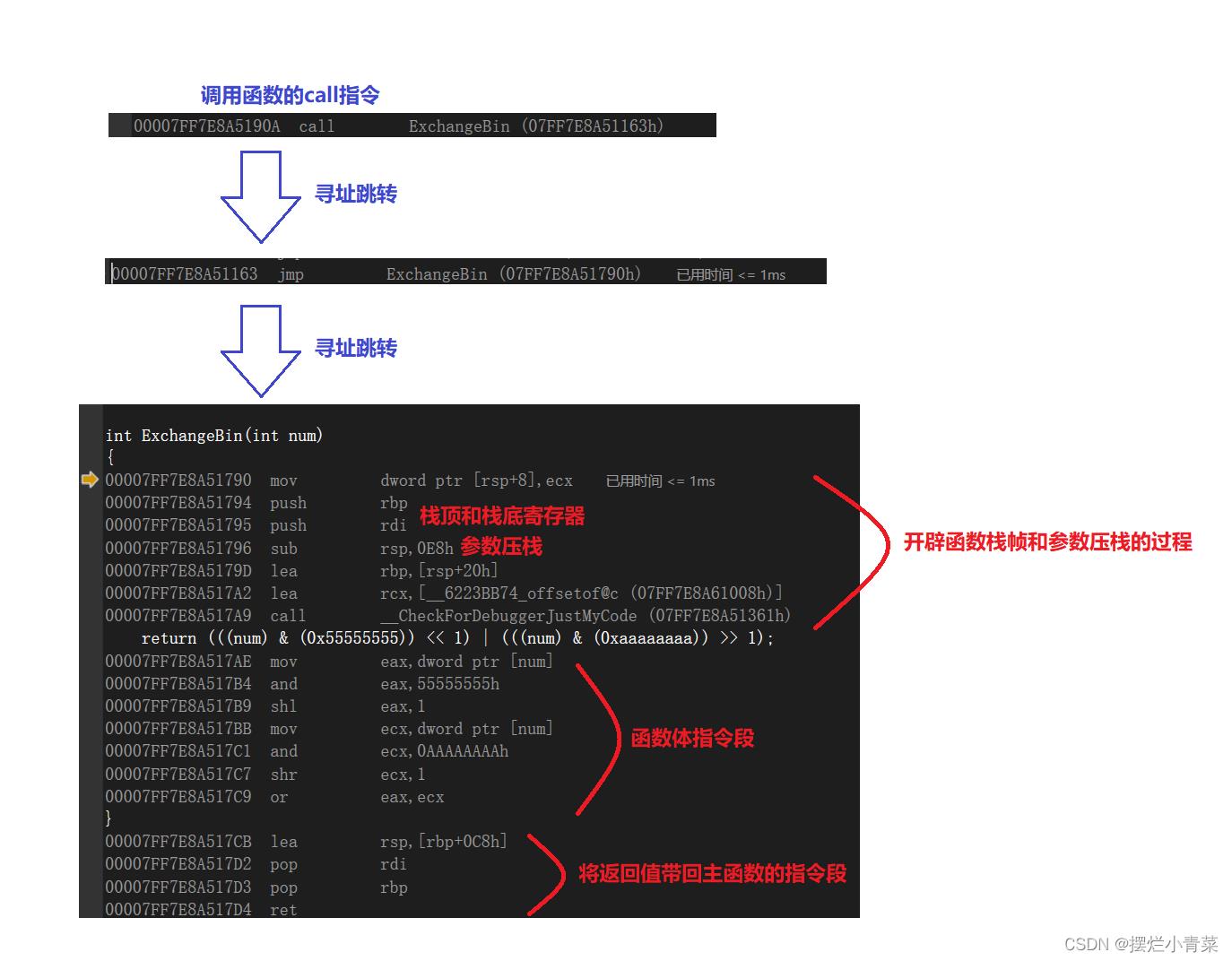
#define EXCHANGEBIN(NUM) (((NUM)&(0x55555555))<<1)|(((NUM)&(0xaaaaaaaa))>>1) int ExchangeBin(int num) return (((num)&(0x55555555))<<1)|(((num)&(0xaaaaaaaa))>>1); int main() int num = 426; EXCHANGEBIN(num); ExchangeBin(num); return 0;代码段中的宏和函数实现了相同的功能,但是实际上执行宏和执行函数的汇编指令会有比较大的差异。
执行EXCHANGEBIN(num)宏的汇编指令:
执行ExchangeBin(num)函数对的汇编指令:
- 可见实现相同的功能,执行宏的指令段比执行函数的指令段要简洁很多,因此对于一些简单且在程序中被频繁使用的表达式而言,使用宏来对其进行封装会让程序运行效率更高。
- 由于宏是文本替换,所以经过预处理后,宏可能会使源码的文本长度大幅增加,使程序运行时占用的内存更大,而函数不会有这样的问题,因为一个函数的函数体在内存的只读常量区中只会存储一份。
- 宏的参数没有类型限制(甚至可以是类型名),而函数的参数会有严格的类型检查,在这一点上函数更加安全
- 宏体难以进行逐语句调试(源文件的宏调用语句中无法看到展开的宏体),而函数可以进行逐语句调试
- 宏不能递归,函数可以递归
7.#undef
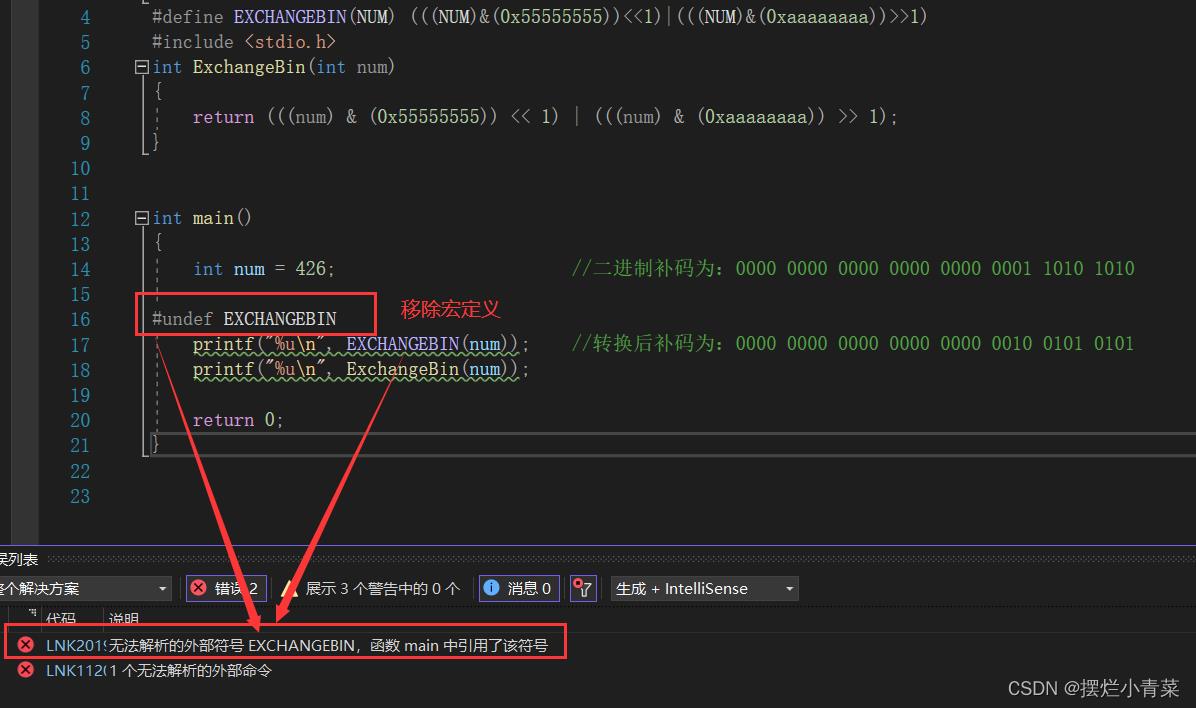
#undef指令用于移除一个宏定义
#undef NAME
附:关于#define的三个冷知识
- 使用 # ,可以把一个宏参数变成对应的字符串
int i = 10; #define PRINT(FORMAT, VALUE)\\ //宏体可以分行定义(用反斜杠加回车将宏体内容换行) printf("the value of " #VALUE "is "FORMAT "\\n", VALUE); int main() PRINT("%d", i+3); // #VALUE会使参数 i+3 变为对应的字符串"i+3"- ##可以把位于它两边的符号合成一个符号。
它允许宏定义从分离的文本片段创建标识符(标识符必须预先定义好)。#define ADD_TO_SUM(num, value) \\ sum##num += value; int main () int sum5 =10; ADD_TO_SUM(5, 10); //预处理将该语句替换为 sum5 += 10- gcc的命令行定义:
#include <stdio.h> int main() int array [ARRAY_SIZE]; return 0;我们可以在gcc的编译命令行中指定常量ARRAY_SIZE的值:
gcc -D ARRAY_SIZE=10 -E ./testproject/test.c -o test.i
三. 条件编译
常量表达式条件编译:
//单分支条件编译指令 #if 常量表达式 //代码段 #endif//多分支条件编译指令 #if 常量表达式 //代码段 #elif 常量表达式 //代码段 #else //代码段 #endif //#elif 可以类比 else if 来理解当常量表达式为真则对#if和#endif(或#elif,#else)之间的代码段执行编译,为假则编译器会自动屏蔽掉#if和#endif之间的代码段(或#elif,#else)(常量表达式由预处理器求值)
#define的条件编译
#ifdef symbol //代码段 #enif 如果symbol被#define定义了,则编译器会编译代码段,如果没有symbol没有被#define定义,则编译器不会编译代码段 #ifndef symbol //代码段 #endif 如果symbol没有被#define定义则编译器会编译代码段,如果symbol被#define定义了则编译器不会编译代码段
条件编译的嵌套 #ifdef OS_Unix #ifdef OPTION1 unix_version_option1(); #endif #ifdef OPTION2 unix_version_option2(); #endif #elifdef OS_MSDOS #ifdef OPTION2 msdos_version_option2(); #endif #endif条件编译在一些项目中以及语言标准库源码中很常见。
四.预处理之#include
#include的作用是将指定头文件中的内容"复制粘贴"到当前源文件中
1.#include<> 与 #include" "
- 本地文件包含指令
#include "filename"编译器查找方式:编译器会先在当前源文件所在路径下查找filename文件,如果该头文件未找到,编译器就会到标准库路径下查找filename文件。如果找不到就提示编译错误
库文件包含指令
#include <filename>编译器会直接去标准库路径下去查找filename文件,如果找不到就提示编译错误
根据具体情况选择对应的文件包含指令可以提高编译器的编译效率,并且可以在源码层面上令人更容易区分库文件和本地文件
2.头文件的重复包含问题
头文件在同一个源文件中的重复包含问题
一个复杂的项目工程中很容易出现这样的场景:
上面的场景中comm.h在test.c中重复被包含了两次,意味着comm.h中相同的内容会两次被"复制粘贴"到test.c中,这可能会导致程序链接错误(这中链接错误往往会折腾人半天)
- 在头文件中加上#pragma once指令可以避免该头文件被重复包含到同一个源文件中
#pragma once每个头文件中都加上#pragma once指令是良好的编程习惯
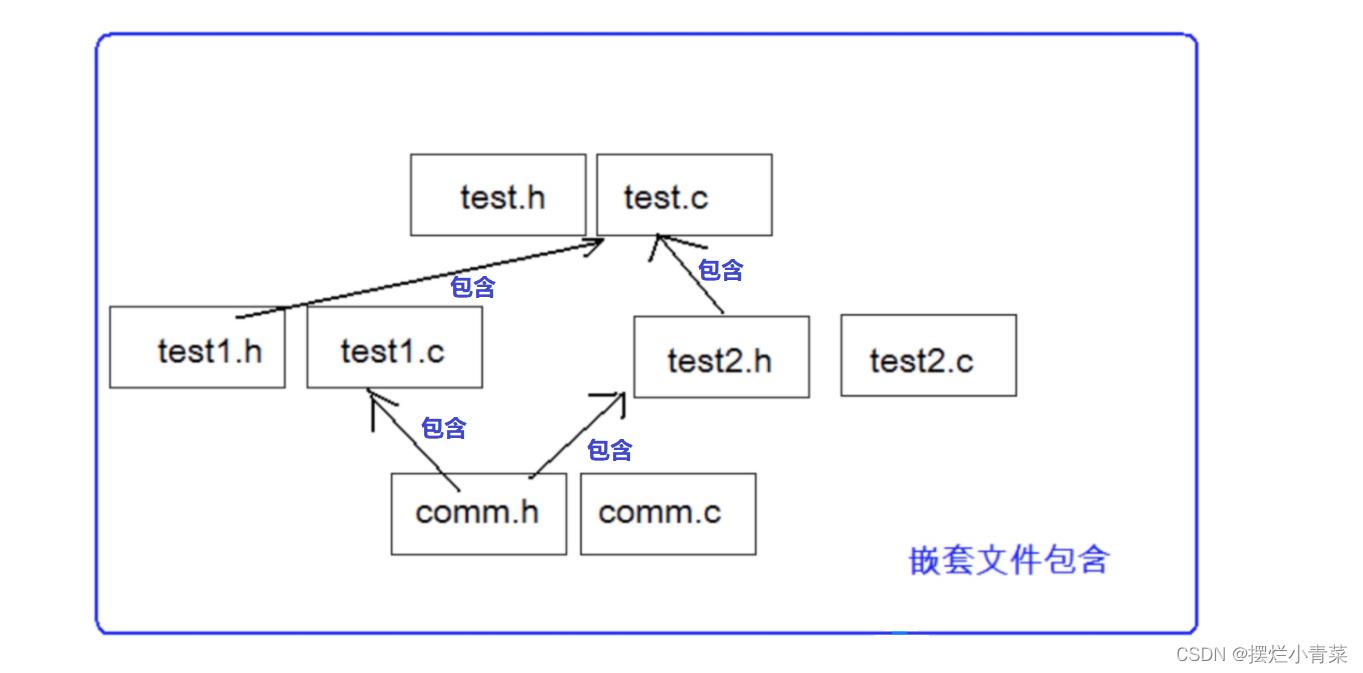
同一个头文件在多个源文件中的被包含问题
- 一个头文件往往会被多个源文件同时包含,因此头文件中要避免出现全局变量的定义和函数体的定义,不然相同的变量(或函数)的定义会在全局域中出现多次而导致链接错误。
- 全局标识名的声明和定义分离,声明统一放在头文件中,定义统一放在源文件中,这是必备的编程素养

以上是关于C/C++:预处理(下)的主要内容,如果未能解决你的问题,请参考以下文章