大数据技术架构(组件)26——Spark:Shuffle
Posted mylife512
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据技术架构(组件)26——Spark:Shuffle相关的知识,希望对你有一定的参考价值。
2.1.6、Shuffle
2.1.6.0 Shuffle Read And Write
MR框架中涉及到一个重要的流程就是shuffle,由于shuffle涉及到磁盘IO和网络IO,所以shuffle的性能直接影响着整个作业的性能。Spark其本质也是一种MR框架,所以也有自己的shuffle实现。但是和MR中的shuffle流程稍微有些不同(Spark相当于Mr来说其中一些环节是可以省略的),比如MR中的Shuffle过程是必须要有排序的,且不能省略掉,但Spark中的Shuffle是可以省略的;另对于MR的Shuffle中间结果是要落盘的,而对于Spark Shuffle来说,可以根据存储策略存储在内存或者磁盘中。
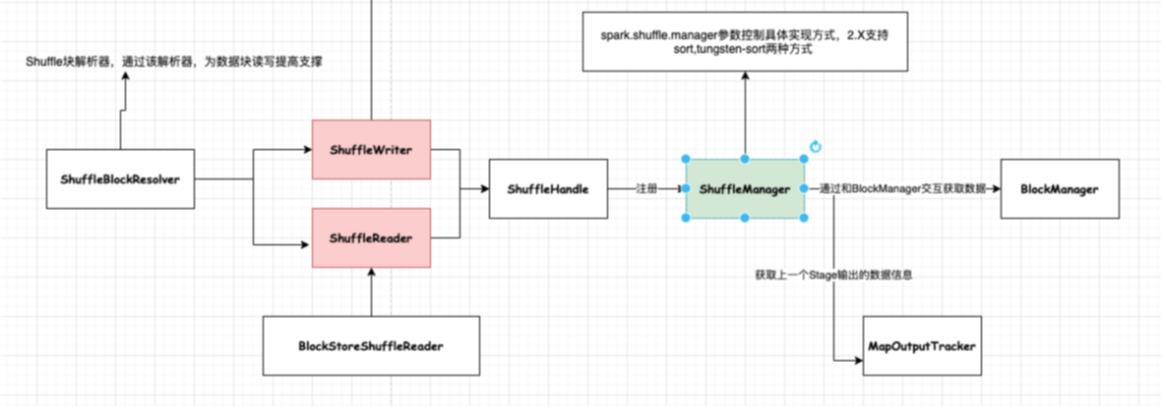
Shuffle阶段中涉及到一个很重要的插拔式接口ShuffleManager,该接口可以作为一个入口,可以获取用于数据读写处理句柄ShuffleHandle,然后通过ShuffleHandle获取特定的读写接口即ShuffleWriter和ShuffleReader,以及获取块数据信息解析接口ShuffleBlockResolver。
目前Spark提供了两种ShuffleManager:sort和tungsten-sort

2.1.6.0.1、Shuffle Writer
Shuffle写数据的时候,在内存中是有一个Buffer缓冲区,同时本地磁盘也有对应的文件(具体位置可以通过spark.local.dir配置);因此该部分内存中主要被两部分内容所占用:1、存储Buffer数据;2、管理文件句柄。
如果shuffle过程中写入大量的文件,那么内存消耗也是一种压力,很容易产生OOM,频繁GC。
扩展:关于GC引发的shuffle fetch不到文件
有那么一种现象:即Reduce端的Stage去拉取上一个Stage的产生结果,但是因为找不到文件而抛出异常,其实并不是不存在,而是可能由于正在进行GC操作而未回应。
Spark2.X提供了三种Shuffle Writer模式:
2.1.6.0.1.1 BypassMergeSortShuffleWriter
该种模式是带了Hash风格的基于Sort的Shuffle机制,为每个reduce端生成一个文件。
适用场景:该种模式适用于分区数比较少的场景下,可以作为一种优化方案。
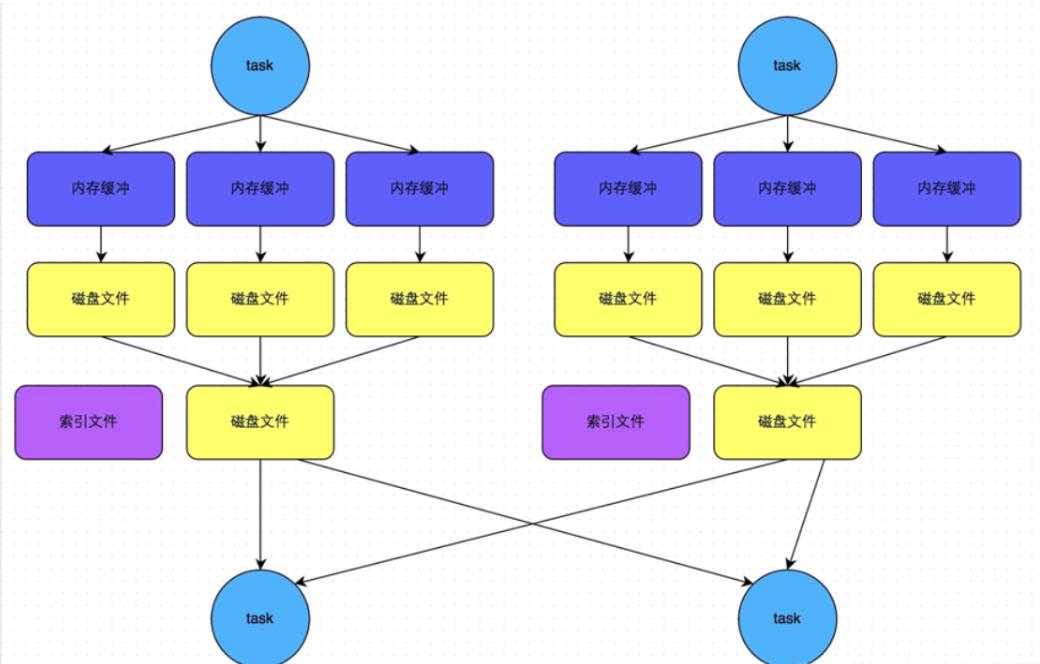
上图的合并机制即就是BypassMergeSortShuffleWriter的部分流程。
写入文件命名:

该种模式的缺点:
1、不能使用aggregator,以32条记录批次直接写入的(通过spark.shuffle.file.buffer参数配置),所以会造成后续的网络IO开销比较大。
2、每个分区都会生成一个对应的磁盘写入器DiskBlockObjectWriter,先对每个reduce产生的数据写入临时文件中,最后合并输出一个文件。所以分区数不能设置过大,避免同时打开过多实例加大内存开销
3、不能指定Ordering,也就是说该种模式的排序是采用分区Id进行的,分区内的数据是不保证有序的。
2.1.6.0.1.2 SortShuffleWriter
流程:
1、Sort Shuffle Writer模式首先会实例化一个ExternalSorter,根据是否在map端聚合来决定是否在实例化的时候传入aggregator和Ordering变量。

2、把所有的记录放到外部排序器中ExternalSorter(会调用Sorter.insertAll和writePartitionedFile两个方法)
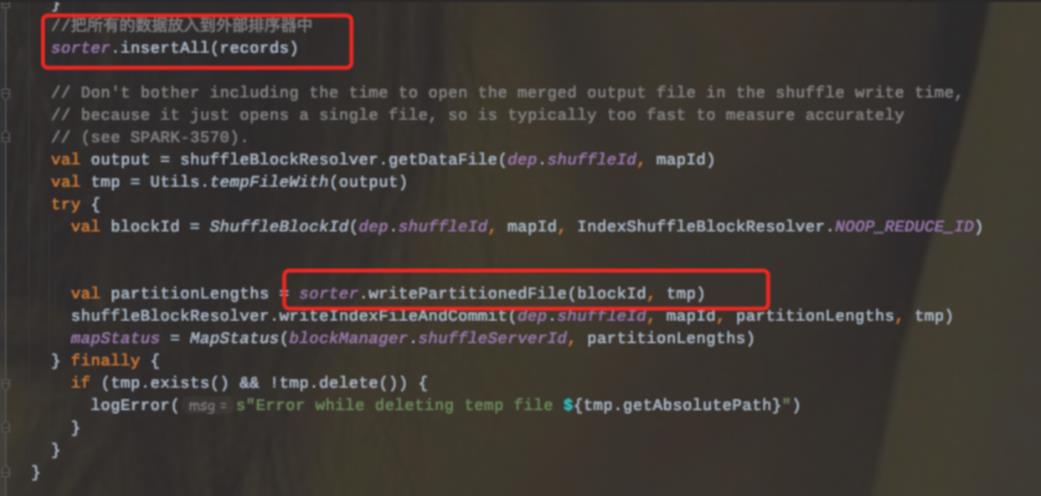
3、Sorter.insertAll内部会根据是否进行合并采用不同的存储。如果需要进行合并,那么就会使用AppendOnlyMap在内存中进行合并;如果不需要进行合并,那么就会存放到Buffer中。
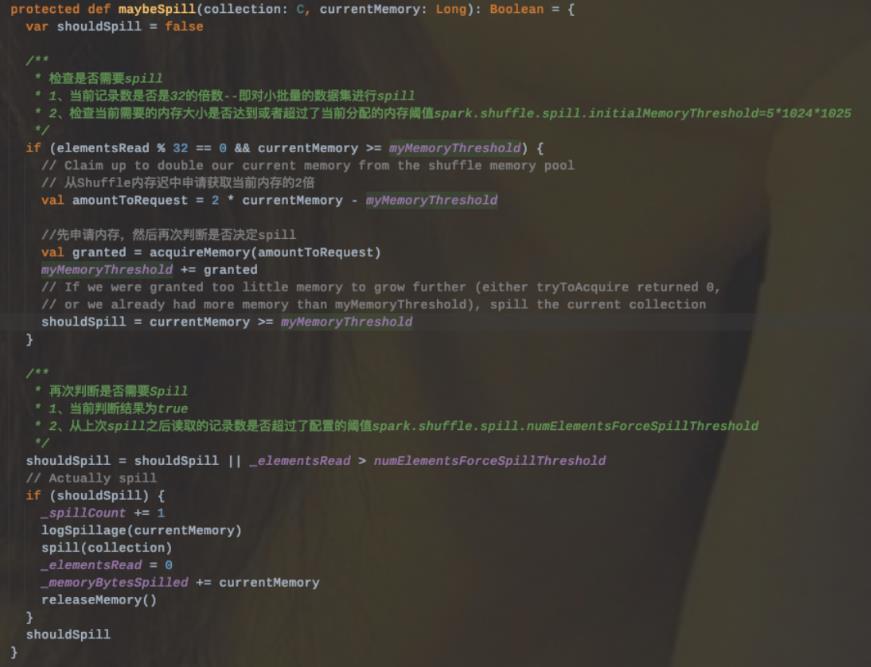
3.1、无论是否进行合并,都会进行的是否溢写检查(即调用maybeSpillCollection检查是否溢写到磁盘),其底层内部调用的是maybeSpill方法。
4.其溢写策略:
4.1、首先检查是否需要spill;判断依据为:
4.1.1、当前记录数是否是32的倍数--即对小批量的数据集进行spill
4.1.2、检查当前需要的内存大小是否达到或者超过了当前分配的内存阈值spark.shuffle.spill.initialMemoryThreshold=510241025
4.2、如果以上条件都满足的话,那么会向Shuffle内存池申请当前2倍内存,然后再次判断是否需要spill。
4.3、再次判断的依据是:
4.3.1、当前判断结果为true|从上次spill之后读取的记录数是否超过了配置的阈值spark.shuffle.spill.numElementsForceSpillThreshold
缺点:
1、内存中的数据是以反序列化的形式存储的,这样会增加内存的开销,同时也意味着增加GC负载。
2、存储到磁盘的时候会对数据进行序列化,而反序列化和序列化操作会增加CPU的开销。
2.1.6.0.1.3 UnsafeShuffleWriter
和Sort Shuffle Writer基本一致,主要不同在于使用的是序列化排序模式。
上述中说到在spark.shuffle.manager设置为sort时,内部会自动选择具体的实现机制。
Tungsten-Sort Shuffle内部的写入器是使用的UnsafeShuffleWriter,该类在构建的时候会传入一个context.taskMemoryManager(),构建一个TaskMemoryManager实例,主要负责管理分配task内存。
该写入器有以下三个关键步骤:
1、通过循环遍历将记录写入到外部排序器中
2、closeAndWriteOutput方法写数据文件和索引文件,在写的过程中会先合并外部排序器在插入过程中生成的中间文件。该方法主要有三个步骤:
2.1、触发外部排序器,获取spill信息
2.2、合并Spill中间文件,生成数据文件,并返回各个分区对应的数据量信息。
2.3、根据各个分区的数据量信息生成数据文件对应的索引文件。
3、sorter.cleanupresources最后释放外部排序器的资源。
2.1.6.0.2、Shuffle Read
2.1.6.1、Hash Shuffle(Spark2.X abandoned)
早期引入Hash Shuffle主要是为了避免不必要的排序(MR中的Shuffle过程sort是必经的一个过程)。
在Spark1.1之前,每个Mapper阶段的Task都会为每个Reduce阶段的Task生成一个文件,那么也就会生成M*R个中间文件(M表示Mapper阶段的Task个数,R表示Reduce阶段的Task个数)。
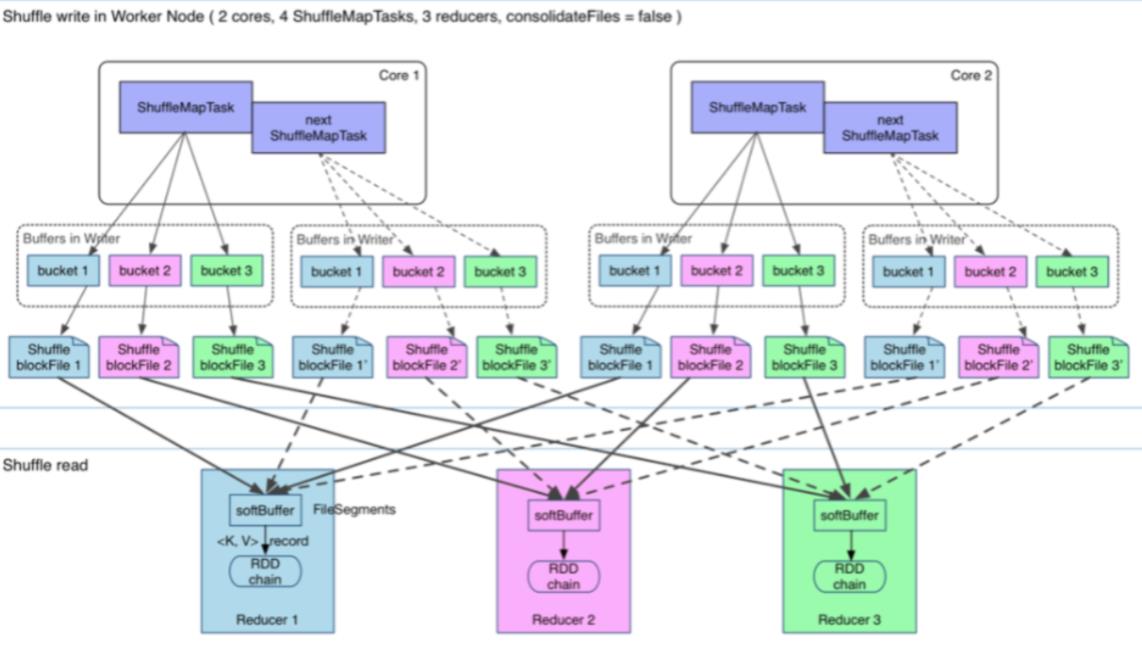
后来为了缓解这种大量文件产生的问题,基于Hash Shuffle实现又引入了Shuffle Consolidate机制,也就是将中间文件进行合并。通过配置spark.shuffle.consolidateFiles=true减少中间文件生成的个数。该种机制把中间文件生成方式调整为每个执行单元(类似于Slot)为每个Reduce阶段的Task生成一个文件,那么最后生成的文件个数为E(C/T)R;
E:表示Executors个数
C:表示Mapper阶段可用Cores个数
T:表示Mapper阶段Task分配的Cores个数。
从抽象的角度来说,Consolidate Shuffle是通过ShuffleFileGroup的概念,即每个ShuffleFileGroup对应一批Shuffle文件,文件数量和Reducer端的Task个数一样。同个Core上执行的MapTask任务会往这一批Shuffle文件里写,这样可以进行复用,在一定程度上对多个task进行了合并。

2.1.6.2、Sort Shuffle
2.1.6.2.1、引入背景
基于Hash的Shuffle实现方式,生成的中间结果文件个数取决于Reduce阶段的Task个数,即Reduce端的并行度。虽然引入了consolidate机制,但是仍然解决不了大量文件生成的问题。
因此在Spark1.1中又引入了基于Sort的Shuffle方式,在2.X中废弃掉了hash shuffle。也就是说现在1.1之后所有的版本中默认都是Sort Shuffle(早期版本其实可以调整ShuffleManager为hash方式)。
为什么说Sort Shuffle解决了Hash Shuffle生成大量文件的问题?那么最后又是会生成多少个文件呢?
解答:基于sort shuffle的模式是将所有的数据写入到一个数据文件里,同时会生成一个索引文件。那么最终文件生成的个数变成了2M;
M表示Mapper阶段的Task个数,每个Mapper阶段的Task分别生成两个文件(1个数据文件、1个索引文件)
其中索引文件存储了数据文件通过Partitioner的分类的信息,所以下一个阶段Stage中的Task就是根据这个index文件获取自己所需要的上一个Stage中ShuffleMapTask产生的数据。而ShuffleMapTask产生数据写入是顺序写的(根据自身的Key写进去的,同时也是按照Partition写进去的)
2.1.6.2.2、原理
Sort Shuffle主要是在Mapper阶段,在Mapper阶段,会进行两次排序(第一次是根据PartitionId进行排序;第二次是根据数据本身的Key进行排序,当然第二次排序除非调用了带排序的方法,在方法里指定了Key值的Ordering实例,这个时候才会对分区内的数据进行排序)。
sort shuffle其核心借助于ExternalSorter首先会把每个ShuffleMapTask的输出排序内存中,当超过内存容纳的时候,会spill到一个文件中(FileSegmentGroup),同时还会写一个索引文件用来区分下一个阶段Reduce Task不同的内容来告诉下游Stage的并行任务哪些数据是属于自己的。

2.1.6.2.3、缺点
1、sort shuffle产生的文件数量为2M,那么这个文件数量的大小也是取决于M的个数,也就是Map端的TASK个数。如果task数过多,那么这个时候Reduce端需要大量记录并进行反序列化,同样会造成OOM,甚至full GC
2、Mapper端强制排序(和MR中的Shuffle是一样的)
3、如果分区内也需要进行排序,那么就都要在mapper端和reducer端进行排序。
4、sort shuffle是基于记录本身进行排序的,会有一定的性能消耗。
2.1.6.3、Tungsten Sort Shuffle
tungen-sort shuffle对排序算法进行了改造优化了排序的速度。其优化(从避免反序列化的数据量过大消耗内存方面考虑;借助于Tungsten内存管理模型,可以直接处理序列化的数据,同时也降低了CPU开销。
使用该模式需要具备以下几个条件:
1、shuffle依赖中不存在聚合操作或者没有对输出排序的要求
2、shuffle的序列化器支持序列化值的重定位(目前仅支持KryoSerializer以及SparkSQL子框架自定义的序列化器)
3、Shuffle过程重化工的输出分区个数少于16777216个。
所以使用基于Tungsten-sort的Shuffle实现机制条件还是比较苛刻的。
2.1.6.4、Shuffle & Storage (TODO)
以上是关于大数据技术架构(组件)26——Spark:Shuffle的主要内容,如果未能解决你的问题,请参考以下文章