CLIP-Q:先剪枝后量化的压缩框架
Posted Yan_Joy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CLIP-Q:先剪枝后量化的压缩框架相关的知识,希望对你有一定的参考价值。
前段时间CVPR2018结束了,搜索quantization、compression关键词,得到的论文并不多,有空就看了几篇。CLIP-Q这个方法看起来挺简单的,而且得到的效果也不错,就简单解读一下。
论文CLIP-Q: Deep Network Compression Learning by In-Parallel Pruning-Quantization,CVPR2018。
In-parallel pruning-quantization
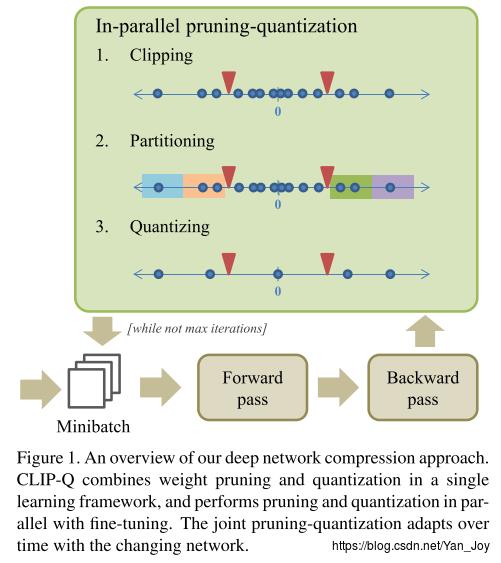
- Clipping. 设置两个截止点标量 c− c − 和 c+ c + ,用超参数 p p 来确定,使正参数中的参数小于 c+ c + ,同时使负参数中 (p×100)% ( p × 100 ) % 的参数大于 c− c − 。位于 c− c − 和 c+ c + 之间的参数置为0。注意的是这种减除是暂时的,在下个周期中,用这个规则作用于更新后的参数,之前被剪枝的连接可能会重新出现。
- Partitioning。第二步把未被剪掉的参数分到不同的量化区间。可以被可视化到一个一维数轴上。通过给定的权重位宽 b b ,将数轴划分为个区间,再加上从 c− c − 到 c+ c + 的0区间。文中采用了Deep compression中linear (uniform) partitioning方式。
- Quantizing.量化值是由量化区间中的值平均得来的,并在下次的前向传播中赋值。和Clipping一样,值只是暂时的量化,可能在后面的过程进行更改。
具体用以下一个小实例做示范:
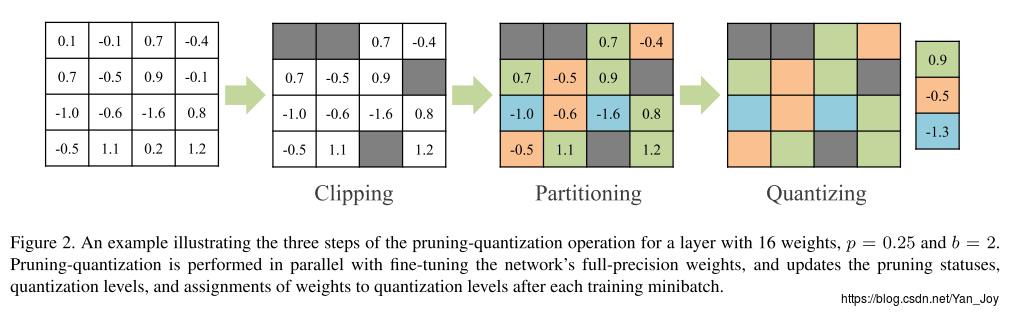
首先设置 p=0.25,b=2 p = 0.25 , b = 2
- 根据设置的阈值减去不需要的小权重;
- 剩下的12个权重分为 22−1=3 2 2 − 1 = 3 类;
- 计算每一类的均值,作为量化值。
训练中量化值和全精度值都会被跟踪,其中全精度值用于参数更新和反向传播,量化值用于前向计算。训练完成之后只需要保留量化值即可。整体算法的伪代码如图:

超参数预测
算法中的超参数有 p,b p , b 两个,文中采用贝叶斯优化方法确定最优参数 θi=(pi,bi) θ i = ( p i , b i ) :
minθϵ(θ)−λ⋅ci(θ) min θ ϵ ( θ ) − λ ⋅ c i ( θ )
对于第 i i 层,为Top1误差, ci(θ) c i ( θ ) 表示压缩效果,经由:
ci(θ)=(mi−si(θ))/∑imi c i ( θ ) = ( m i − s i ( θ ) ) / ∑ i m i
计算得来。其中 mi m i 是 i i 层需要以非压缩形式存储的权重所需的比特数,是使用稀疏编码方案在使用 θ θ 进行剪枝量化之后来存储所需的比特数。后面使用高斯过程进行建模,有些复杂,不再进行讲解。
总结
其实这个方法很容易想到,最大的创新我觉得也是他超参数的自动设置了。由于每个mini-batch之后继续更新,所以是一种不固定的量化剪枝,因而给定的 b,p b , p 参数也随着网络不断更新。结果在GoogLeNet 上有10x压缩,ResNet-50有15x,还是不错的。但实际上真的需要用超参数的自动设置吗?从目前自己的实验上来看感觉也没有那么重要,损失可能也就在1%以内。
以上是关于CLIP-Q:先剪枝后量化的压缩框架的主要内容,如果未能解决你的问题,请参考以下文章