Zookeeper应用场景
Posted 拐柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper应用场景相关的知识,希望对你有一定的参考价值。
Zookeeper(四)应用场景
Zookeeper应用场景
ZooKeeper是⼀个典型的发布/订阅模式的分布式数据管理与协调框架,我们可以使⽤它来进⾏分布式 数据的发布与订阅。另⼀⽅⾯,通过对ZooKeeper中丰富的数据节点类型进⾏交叉使⽤,配合Watcher 事件通知机制,可以⾮常⽅便地构建⼀系列分布式应⽤中都会涉及的核⼼功能,如数据发布/订阅、命名 服务、集群管理、Master选举、分布式锁和分布式队列等。
数据发布/订阅
数据发布/订阅(Publish/Subscribe)系统,即所谓的配置中⼼,顾名思义就是发布者将数据发布到ZooKeeper的⼀个或⼀系列节点上,供订阅者进⾏数据订阅,进⽽达到动态获取数据的⽬的,实现配置信息的集中式管理和数据的动态更新。
发布/订阅系统⼀般有两种设计模式,分别是推(Push)模式和拉(Pull)模式。在推模式中,服务端 主动将数据更新发送给所有订阅的客户端;⽽拉模式则是由客户端主动发起请求来获取最新数据,通常 客户端都采⽤定时进⾏轮询拉取的⽅式。
ZooKeeper 采⽤的是推拉相结合的⽅式:客户端向服务端注册⾃⼰需要关注的节点,⼀旦该节点的数据发⽣变更,那么服务端就会向相应的客户端发送Watcher事件通知,客户端接收到这个消息通知之后, 需要主动到服务端获取最新的数据。
如果将配置信息存放到ZooKeeper上进⾏集中管理,那么通常情况下,应⽤在启动的时候都会主动到ZooKeeper服务端上进⾏⼀次配置信息的获取,同时,在指定节点上注册⼀个Watcher监听,这样⼀ 来,但凡配置信息发⽣变更,服务端都会实时通知到所有订阅的客户端,从⽽达到实时获取最新配置信 息的⽬的。
命名服务
命名服务(Name Service)也是分布式系统中⽐较常⻅的⼀类场景,是分布式系统最基本的公共服务之
⼀。在分布式系统中,被命名的实体通常可以是集群中的机器、提供的服务地址或远程对象等——这些 我们都可以统称它们为名字(Name),其中较为常⻅的就是⼀些分布式服务框架(如RPC、RMI)中 的服务地址列表,通过使⽤命名服务,客户端应⽤能够根据指定名字来获取资源的实体、服务地址和提 供者的信息等。
ZooKeeper 提供的命名服务功能能够帮助应⽤系统通过⼀个资源引⽤的⽅式来实现对资源的定位与使
⽤。另外,⼴义上命名服务的资源定位都不是真正意义的实体资源——在分布式环境中,上层应⽤仅仅 需要⼀个全局唯⼀的名字,类似于数据库中的唯⼀主键。
所以接下来。我们来看看如何使⽤ZooKeeper来实现⼀套分布式全局唯⼀ID的分配机制
所谓ID,就是⼀个能够唯⼀标识某个对象的标识符。在我们熟悉的关系型数据库中,各个表都需要⼀个 主键来唯⼀标识每条数据库记录,这个主键就是这样的唯⼀ID。在过去的单库单表型系统中,通常可以 使⽤数据库字段⾃带的auto_increment属性来⾃动为每条数据库记录⽣成⼀个唯⼀的ID,数据库会保证
⽣成的这个ID在全局唯⼀。但是随着数据库数据规模的不断增⼤,分库分表随之出现,⽽auto_increment属性仅能针对单⼀表中的记录⾃动⽣成ID,因此在这种情况下,就⽆法再依靠数据库的auto_increment属性来唯⼀标识⼀条记录了。于是,我们必须寻求⼀种能够在分布式环境下⽣成全局唯
⼀ID的⽅法。
说明,对于⼀个任务列表的主键,使⽤ZooKeeper⽣成唯⼀ID的基本步骤:
1.所有客户端都会根据⾃⼰的任务类型,在指定类型的任务下⾯通过调⽤create()接⼝来创建⼀个顺序节点,例如创建“job-”节点。
2.节点创建完毕后,create()接⼝会返回⼀个完整的节点名,例如“job-0000000003”。
3.客户端拿到这个返回值后,拼接上 type 类型,例如“type2-job-0000000003”,这就可以作为⼀个全局唯⼀的ID了。
在ZooKeeper中,每⼀个数据节点都能够维护⼀份⼦节点的顺序顺列,当客户端对其创建⼀个顺序⼦节点的时候 ZooKeeper 会⾃动以后缀的形式在其⼦节点上添加⼀个序号,在这个场景中就是利⽤了ZooKeeper的这个特性。
集群管理
随着分布式系统规模的⽇益扩⼤,集群中的机器规模也随之变⼤,那如何更好地进⾏集群管理也显得越 来越重要了。所谓集群管理,包括集群监控与集群控制两⼤块,前者侧重对集群运⾏时状态的收集,后 者则是对集群进⾏操作与控制。
在⽇常开发和运维过程中,我们经常会有类似于如下的需求:
- 如何快速的统计出当前⽣产环境下⼀共有多少台机器
- 如何快速的获取到机器上下线的情况
- 如何实时监控集群中每台主机的运⾏时状态
Zookeeper的两⼤特性:
1.客户端如果对Zookeeper的数据节点注册Watcher监听,那么当该数据节点的内容或是其⼦节点列表发⽣变更时,Zookeeper服务器就会向订阅的客户端发送变更通知。
2.对在Zookeeper上创建的临时节点,⼀旦客户端与服务器之间的会话失效,那么临时节点也会被
⾃动删除
利⽤其两⼤特性,可以实现集群机器存活监控系统,若监控系统在/clusterServers节点上注册⼀个Watcher监听,那么但凡进⾏动态添加机器的操作,就会在/clusterServers节点下创建⼀个临时节 点:/clusterServers/[Hostname],这样,监控系统就能够实时监测机器的变动情况。
Master选举
Master选举是⼀个在分布式系统中⾮常常⻅的应⽤场景。分布式最核⼼的特性就是能够将具有独⽴计算能⼒的系统单元部署在不同的机器上,构成⼀个完整的分布式系统。⽽与此同时,实际场景中往往也需 要在这些分布在不同机器上的独⽴系统单元中选出⼀个所谓的“⽼⼤”,在计算机中,我们称之为 Master。
在分布式系统中,Master往往⽤来协调集群中其他系统单元,具有对分布式系统状态变更的决定权。例如,在⼀些读写分离的应⽤场景中,客户端的写请求往往是由 Master来处理的;⽽在另⼀些场景中, Master则常常负责处理⼀些复杂的逻辑,并将处理结果同步给集群中其他系统单元。Master选举可以 说是ZooKeeper最典型的应⽤场景了,接下来,我们就结合“⼀种海量数据处理与共享模型”这个具体例
⼦来看看 ZooKeeper在集群Master选举中的应⽤场景。
在分布式环境中,经常会碰到这样的应⽤场景:集群中的所有系统单元需要对前端业务提供数据,⽐如
⼀个商品 ID,或者是⼀个⽹站轮播⼴告的⼴告 ID(通常出现在⼀些⼴告投放系统中)等,⽽这些商品ID或是⼴告ID往往需要从⼀系列的海量数据处理中计算得到——这通常是⼀个⾮常耗费 I/O 和 CPU资源的过程。鉴于该计算过程的复杂性,如果让集群中的所有机器都执⾏这个计算逻辑的话,那么将耗费⾮ 常多的资源。⼀种⽐较好的⽅法就是只让集群中的部分,甚⾄只让其中的⼀台机器去处理数据计算,⼀ 旦计算出数据结果,就可以共享给整个集群中的其他所有客户端机器,这样可以⼤⼤减少重复劳动,提 升性能。
分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的⼀种⽅式。如果不同的系统或是同⼀个系统的不同 主机之间共享了⼀个或⼀组资源,那么访问这些资源的时候,往往需要通过⼀些互斥⼿段来防⽌彼此之 间的⼲扰,以保证⼀致性,在这种情况下,就需要使⽤分布式锁了。
排他锁
排他锁(Exclusive Locks,简称 X 锁),⼜称为写锁或独占锁,是⼀种基本的锁类型。如果事务 T1对数据对象 O1加上了排他锁,那么在整个加锁期间,只允许事务 T1对 O1进⾏读取和更新操作,其他任何事务都不能再对这个数据对象进⾏任何类型的操作——直到T1释放了排他锁
从上⾯讲解的排他锁的基本概念中,我们可以看到,排他锁的核⼼是如何保证当前有且仅有⼀个事务获 得锁,并且锁被释放后,所有正在等待获取锁的事务都能够被通知到。
下⾯我们就来看看如何借助ZooKeeper实现排他锁:
1、定义锁
在通常的Java开发编程中,有两种常⻅的⽅式可以⽤来定义锁,分别是synchronized机制和JDK5提供的ReentrantLock。然⽽,在ZooKeeper中,没有类似于这样的API可以直接使⽤,⽽是通过 ZooKeeper 上的数据节点来表示⼀个锁,例如/exclusive_lock/lock节点就可以被定义为⼀个锁,如图:
2、获取锁
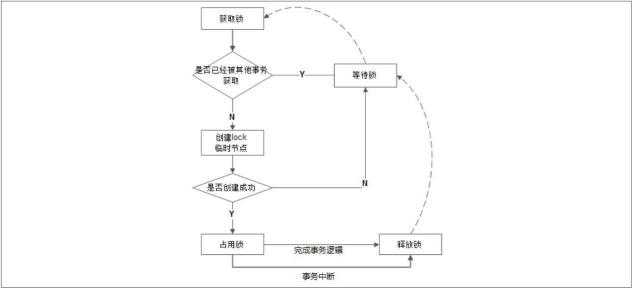
在需要获取排他锁时,所有的客户端都会试图通过调⽤ create()接⼝,在/exclusive_lock节点下创建临时⼦节点/exclusive_lock/lock。在前⾯,我们也介绍了,ZooKeeper 会保证在所有的客户端中,最终只有⼀个客户端能够创建成功,那么就可以认为该客户端获取了锁。同时,所有没有获取到锁的客户 端就需要到/exclusive_lock 节点上注册⼀个⼦节点变更的Watcher监听,以便实时监听到lock节点的变更情况
3、释放锁
在“定义锁”部分,我们已经提到,/exclusive_lock/lock 是⼀个临时节点,因此在以下两种情况下,都有可能释放锁。当前获取锁的客户端机器发⽣宕机,那么ZooKeeper上的这个临时节点就会被移除。 · 正常执⾏完业务逻辑后,客户端就会主动将⾃⼰创建的临时节点删除。 ⽆论在什么情况下移除了lock节点,ZooKeeper都会通知所有在/exclusive_lock节点上注册了⼦节点变更Watcher监听的客户端。这些客户端在接收到通知后,再次重新发起分布式锁获取,即重复“获取锁”过程。整个排他锁的获取和释放 流程,
共享锁
共享锁(Shared Locks,简称S锁),⼜称为读锁,同样是⼀种基本的锁类型。
如果事务T1对数据对象O1加上了共享锁,那么当前事务只能对O1进⾏读取操作,其他事务也只能对这个数据对象加共享锁——直到该数据对象上的所有共享锁都被释放。
共享锁和排他锁最根本的区别在于,加上排他锁后,数据对象只对⼀个事务可⻅,⽽加上共享锁后,数 据对所有事务都可⻅。
1、定义锁
和排他锁⼀样,同样是通过 ZooKeeper 上的数据节点来表示⼀个锁,是⼀个类似于
“/shared_lock/[Hostname]-请求类型-序号”的临时顺序节点,例如/shared_lock/host1-R- 0000000001,那么,这个节点就代表了⼀个共享锁

2、获取锁
在需要获取共享锁时,所有客户端都会到/shared_lock 这个节点下⾯创建⼀个临时顺序节点,如果当前是读请求,那么就创建例如/shared_lock/host1-R-0000000001的节点;如果是写请求,那么就创建例 如/shared_lock/host2-W-0000000002的节点
判断读写顺序
通过Zookeeper来确定分布式读写顺序,⼤致分为四步
- 创建完节点后,获取/shared_lock节点下所有⼦节点,并对该节点变更注册监听。
- 确定⾃⼰的节点序号在所有⼦节点中的顺序。
- 对于读请求:若没有⽐⾃⼰序号⼩的⼦节点或所有⽐⾃⼰序号⼩的⼦节点都是读请求,那么表明⾃⼰已经成功获取到共享锁,同时开始执⾏读取逻辑,若有写请求,则需要等待。对于写请求:若⾃⼰不是序号最⼩的⼦节点,那么需要等待。
- 接收到Watcher通知后,重复步骤1
3、释放锁
其释放锁的流程与独占锁⼀致
分布式队列
分布式队列可以简单分为两⼤类:⼀种是常规的FIFO先⼊先出队列模型,还有⼀种是 等待队列元素聚集后统⼀安排处理执⾏的Barrier模型
FIFO先⼊先出
FIFO(First Input First Output,先⼊先出), FIFO 队列是⼀种⾮常典型且应⽤⼴泛的按序执⾏的队列模型:先进⼊队列的请求操作先完成后,才会开始处理后⾯的请求。
使⽤ZooKeeper实现FIFO队列,和之前提到的共享锁的实现⾮常类似。FIFO队列就类似于⼀个全写的共享锁模型,⼤体的设计思路其实⾮常简单:所有客户端都会到/queue_fifo 这个节点下⾯创建⼀个临时顺序节点
创建完节点后,根据如下4个步骤来确定执⾏顺序。
1.通过调⽤getChildren接⼝来获取/queue_fifo节点的所有⼦节点,即获取队列中所有的元素。
2.确定⾃⼰的节点序号在所有⼦节点中的顺序。
3.如果⾃⼰的序号不是最⼩,那么需要等待,同时向⽐⾃⼰序号⼩的最后⼀个节点注册Watcher监听。
4.接收到Watcher通知后,重复步骤1。
Barrier:分布式屏障
Barrier原意是指障碍物、屏障,⽽在分布式系统中,特指系统之间的⼀个协调条件,规定了⼀个队列的元素必须都集聚后才能统⼀进⾏安排,否则⼀直等待。这往往出现在那些⼤规模分布式并⾏计算的应⽤ 场景上:最终的合并计算需要基于很多并⾏计算的⼦结果来进⾏。这些队列其实是在 FIFO 队列的基础上进⾏了增强,⼤致的设计思想如下:开始时,/queue_barrier 节点是⼀个已经存在的默认节点,并且将其节点的数据内容赋值为⼀个数字n来代表Barrier值,例如n=10表示只有当/queue_barrier节点下的
⼦节点个数达到10后,才会打开Barrier。之后,所有的客户端都会到/queue_barrie节点下创建⼀个临时节点
创建完节点后,按照如下步骤执⾏。
1.通过调⽤getData接⼝获取/queue_barrier节点的数据内容:10。
2.通过调⽤getChildren接⼝获取/queue_barrier节点下的所有⼦节点,同时注册对⼦节点变更的
Watcher监听。
3.统计⼦节点的个数。
4.如果⼦节点个数还不⾜10个,那么需要等待。
5.接受到Wacher通知后,重复步骤2
以上是关于Zookeeper应用场景的主要内容,如果未能解决你的问题,请参考以下文章